Build a platform with KRM: Part 2 - How the Kubernetes resource model works
Megan O'Keefe
Staff Developer Advocate
This is part 2 in a multi-part series on building developer platforms with the Kubernetes Resource Model (KRM).
In Part 1, we learned about some characteristics of a good developer platform, from friendly abstractions to extensibility and security. This post will introduce the Kubernetes Resource Model (KRM), and will discuss how Kubernetes’ declarative, always-reconciling design can provide a stable base layer for a developer platform.
To understand how KRM works, let’s start by learning a bit about how Kubernetes works.
Kubernetes is an open-source container orchestration engine that allows you to treat multiple servers (Nodes) as one big computer, or Cluster. Kubernetes auto-schedules your containers to run on any Nodes that have room. All your Kubernetes Nodes get their instructions from the Kubernetes control plane. And the Kubernetes control plane gets its instructions from you, the user.
Google Kubernetes Engine (GKE) is Google’s managed Kubernetes product, and its architecture is shown below. In the blue “zonal control plane” area, you’ll see that the GKE control plane consists of several workloads— resource controllers, a scheduler, and backend storage — and all arrows point back to the API Server.
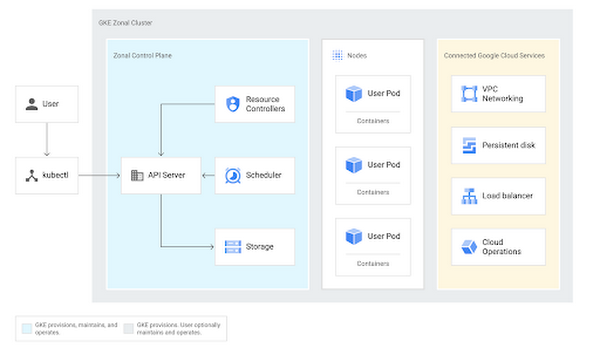
All about the API
The Kubernetes API Server is the central, most important part about a cluster because it’s the source of truth for both the desired and actual state of your cluster’s resources. Let’s unpack that by exploring how, exactly, to run containers on a Kubernetes cluster.
The way you configure most things in Kubernetes is with a declarative configuration file, expressed in a Kubernetes-readable format called the Kubernetes Resource Model (KRM). KRM is a way to state what you want to run on your cluster— it allows you to express your desired state.
KRM is often expressed as YAML. For example, if I want to run a “hello-world” web server on my cluster, I’ll write a YAML file representing a Kubernetes Deployment, set to run the hello-world container image.
Here, I’m writing down my desired state for the hello-world web server, providing the image I want to run on my Nodes, along with the number of replicas, or copies, of that container I want (3). You’ll also see other fields like “apiVersion,” “kind,” “metadata,” and “spec.” These are standard fields of all resources using the Kubernetes Resource Model, and we’ll see more of this later in the series.
After I define my desired state as a Kubernetes resource in a YAML file, I can “apply” the resource file to my cluster. There are several ways to do this. One easy way is with the kubectl command-line tool, which can send a local file to a remote Kubernetes API server. When you apply a KRM resource to a Kubernetes cluster using `kubectl apply -f <filename>`, that resource gets validated and then stored in the Kubernetes API Server’s backing store, etcd.
The life of a Kubernetes resource
Once a Kubernetes resource lands in etcd, things get interesting. The Kubernetes control plane sees the new desired state, and it gets working to have the running state match what’s in our Deployment YAML. The resource controllers, running in the Kubernetes control plane, poll the APIServer every few seconds, checking to see if they need to take any action. Kubernetes Deployments have their own resource controller, containing logic for what to do with a Deployment resource, like marking containers as “need to schedule these to Nodes!” That resource controller will then update your KRM resource in the API Server.
Then, the Pod scheduler, also polling the API Server, will see that there is a Deployment (hello-world) that has Pods (containers) in need of scheduling. And the scheduler will update your KRM resource such that each Pod has a specific Node assignment within the cluster.
