Accelerate migration from self-managed object storage to Cloud Storage

Ajitesh Abhishek
Product Manager, Google Cloud
Nishant Kohli
Google Cloud Storage Sr. Product Manager
Accelerate migration from self-managed object storage to Cloud Storage
Customers want to leverage Google Cloud Storage for its simplicity, scalability, and security. But migrating 100s of TB of data from a self-managed object storage is complicated. Writing and maintaining scripts that use resources effectively during transfer without compromising on security can take months.
To accelerate and simplify this migration, Storage Transfer Service recently announced Preview support for moving data from S3-compatible storage to Cloud Storage. This feature builds on Cloud Storage recent launches, namely support for Multipart upload and List Object V2, which makes Cloud Storage suitable for running applications written for the S3 API.
With this new feature, customers can seamlessly copy data from self-managed object storage to Google Cloud Storage for migration, archiving cold data, replicating data for business continuity, or creating data pipelines. For customers moving data from AWS S3 to Cloud Storage, it gives an option to control network routes to Google Cloud, resulting in considerably lower egress charges.
Storage Transfer Service is a managed service that enables customers to quickly and securely transfer data to, from, and between object and file storage systems, including Google Cloud Storage, Amazon S3, Azure Storage, on-premises data, and more. It offers scheduling, encryption, data integrity checks, and scale-out performance out of the box.
Cloud Storage advantage
Cloud Storage is a planet-scale object storage designed for at least 11 9's annual durability and offers multiple levers including Archive storage class and Lifecycle management to manage and deliver storage at ultra-low cost. It provides a single namespace that is strongly consistent and can span across the continent.
With your data in Cloud Storage, you can take advantage of Google Cloud’s cutting edge capabilities in content serving with Cloud CDN, computation with Compute Engine and Google Kubernetes Engine, analytics with BigQuery, Dataproc etc.
How does transfer from S3 Compatible storage work?
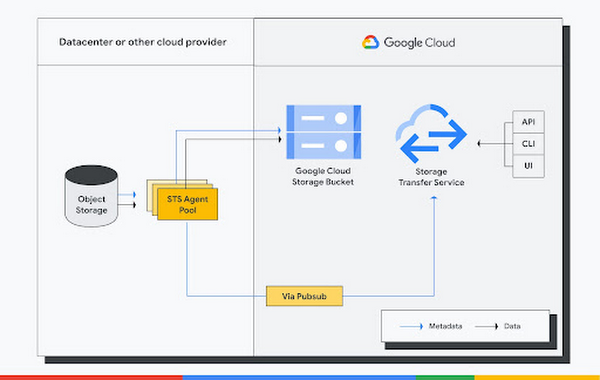
Storage Transfer Service consists of two components - control plane and agents.
Control plane coordinates the transfer of data including distributing work to agents, scheduling, maintaining state, scaling resources etc. Agents are a small piece of software, self hosted on a VM close to the data source. These agents run in a Docker container and belong to an “agent pool”.
To orchestrate transfer, you create a transfer job, which contains all the information necessary to move data including source, destination, schedule, filters to include and exclude objects, option to control the lifecycle of source and destination objects.
To use this feature, your object storage must be compatible with the following Amazon S3 API operations: GetObject, ListObjectV2 or ListObjectV1, HeadObject, and DeleteObject. It must also support AWS Signature Version 4 or Version 2 for authenticating requests.
Here is a quick CLI tutorial to help you get started.
How to copy data from S3 Compatible storage to Cloud Storage?
To transfer data from a self-managed object storage to Cloud Storage, you do the following:
Step 1: Configure access to the source
Step 2: Deploy Storage Transfer Service agents
Step 3: Create Transfer Job
Step 1: Configure access to the source:
You need to gather configuration details and credentials for STS to access the source data.
To configure agents to access the source, generate and note down the access and secret keys for the source. Agents need following permissions:
List the bucket.
Read the objects in the source bucket
- Delete the objects in the source bucket
In addition, note down the following information for your source:
Bucket Name: test-3
Endpoint: s3.source.com
Region: us-west-1
Step 2: Deploy Storage Transfer Service agents:
You need to deploy Storage Transfer Service agents near your storage system with appropriate permission to access source and Google Cloud resources.
To assign permissions for agent to access Google Cloud resources:
Create service account for the agent by navigating to the Cloud Console
Assign following roles to the agent service account:
Storage Transfer Agent (role/storagetransfer.transferAgent)
Storage Object Admin (roles/storage.objectAdmin)
Pub/Sub Editor (roles/pubsub.editor)
Generate the credentials file:
Replace the following values:
PROJECT_ID: The project id.
SERVICE_ACCOUNT_ID: The service account id.
service_account.json: The name of file to store credentials
To deploy agents on the host machine, first create an agent pool and then install agents.
Step 3: Create Transfer Job
STS uses transferJob to coordinate the movement data from a source to destination. Steps to create a transferJob:
1. Assign permissions to STS service account: STS uses a Google Managed service account to manage transfer. The service account's format is project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com.
For a new project, provision service accounts by making googleServiceAccounts.get API call.
Assign the following roles or equivalent permissions to this service account:
Storage Object Creator (roles/storage.objectCreator)
Storage Object Viewer (roles/storage.objectViewer)
Pub/Sub Editor (roles/pubsub.editor)
Storage Legacy Bucket Reader (roles/storage.legacyBucketReader)
2. You need to roles/storagetransfer.admin to create a transfer job. You can assign permission to this service account by navigating to “IAM and Admin” in the side nav bar and then to “IAM”
You can monitor the created transfer job either via CLI or cloud console.
Best practices
For large migrations, bandwidth is often the bottleneck. Use Cloud Interconnect for a more consistent throughput for large data transfers. To avoid impacting production workload, you can limit the amount of bandwidth consumed by the Storage Transfer Service through an agent pool parameter.
We recommend deploying agents close to the source to minimize network latency between the agent and your storage system. Run at least 3 agents for fault tolerance and allocate at least 4 vCPU and 8 RAM per agent.
When transferring large numbers of small objects, listing objects at the source can be a bottleneck. In this scenario, create multiple transfer jobs, each dedicated to a particular set of prefixes, to scale transfer performance. To run transfer on a particular set of prefixes, use include/exclude prefixes in the transfer job config.
To replicate data for business continuity, you can use a combination of deleteObjectsUniqueInSink and overwriteWhen. With these settings you always always overwrite the destination object with the source object and delete files deleted at the source, ensuring that Cloud Storage bucket destination is an exact copy of your source.
For guidance on migrating users sending requests to self-managed object storage using an API, refer to fully migrate from Amazon S3 to Cloud Storage.
In this blog, we’ve demonstrated how you can use Storage Transfer Service to quickly and securely transfer data from a self-managed object storage to Cloud Storage.
For more details on data transfer, refer to the Storage Transfer Service documentation.



