Cloud Functions pro tips: Retries and idempotency in action
Slawomir Walkowski
Software Engineer
If you’ve been following our Cloud Functions pro tips series, you’ll recall previous blog posts where we showed you how to improve reliability of a serverless solution by retrying function executions and making functions idempotent. Now, it’s time to apply retries and idempotency to a real-world use case: food!
Today, let’s look at an order processing system for fictional restaurant, Kale Pizza & Pasta. Built on Google Cloud Platform (GCP), the system lets customers place and cooks receive orders from a web browser, using a mix of Cloud Functions, Cloud Pub/Sub, Cloud Firestore and Firebase Hosting. You can see the architecture in the following diagram:
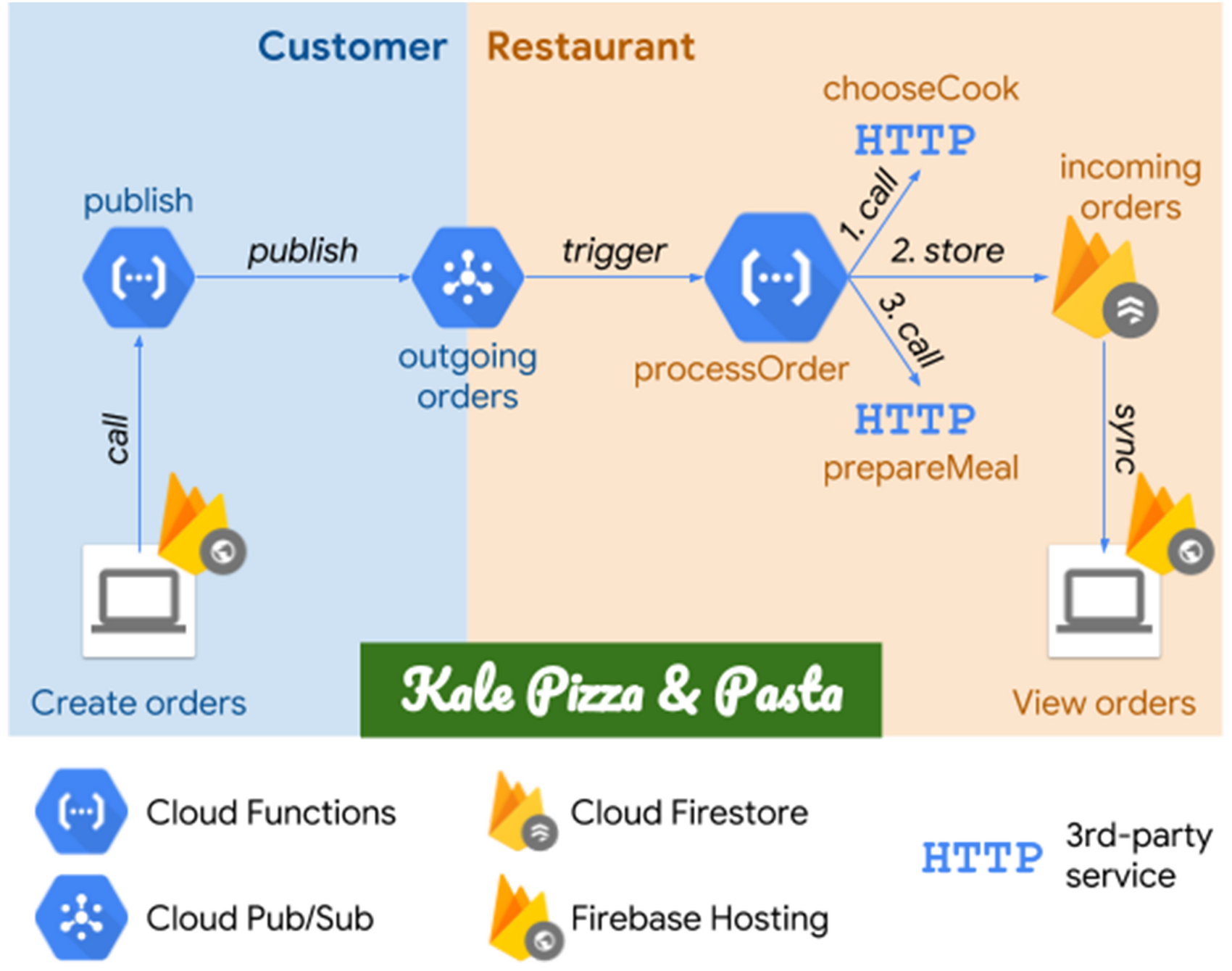
Starting from the left, the customer places their orders through a website, which calls the publish service built with Cloud Functions to publish the orders to a Cloud Pub/Sub topic. Messages from this topic then trigger the processOrder function, which does three things sequentially: calls the third-party chooseCook service to choose the cook who will handle the order; stores the order in Cloud Firestore; and calls prepareMeal, another third-party service, which notifies the cook about the new order. Finally, restaurant workers can view the orders on a website which simply syncs the data from Cloud Firestore. Both websites have been deployed to Firebase Hosting, which provides a fast and easy way to host web apps.
