Optimizing object storage costs in Google Cloud: location and classes
Dom Zippilli
Cloud Solutions Architect
Storage is a critical component of any cloud-based infrastructure. Without a place to store and serve your data, databases won’t work, compute can’t run, and networks have nowhere to put the data they’re carrying. Storage is one of the top three cloud expenses for many customers, and most companies' storage needs are only growing. It’s no surprise that customers ask us how to optimize their storage costs.
The vast majority of cloud storage environments use object storage, as opposed to the file or block storage used in most on-prem environments. Google Cloud’s object storage offering, Cloud Storage, is good for bulk storage of large amounts of data. Object storage is inherently "unstructured" (key-value pairs, with very large values), but the files stored within may be binary data, text data, or even specialized data formats like Apache Parquet or Avro.
At a penny or less per gigabyte, object storage is the cheapest and most scalable solution for the bulk of your data. But even though object storage pricing is low, costs can add up. For an organization with many workloads running, and changing needs over time, it can be challenging to optimize cloud storage needs (and costs) for each new or newly migrated application.
You can save on cloud storage in a number of ways. How you do so depends on a range of factors, including your data lifecycle needs, retrieval patterns, governance requirements, and more. This blog is the first in a series on how to save money on object storage in Google Cloud. We'll start by focusing on two of the biggest decisions you can make, namely, the Google Cloud regions where you store the data, and the storage class options that you can select.
Start with the right configuration
Your first opportunity to save on object storage is when you initially set up the bucket. Setting up storage is easy, but there are a few key decisions to make. Some of those choices, like storage location, become difficult and time consuming to change as the amount of data you are storing increases, so it is important to make the right decision for your needs.
Location
Choosing a storage location is about balancing between cost, performance, and availability, with regional storage costing the least, and increasing for dual- or multi-region configurations.
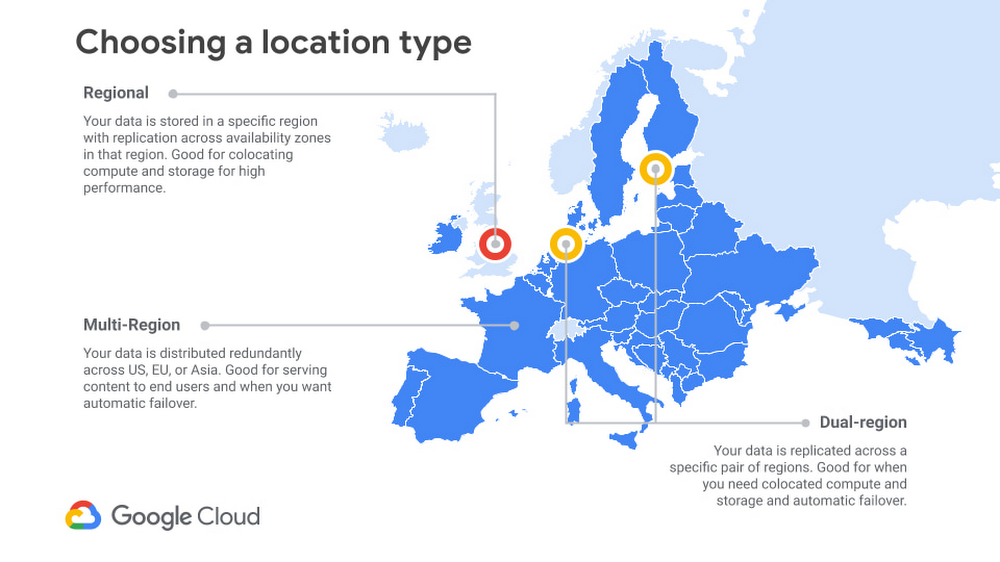
In general, regional storage has the lowest availability, because it is limited to, as the name implies, a single region. The data is still highly available. With single region storage, data is redundantly stored across multiple zones in the region (see this page for more about Google Cloud regions and zones). Google Cloud's systems are designed to isolate failures within a zone.
