Woven by Toyota decreased their AI training times by 20% by using Cloud Storage FUSE
Marco Abela
Product Manager, Storage, Google Cloud
Alex Bain
Staff Software Engineer, Enterprise AI, Woven by Toyota
Editor’s note: Today, we hear from Woven by Toyota, the internal team behind Toyota’s Automated Driving (AD) and Advanced Driver Assistance Systems (ADAS) technologies, as well as “Woven City” — a test course for mobility in Susono, Shizuoka Prefecture, Japan. Both of these technologies — and many others — are built on Woven by Toyota’s Enterprise AI platform. In this blog, Woven by Toyota explains how Cloud Storage helped them simplify the storage infrastructure underpinning their Enterprise AI platform, while the new Cloud Storage FUSE file cache improved their AI/ML training times and costs. Then, read on as a Google Cloud product manager explains how Cloud Storage FUSE works, and shares best practices for configuring it and running it with your own AI workloads.
At Woven by Toyota, we take a software-defined vehicle approach to mobility, harnessing the transformative power of software to lead a revolution in the automotive field. Combining the power of AI with decades worth of experience and innovation, the Woven by Toyota software platform delivers reusable, secure, customizable, high-quality applications that can be personalized to specific customer experiences at scale.
Underpinning all of Woven by Toyota’s work is our Enterprise AI platform, a company-wide cloud training service used by our machine learning (ML) engineers. This platform provides users with various entry points (command line tools, web user interface and SDK) and functionality that abstracts the underlying infrastructure components that power the company’s ML training in the cloud.
In short, the Enterprise AI platform lets ML engineers focus on ML development rather than infrastructure. At the same time, the platform helps Woven by Toyota’s ML infrastructure team optimize the training process by supporting a variety of domain-specific requirements, tuning the infrastructure for the best performance at the lowest cost, and supporting Toyota’s growing demand for GPUs through a multi-cloud platform strategy.
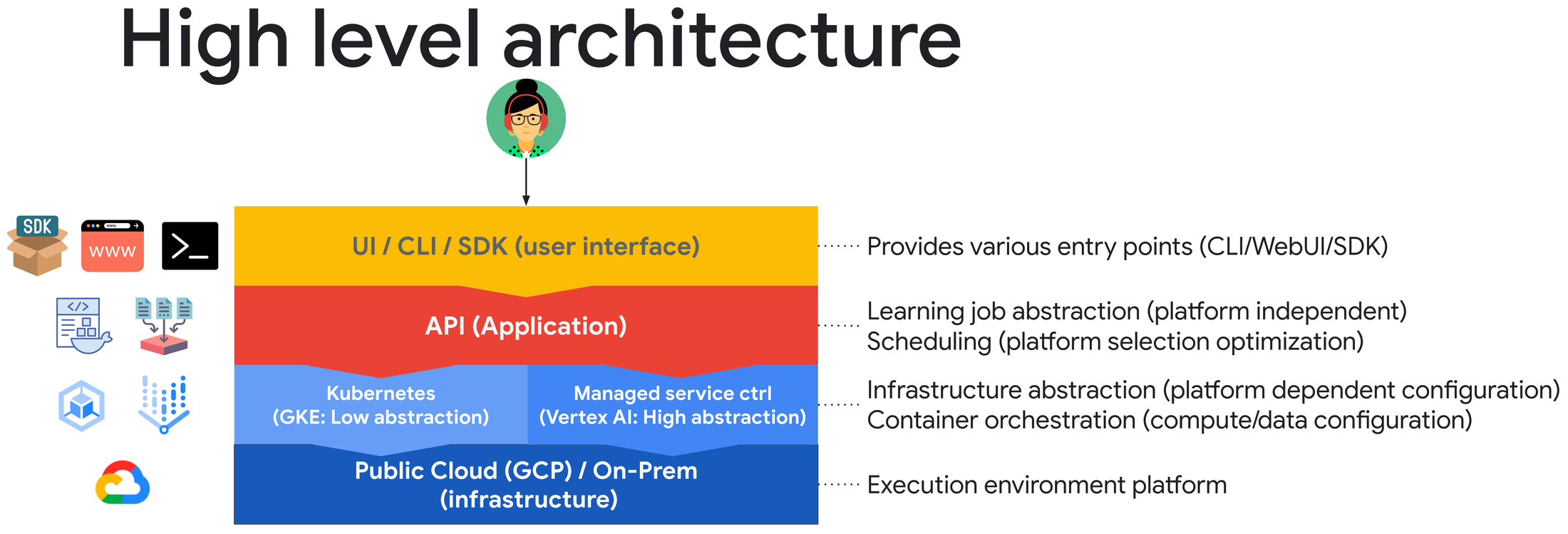
Woven by Toyota’s previous cloud storage solution
To provide a source of truth for our ML datasets, we use a cloud-based object storage service for its ability to scale and provide high aggregate throughput. However, in order for training jobs to achieve low latency (specifically for small file I/O) and to provide users with simple file system-based access to training data, we also used another cloud provider’s Lustre distributed file system service backed by object storage.