From there, each of your cluster’s Nodes, also polling the API Server, will check if there are any Pods assigned specifically to them. If so, they will run the Pod’s containers as instructed.
Notice how all the Kubernetes components get their instructions from the desired state, stored in the APIServer. That desired state comes from you, and from any other external actor on the cluster, but it also comes from the Kubernetes cluster itself. By marking Pods as “to be scheduled,” the Deployment controller is requesting something from the scheduler; by assigning Pods to Nodes, the scheduler is requesting something from the Nodes. At no point in the life of a Kubernetes resource are there imperative calls (“run this” or “update that”)— everything is declarative (“this is a Pod. and it’s assigned to this Node”).
And this deployment process isn’t one-and-done. If you try to delete a running Pod from your cluster, the Deployment resource controller will notice, and it will schedule a new Pod to be created. Then, the Pod scheduler will assign it to a Node that has room for it, and so on. In this way, Kubernetes is working constantly to reconcile the desired state with the running state. This declarative, self-healing model applies to the rest of the Kubernetes APIs, too, from networking resources, to storage, to configuration, all of which have their own resource controllers.
Further, the Kubernetes API is extensible. Anyone can write a custom controller and resource definition for Kubernetes, even for resources that run outside the cluster entirely, like cloud-hosted databases. We’ll explore this more later on in the series.
KRM and GitOps: A dynamic duo