Plan for failure
If you’ve ever eaten at a restaurant, you know what you order isn’t always what you receive. So to test our application’s resiliency, we decided to simulate real-life third-party systems by introducing random failures to thechooseCook and prepareMeal services. In our example implementation, these third-party services are emulated with functions that fail randomly 10% of the time. Here is the source code:To test the system against heavy load, the customer-side website JavaScript code calls the publish service once per second, which creates orders that are processed by the system as described above. The restaurant-side website on the other end of the order processing pipeline shows orders that have been added to the database.
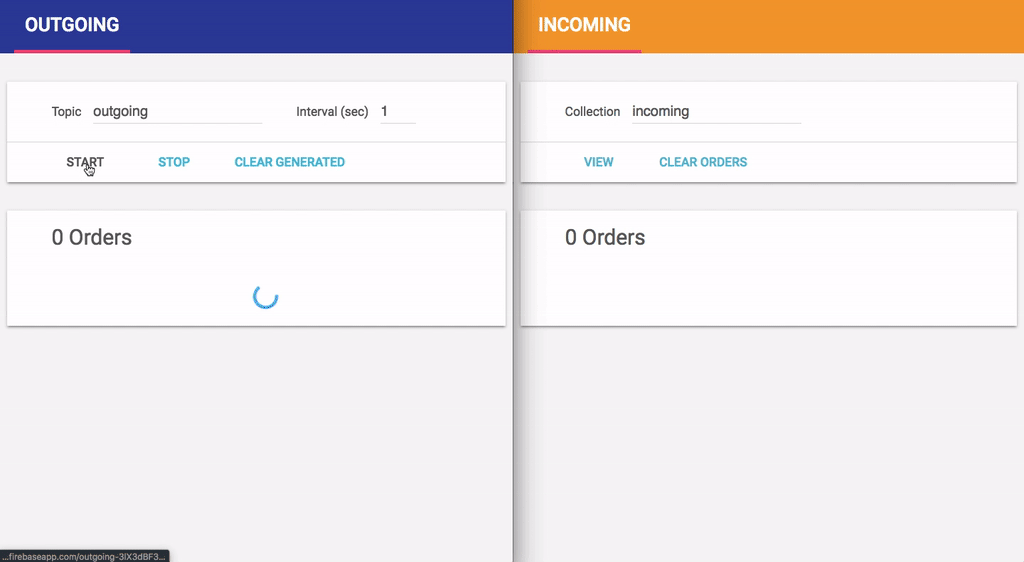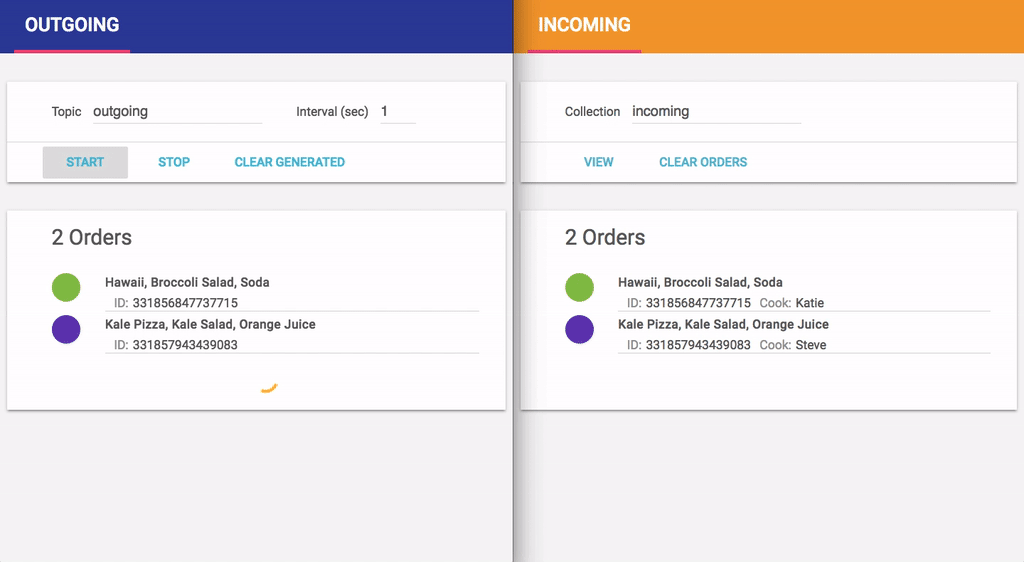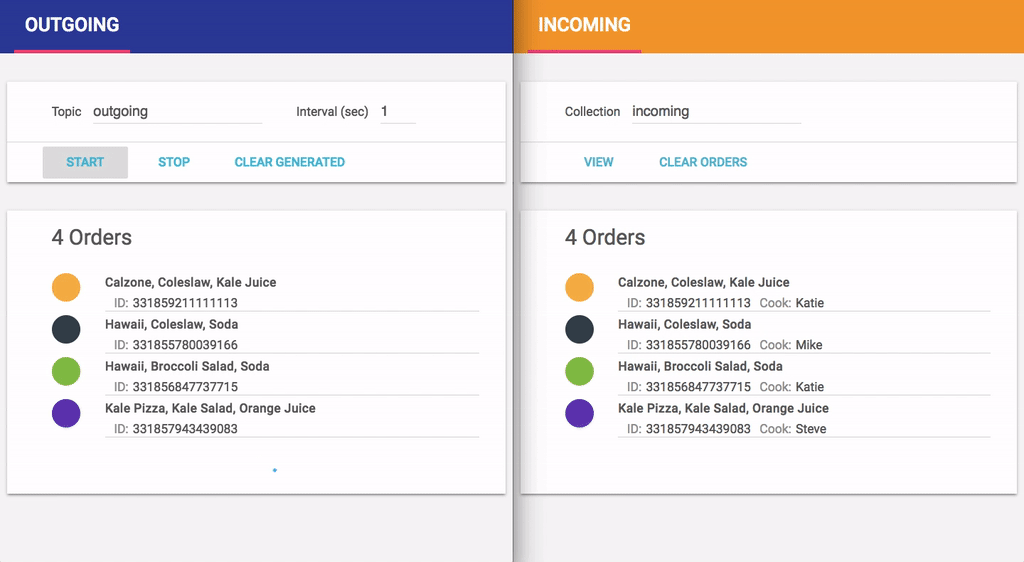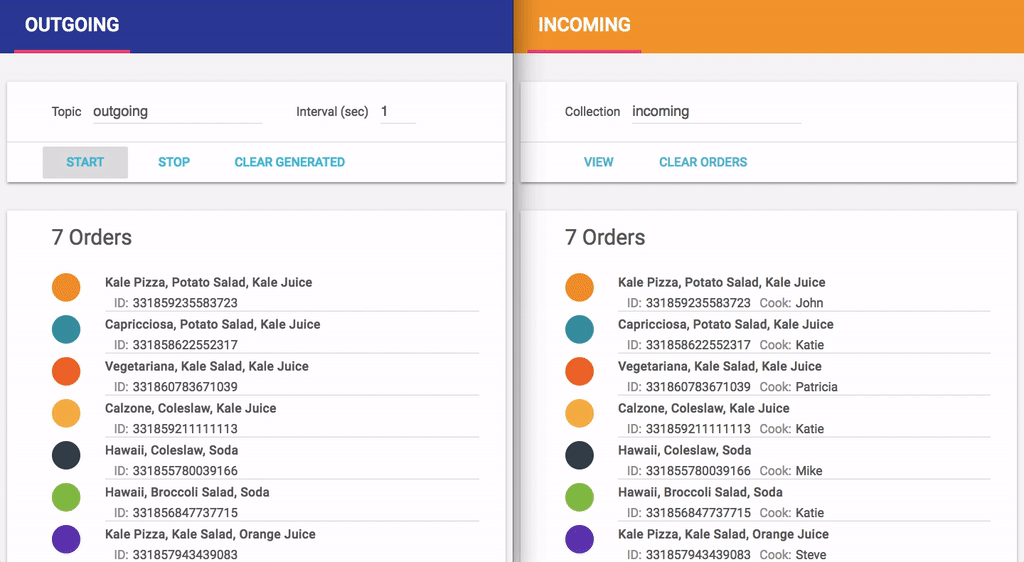
Both websites present the orders chronologically. Each order includes its ID and ordered menu items. Additionally, the restaurant-side website shows the cook assigned to the order. The orders IDs are color-coded, to make it easier to spot corresponding orders on both websites.