This solution posed a number of challenges. First, it made data management and governance challenging. Woven by Toyota’s ML users have multi-terabyte datasets with millions of files that need to be copied between cloud object storage, secure on-premises GPU machines (for local development), and cloud training jobs. The addition of the Lustre file systems made this even more complicated, as it required data to be copied and synchronized. It also added yet another place where we needed to ensure the data was being managed correctly in regards to our data governance policies.
Second, managing and using Lustre file systems comes with its own set of challenges and maintenance. Our Enterprise AI team was spending more and more time managing Lustre file system instances and dealing with user support requests. The operational complexity for the team only increased as the number of file systems and their size grew over time.
The final challenge was the cost. The cloud-based Lustre service was expensive and began to sprawl in multiples. Over the period of a year, we saw the monthly run-rate for our Lustre services increase by 10x.
With that as the backdrop, we began to conduct detailed experiments to see if we could meet our ML training performance needs with an alternate storage solution.
Initial comparison
At Woven by Toyota, we were looking for a storage solution that could provide similar performance, significantly better ease of use, and lower overall TCO at scale. We began experimenting with Cloud Storage FUSE as a simple solution to meet our needs. With Cloud Storage FUSE, our ML datasets can be mounted directly from Cloud Storage buckets into training jobs and appear as files in the local file system.