One benefit of defining your configuration as data in YAML files is that you can commit those resources to Github, and create CI/CD pipelines around them. This operating model — where configuration lives in Github, and automation deploys it — is called GitOps, a term coined by WeaveWorks.
In a GitOps model, rather than running “kubectl apply -f” on your resource files, you set up a Continuous Deployment pipeline to run that command on your behalf. This way, any new KRM committed to Git is automatically deployed as part of CI/CD, helping you avoid human error. The GitOps model can also help you audit exactly what you’re deploying to your clusters, and roll your configuration back to the “last working commit” during outages.
Let’s see GitOps and KRM in action with a sample application.
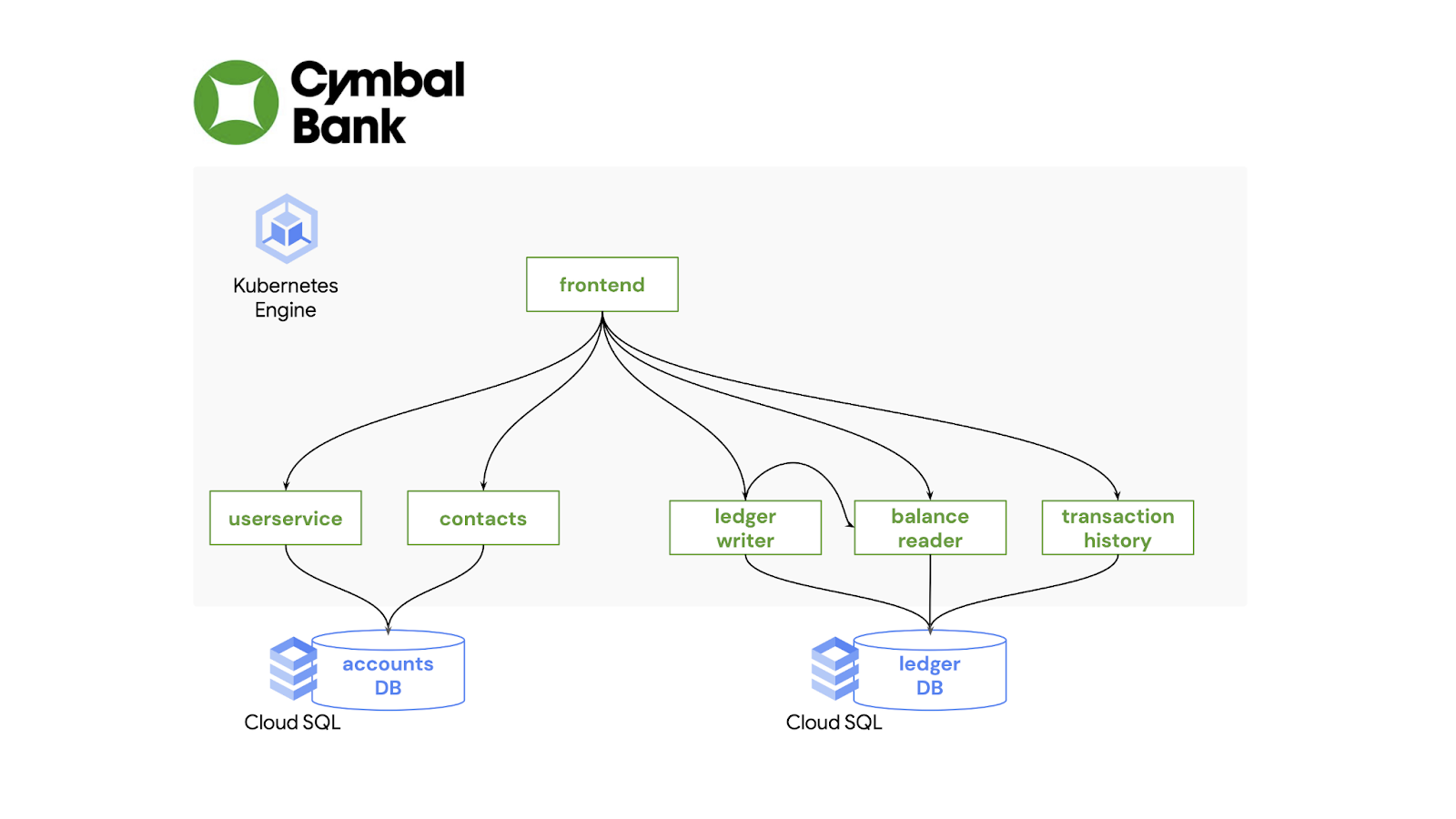
Cymbal Bank is a retail banking web application, written in Java and Python, that allows users to deposit funds into their accounts, and send money to their contacts. The application is backed by two SQL databases, both running in Google Cloud. Like the hello-world Deployment we just saw, each Cymbal Bank service — the frontend, and each of the five backends — has their own Kubernetes Deployment:
We also define other Kubernetes resources for each workload, like Services for routing between Pods in the cluster.
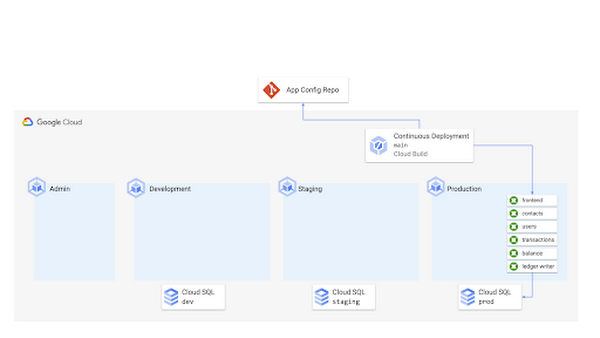
When we commit all these YAML files to a Git repository, we can set up a Google Cloud Build pipeline to auto-deploy these resources to GKE. This build is triggered on any Git push to the main branch of our configuration repo, and it simply runs “kubectl apply -f” on the production cluster, to deploy the latest resources to the Kubernetes API Server.
Once this pipeline runs, we can see the output of the kubectl apply -f commands on all the Cymbal Bank KRM resources.