We generate customer orders for a while, and then look at both websites side by side. Here is the list of orders as seen by the customer system and by the restaurant:
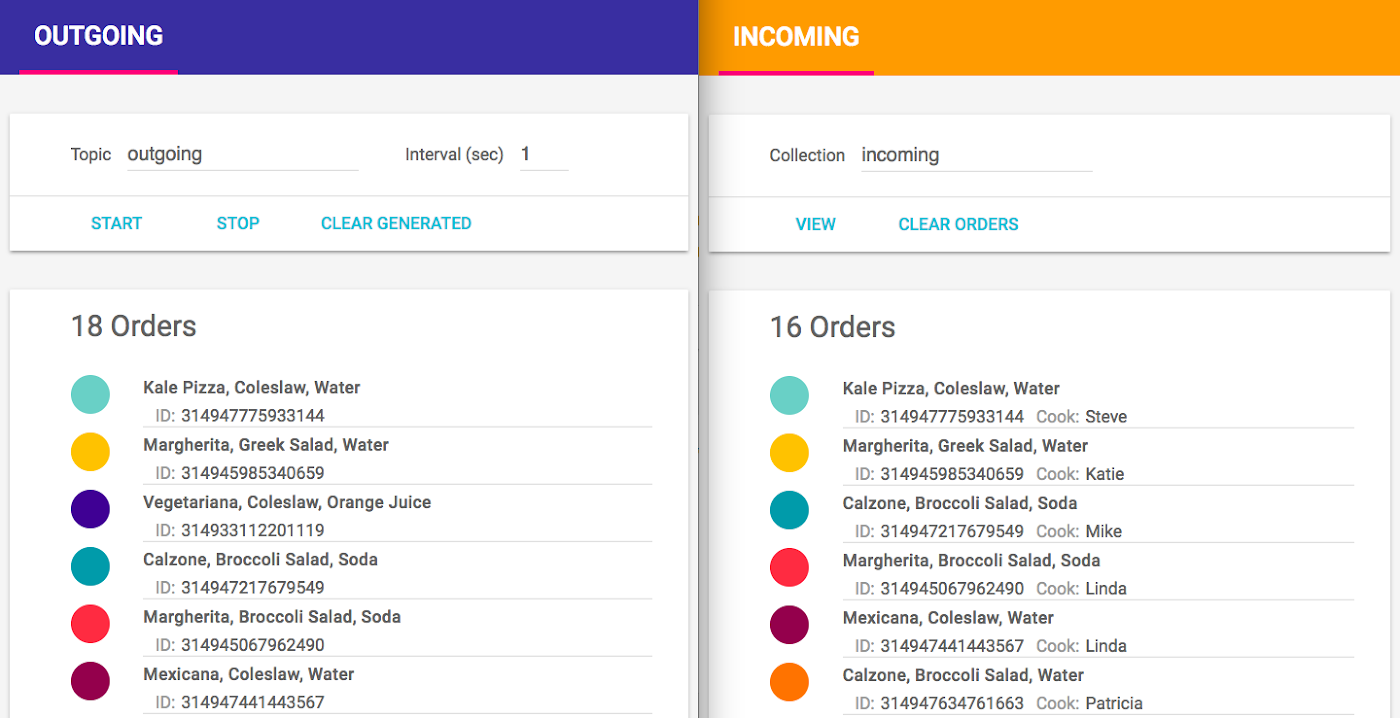
Looking at the number of orders, we immediately spot a problem: Kale Pizza & Pasta customers generated 18 orders, while the restaurant received only 16. Reviewing orders on the restaurant side, we can see that some customer orders are missing. (For example, the order for Vegeteriana, Coleslaw, Orange Juice is listed on the customer side but hasn’t made it over to the restaurant.) Lost orders mean unhappy customers—not good for business!