To test the performance and come up with a cost comparison, the Woven by Toyota Enterprise AI team used a custom PyTorch framework (based on the open-source Detectron2 library) to run a training job that learns a computer vision model based on a ResNet backbone for multi-class object detection. Our ML engineers have a deep understanding of this training task, which exemplifies a typical computer vision job for object detection with actual user-written training code.
The initial test showed a 14% reduction in training time and a 50% cost savings! We were pleasantly surprised to see that Cloud Storage could provide very high-bandwidth access natively without a Lustre-like file system service, resulting in 97% savings in storage costs.
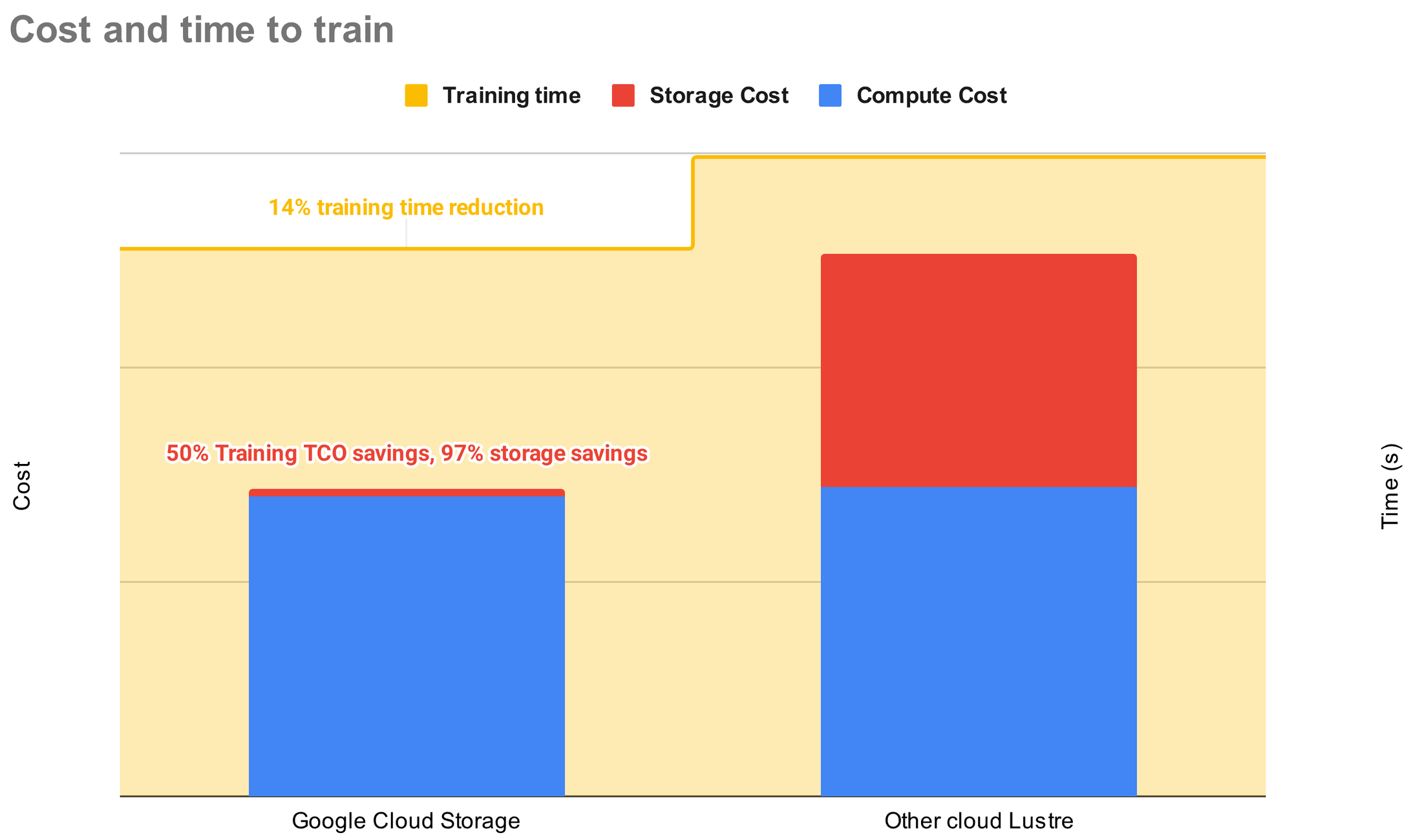
Kaizen testing
As an organization, we lean into the Kaizen philosophy of continuous improvement, so it will come as no surprise that Woven by Toyota sought ways to further optimize our performance through deeper testing and tuning.
For the next round of Kaizen testing, we used a training dataset that consisted of ~700k image samples varying from 500KiB to 3MiB per image. Bounding box labels and metadata for each training image are stored in a series JSON files. At the start of the training job, the code reads a large JSON index file that lists the paths to all the training images, labels and metadata files. Then, during the training process, the code re-reads the images and labels from the data source (previously the Lustre file system) whenever it is needed. Although the data format and data access pattern is not as efficient as it could be, we left it unoptimized since it reflects the actual code written by ML users to run their training jobs.
We wanted to test how using different numbers of threads affected ML training speed, particularly how fast data can be loaded. To use Cloud Storage effectively, we increased the number of threads in PyTorch using the num_workers setting, which allows for the parallel loading of data simultaneously. After experimenting with 4, 8, and 12, we found that setting num_workers to the batch size worked best (with diminishing returns thereafter).