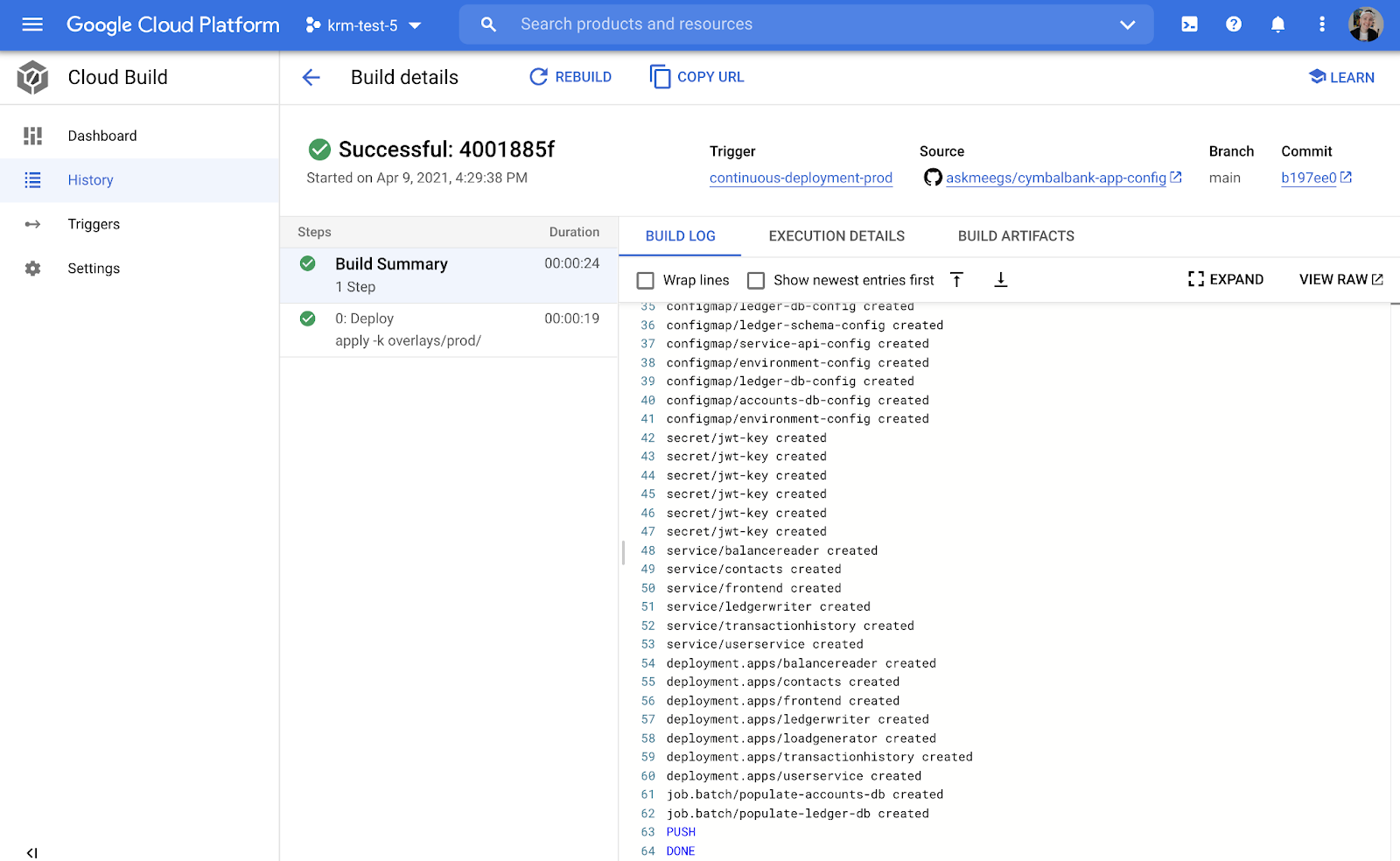
Now that the Continuous Deployment pipeline is complete, a new version of the Cymbal Bank app is now running in production!
Want to set this up yourself? Check out the Part 2 demo to use KRM to deploy Cymbal Bank to your GKE environment.
In the next post, we’ll build on this GitOps setup by taking on the role of a Cymbal Bank application developer, taking a new feature from development to production using KRM.