Dual-region and multi-region storage provide even greater availability, since there are now multiple regions (with multiple zones in each) that can serve requests, providing access to data even upon the unlikely event of a region-wide outage.
In terms of performance, picking a location for your storage is a complex topic. In general, pinning your data to a region (either by selecting regional or dual-region locations) will offer important performance gains when readers and writers are co-located in the same region. For example, if your workloads are hosted in a single Google Cloud region, you may want to ensure that your object storage is located in the same region to minimize the number of network hops. Alternately, if you have on-premises workloads using Cloud Storage for reads and writes, you may want to use a dedicated regional interconnect to reduce your overall bandwidth consumption and to improve performance.
Multi-region storage, conversely, will normally offer good performance for directly serving traffic to a very large geographic area, such as Europe or North America, with or without Cloud CDN. Many applications, particularly consumer-facing applications, will need to account for “last mile” latency between the cloud region and the end-user. In these situations, architects may find more value in multi-region storage, which offers very high availability and cost savings over dual-region storage.
As to cost, regional storage is the lowest priced option. Dual-regions are the most expensive, as they are effectively two regional buckets with shared metadata, plus the attendant location pinning and high performance. Multi-regions are priced in the middle, as Google is able to store data more economically by retaining the flexibility of choosing where to place the data. Roughly, for every $1 of regional storage, expect to pay ~$1.30 for multi-region, and ~$2 for dual-region storage of any given class.
Since these are significant multipliers, it's important to think strategically about location for your Cloud Storage buckets. Some services create buckets in the US multi-region by default, but don't blindly accept the default. Consider your performance and availability requirements, and don't pay for more geo-redundancy and availability than you need.
Storage class
Once you’ve picked a location for your Cloud Storage buckets, you need to choose a default storage class. Google Cloud offers four classes: Standard, Nearline, Coldline, and Archive. Each class is ideal for a different data retrieval profile, and the default class will automatically apply to all writes without a class specified. For greater precision, storage class can be defined on each individual object in the bucket. At the object level, storage class can be changed either by rewriting the object or using Object Lifecycle Management. (We’ll talk more about lifecycle management in a future blog in this series.)
Storage pricing is for on-demand usage, but there's still an implicit "contract" in the price that helps you get the best deal for your use case. In the case of "hot" or "standard" storage, the contract has a higher per-GB monthly storage price, but there are no additional per-GB fees for retrieval or early deletion. For "cooler" storage classes, your monthly per-GB storage costs can be much lower, and you will need to consider per-GB fees for retrieval and for early deletion. Your goal is to choose a default storage class which will generate the lowest total cost for your use case most of the time. A long-term view (or forecast) is important.
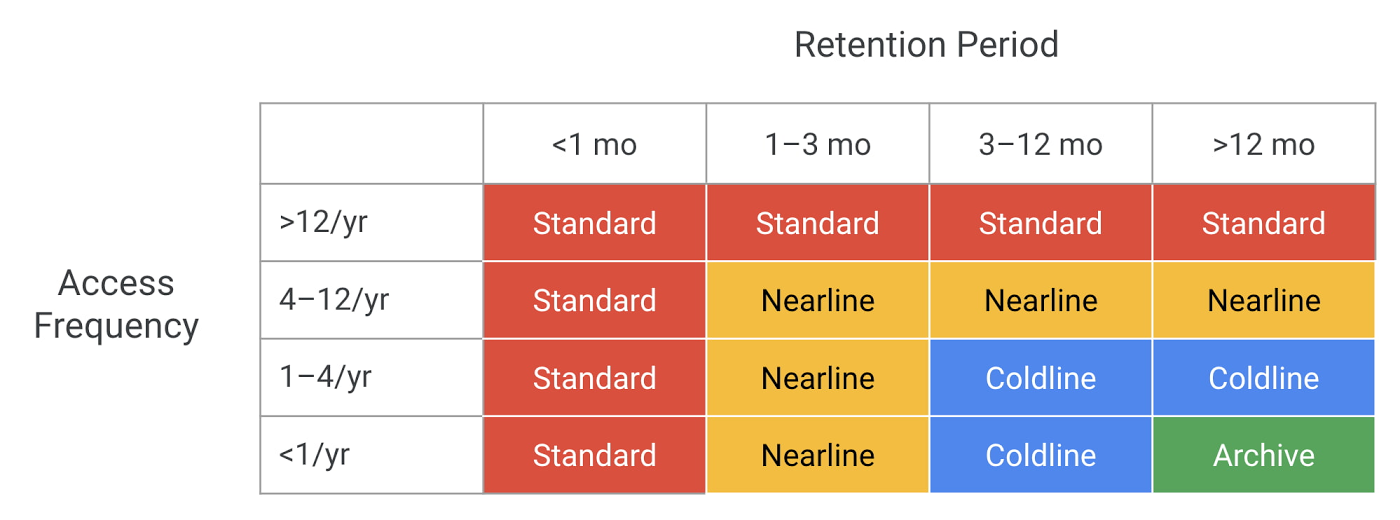
To start, the guidelines we give in our documentation are safe bets:
Standard: Access regularly, no retention minimum. This is "hot" data.