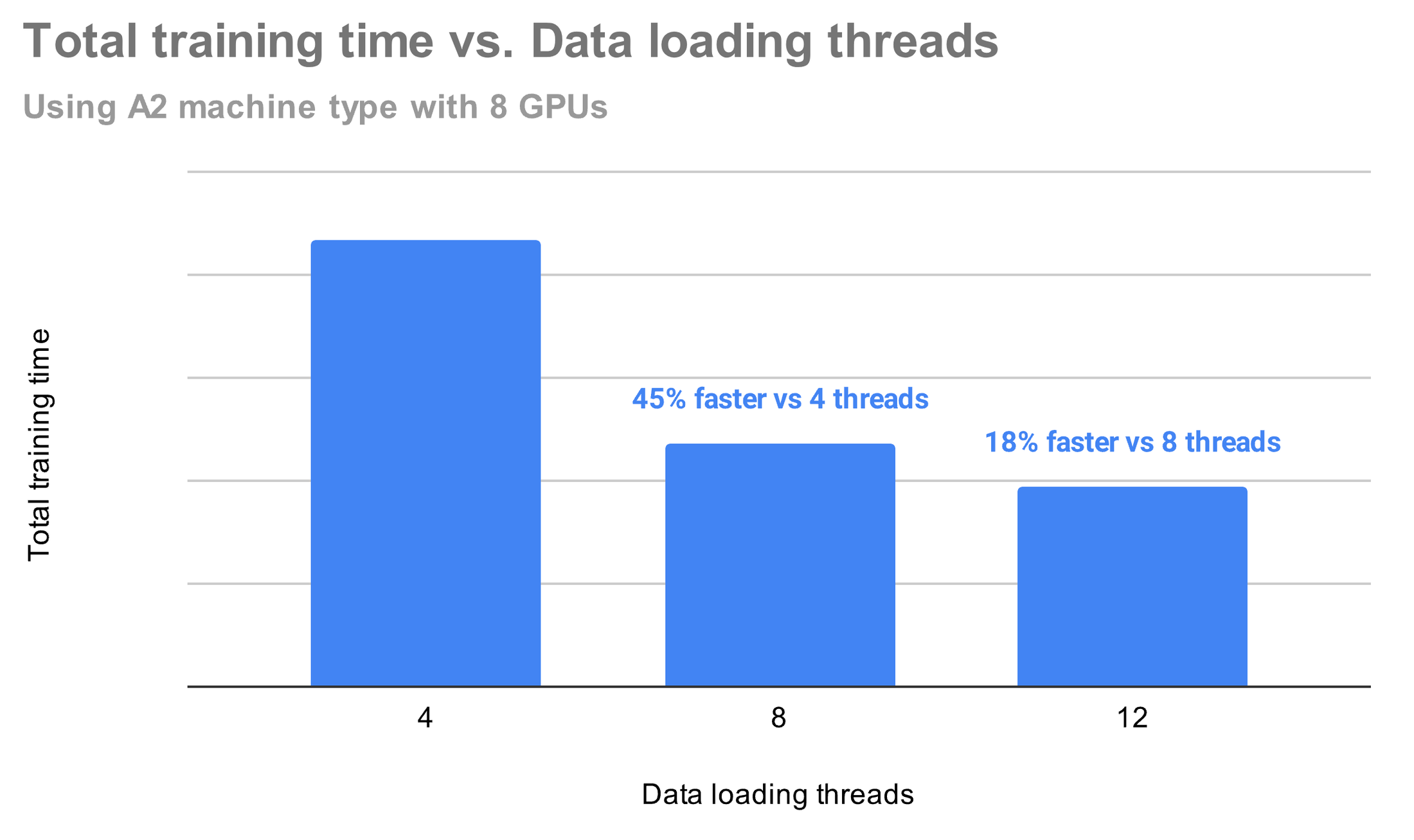
With that round of testing, we were convinced that Cloud Storage FUSE was the right choice for our Enteprise AI platform. Indeed, Cloud Storage FUSE has proven itself to be an elegant, easy-to-manage solution that empowers our engineers and optimizes our costs. Cloud Storage FUSE allows us to maintain Cloud Storage as the company’s single source of truth for our ML datasets, ensuring superior cost control and data governance, in addition to providing us with massive scalability, excellent performance, and ease-of-use for our ML engineers — all while slashing costs by up to 50%!
We also shared our experiences at Google Cloud Next ‘24. You can watch the replay here.
Best of all, this was before even experimenting with the newly introduced Cloud Storage FUSE file cache, where we can achieve even greater performance and savings. Now, let’s pass it back to the Google Cloud Storage FUSE Product Manager for more on this new capability…
Cloud Storage FUSE file cache overview and best practices
At Google Cloud Next ‘24, we introduced Cloud Storage FUSE file cache, a client-based read cache built on top of Cloud Storage FUSE that allows repeat file reads to be served from a local, faster cache storage of your choice, such as a Local SSD, Persistent Disk, or even in-memory /tmpfs. The Cloud Storage FUSE cache makes AI/ML training faster and more cost-effective by reducing the time spent waiting for data, leading to better accelerator utilization.
With the new Cloud Storage FUSE file cache, Woven by Toyota observed even better performance: 33% faster second-epoch time and 20% faster total training time, in addition to cost savings from reduced operations charges. As they deploy this in production at scale, they expect the improvements to increase even further as they train on larger datasets for longer.
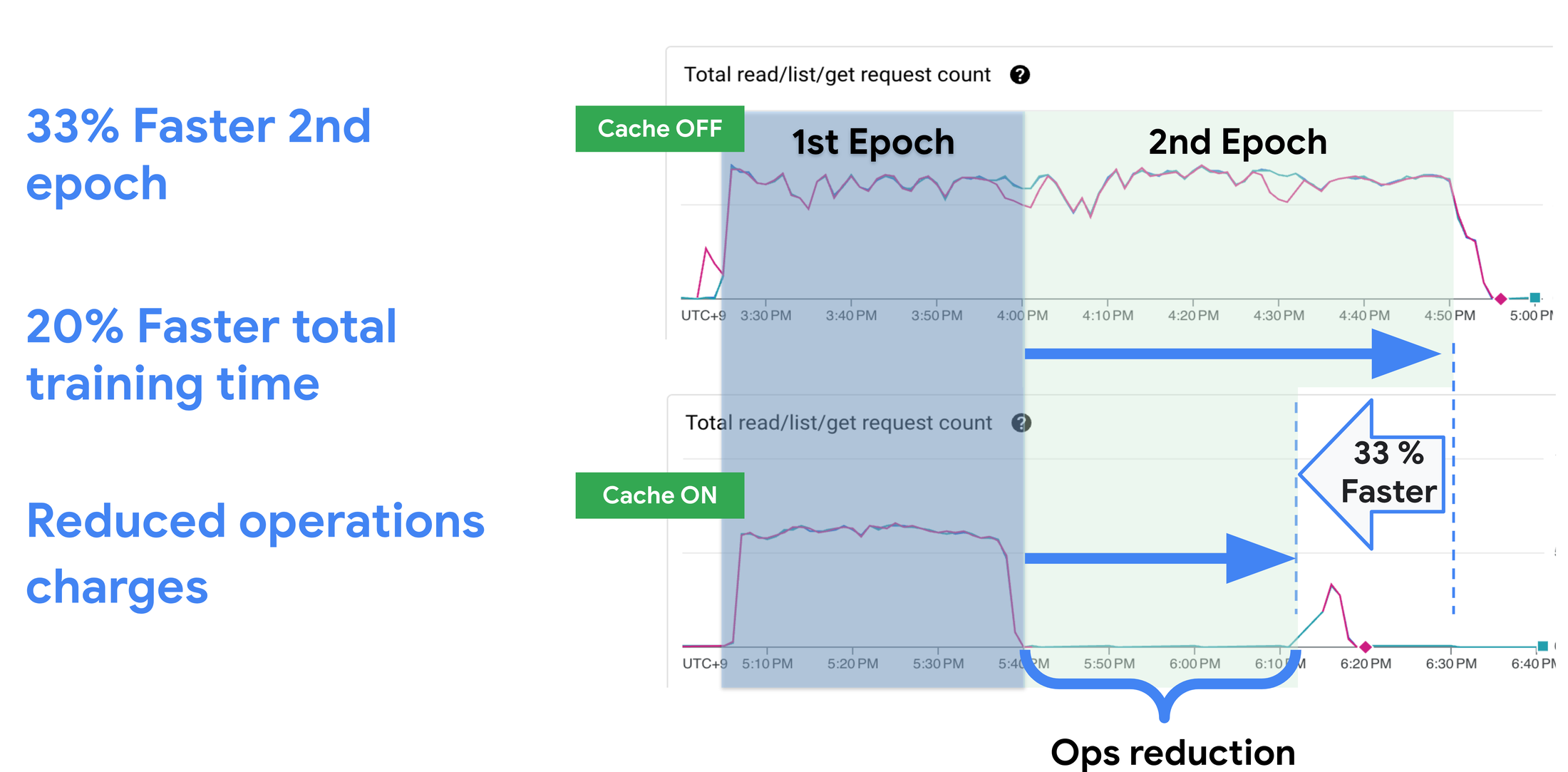
Performance improvements of using Cloud Storage FUSE file cache at Woven by Toyota.
Using Cloud Storage FUSE file cache
The Cloud Storage FUSE file cache is configured via a Config file, and consists of a file cache and a metadata cache (stat, type). The read cache is disabled by default, and is enabled by passing a directory to cache-dir, or by specifying fileCacheCapacity if using the Cloud Storage FUSE GKE CSI driver.