Nearline: Access less than once a month, retain for more than a month.
Coldline: Access less than once a quarter, retain for more than a quarter.
Archive: Access less than once a year, retain for more than a year.
But what if your data access retrievals vary? Many Cloud Storage users retain data for more than a year (if not indefinitely), so we won’t complicate the analysis with early deletion costs. (In other words, this analysis assumes you will retain all data for more than a year.) However, for retrieval costs, if you have a borderline case, a mixture of cases that you can't easily predict, or just want to be more precise, you can use the following formula to find the breakeven point for access frequency between two storage classes.
Where:
hs = Gigabyte-month storage cost for the "hotter" class
cs = Gigabyte-month storage cost for the "colder" class
cr = Gigabyte retrieval cost for the "colder" class
(hs - cs) / cr = Portion of data read each month at the breakeven point
For example, consider Standard vs Nearline Regional storage in us-central1 (prices as of January, 2021):
(0.02GB/m - 0.01GB/m) / 0.01GB = 1.0/m = 100% per month
This means that you could read up to 100% of the amount of data you store in Nearline once each month and still break even. Keep in mind, however, two caveats to this calculation:
Repeat reads also count. If you read 1% of your data 100 times in the month, that would be just like reading 100% of the data exactly once.
This calculation assumes larger (10s of MBs or greater) average object size. If you have very small files, operations costs will impact the calculation.
Nonetheless, if you're reading any less than 100% of the amount you stored and don't have tiny objects (more on that below), you could likely save money just by using Nearline storage.
For a visualization of this trend across all our storage classes, here's a chart showing storage and retention costs for us-central1 (Iowa) Regional storage classes. These trends will be similar in all locations, but the "Best Rate" inflection points will differ.