Did you know? A2 & A3 machine types come with up to 6TB of Local SSD already bundled, which can be used for the Cloud Storage Fuse file cache.
Cache capacity
max-file-size-mb is the maximum size in MiB that the file cache can use. This is useful if you want to limit the total capacity the Cloud Storage FUSE cache can use within its mounted directory.
By default, the max-size-mb field is set to a value of ‘-1’, which allows the cached data to grow until it occupies all the available capacity in the directory you specify as cache-dir. The eviction of cached metadata and data is based on a least recently used (LRU) algorithm that begins once the space threshold configured per max-size-mb limit is reached.
Time to live (TTL) settings
Cache invalidation is controlled by a ttl-secs flag. When using the file cache, we recommend increasing the ttl-secs to as high as allowed by your workload, based on the importance and frequency of data changes. For example, in an ML training job where the same data is typically read across multiple epochs, you can set this to the total training duration that you expect across all epochs.
Apart from specifying a value in seconds to invalidate the cache, the Cloud Storage FUSE file cache also supports more advanced settings:
-
A value of ‘0’ guarantees consistency, in that at least one call to Cloud Storage is made to check that the object generation in the cache matches that in Cloud Storage, guaranteeing that the most up to date file is read.
-
On the other hand, a value of ‘-1’ tells the cache to always serve the file from cache if the file is available in the cache, without checking the object generation. This provides the best performance, but may serve inconsistent data. You should consider these advanced options carefully based on your training needs.
Random and partial reads
When first reading a file sequentially from the beginning of a file (offset 0), the Cloud Storage FUSE file cache intelligently asynchronously ingests the entire file into the cache, even if you are only reading a small range subset. This allows subsequent random/partial reads from the same object, whether from the same offset or not, to be served directly from the cache once it’s populated.
However, if Cloud Storage FUSE isn’t reading a file from the beginning (offset 0), it does not trigger an asynchronous full file fetch by default. To change this behavior, you can pass cache-file-for-range-read: true. We recommended this be enabled if many different random/partial reads are done from the same object. For example, if working with an Avro or Parquet file that represents a structured defined dataset, many different random reads of many different ranges/offsets will happen against the same file, and will benefit from this being enabled.
Stat cache and type cache
Cloud Storage FUSE stat and type caches reduce the number of serial calls to Cloud Storage on repeat reads to the same file. These can be enabled by default and can be used without the file cache. Properly configuring these can have a significant impact on performance. We recommend the following limits for each cache type:
-
stat-cache-max-size-mb: use the default value of 32 if your workload involves up to 20,000 files. If your workload is larger than 20,000 files, increase thestat-cache-max-size-mbvalue by 10 for every additional 6,000 files, around 1,500 bytes per file. -
type-cache-max-size-mb: use the default value of 4 if the maximum number of files within a single directory from the bucket you're mounting contains 20,000 files or less. If the maximum number of files within a single directory that you're mounting contains more than 20,000 files, increase the type-cache-max-size-mb value by 1 for every 5,000 files — around 200 bytes per file.
Alternatively, you can set the value for each to -1 to let the type and stat caches use as much memory as needed. Use this only if you have enough available memory to handle the size of the bucket you are mounting per the guidance above, as this can lead to memory starvation for other running processes or out-of-memory errors.
Cloud Storage FUSE and GKE
GKE has become a critical infrastructure component for running AI/ML workloads, including for Woven by Toyota. GKE users are using Cloud Storage FUSE to get simple file access to their objects, through familiar Kubernetes APIs, via the Cloud Storage FUSE CSI. And now, you can enable the Cloud Storage FUSE file cache in GKE to accelerate performance as well. Use the following example YAML to create a Pod to enable the Cloud Storage FUSE file cache, which you can do by passing a value into fileCacheCapacity. This controls the maximum size of the Cloud Storage FUSE file cache. Additionally, configure the volume attributes metadataStatCacheCapacity, metadataTypeCacheCapacity, and metadataCacheTtlSeconds to adjust the file cache settings per your workload needs.
Note that you don’t need to explicitly specify the cache location, because it is automatically detected and configured by GKE. If the node has Local SSD enabled, the file cache medium will use Local SSD automatically; otherwise, by default, the file cache medium is the node boot disk.
Next steps
Get started with Cloud Storage FUSE here, with additional details on configuring the file cache feature. See additional GKE instructions here along with required GKE versions.