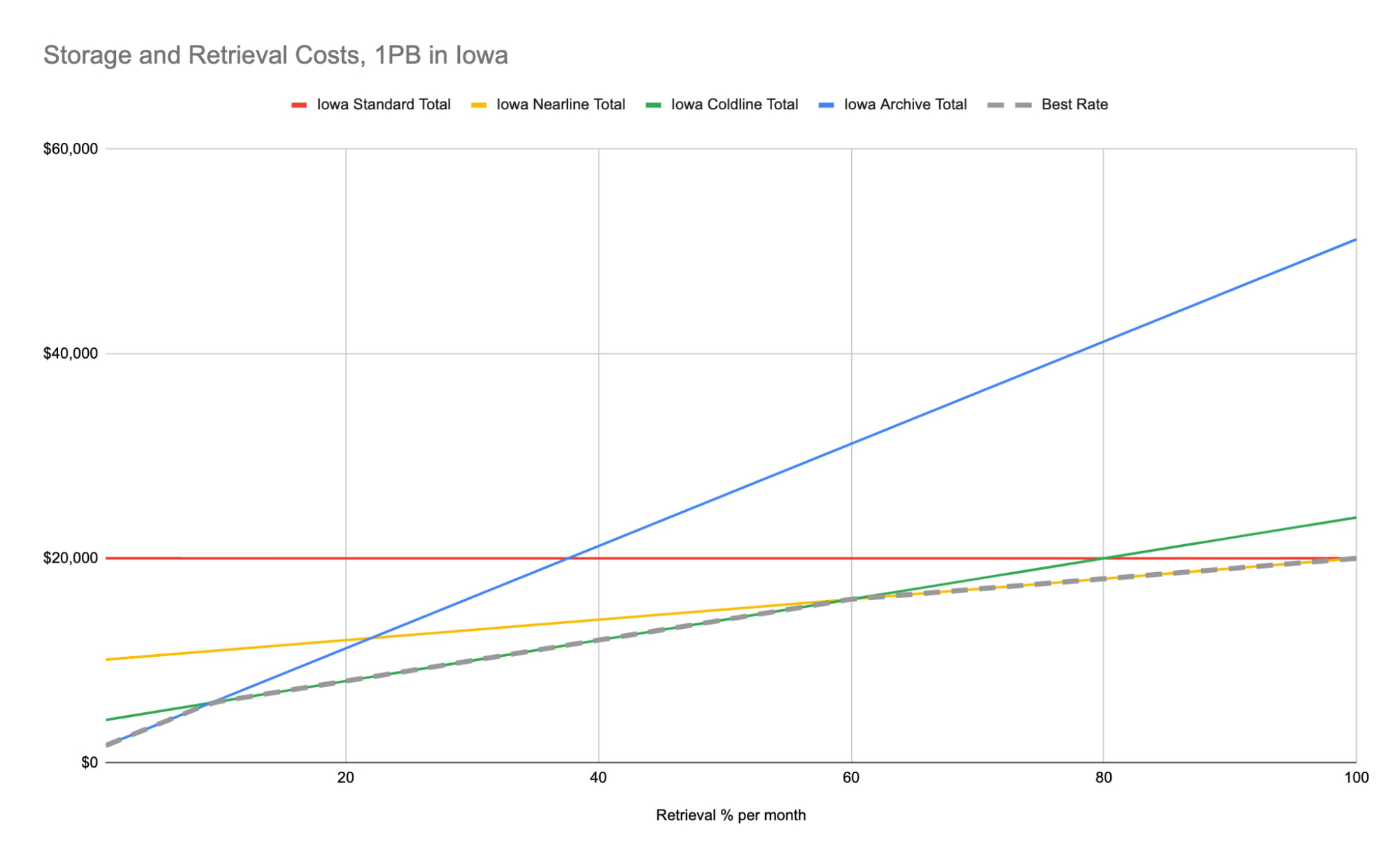
Assuming, again, that you plan to keep your data for one year or longer, you want your storage class selections to follow the "Best Rate" dotted line shown above. In this case, the inflection points for data read exactly once per month are at about 10%, 60%, and 100% for Archive, Coldline, and Nearline, respectively.
Another way to think about this is that if you access less than 10% of your data or less exactly once per month, Archive is the most cost-effective option. If you access between 10% and 60% of your data exactly once per month, Coldline is the cost-optimized choice. And if you expect to access between 60% and 100% of your data exactly once per month, Nearline is the lowest-cost storage class. Standard storage will be the best option if you access 100% of your data or more exactly once per month; this makes it a good choice if you have frequently accessed data with many repeat reads.
Conclusion
Object storage plays a significant role in cloud applications, and enterprises with large cloud storage footprints must keep an eye on their object storage costs. Google’s object storage offering, Cloud Storage, offers many different avenues to help customers optimize their storage costs.
In this blog, the first of a series, we shared some guidance on two of the most important avenues: storage location and storage class. Storage location and storage class are defined at the creation of your bucket, and each option offers different tradeoffs. Our guidance above is designed to help you make the right choice for your storage requirements.
For more information about Cloud Storage and how to get started, see our how-to guides, and stay tuned for additional blog posts on optimizing object storage costs for retrieval patterns and lifecycle management.