Our order processing system runs on GCP and Firebase Hosting, so we can use Stackdriver to analyze its behavior. For example, let’s open Stackdriver Error Reporting in the Cloud Console to see where the errors are coming from:
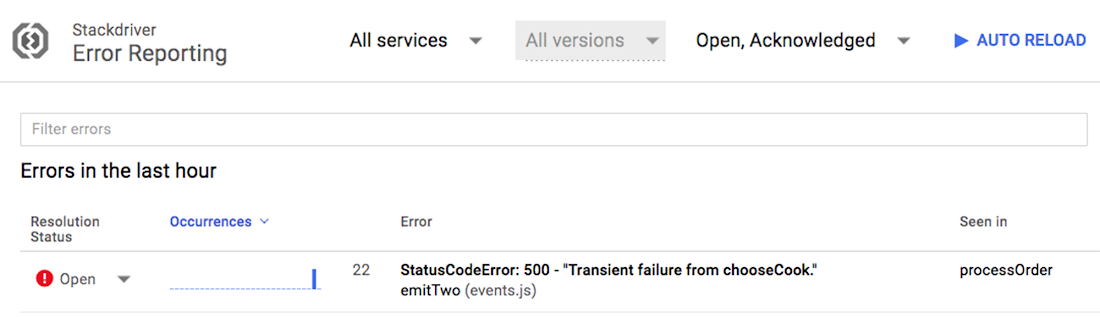
Here, we see that the processOrder function is failing because of a transient error coming from the chooseCook function. After clicking on the error, we get more information about it, like error counts and a sample stack trace. To drill down to a specific instance of the error, we open logs for one of the listed error samples, and use Stackdriver Logging to filter the function logs by one of the execution IDs:
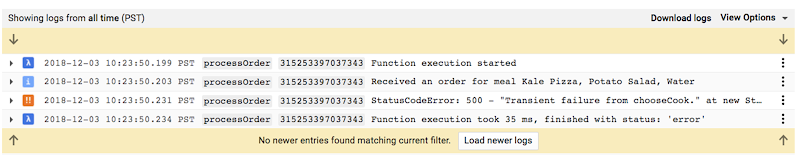
Here we see that the function failed to perform its first action—choosing a cook—and thus terminated its execution early, with an error. This explains why the order that triggered the function was not persisted in the database: the piece of the function code which stores an order did not have a chance to execute.
The source code for the processOrder function, available from the Cloud Function page in Cloud Console, shows that the function result is formed by three chained Promises. This confirms that the function terminates early if any of the three performed actions fails:
If you fail, try, try again
As we already know, chooseCook function has been written in a way to generate occasional failures. Thus, let’s make its caller, the processOrder function, more robust to handle such transient failures well.
As described in a previous blog post, there is a simple strategy for handling transient errors like these: applying retries. Because we have a background cloud function, we can simply enable retries by redeploying the processOrder function, with the source code unchanged, but this time with ‘Retry on failure’ enabled.

With this fix applied, we rerun our test and generate new orders through the updated function:
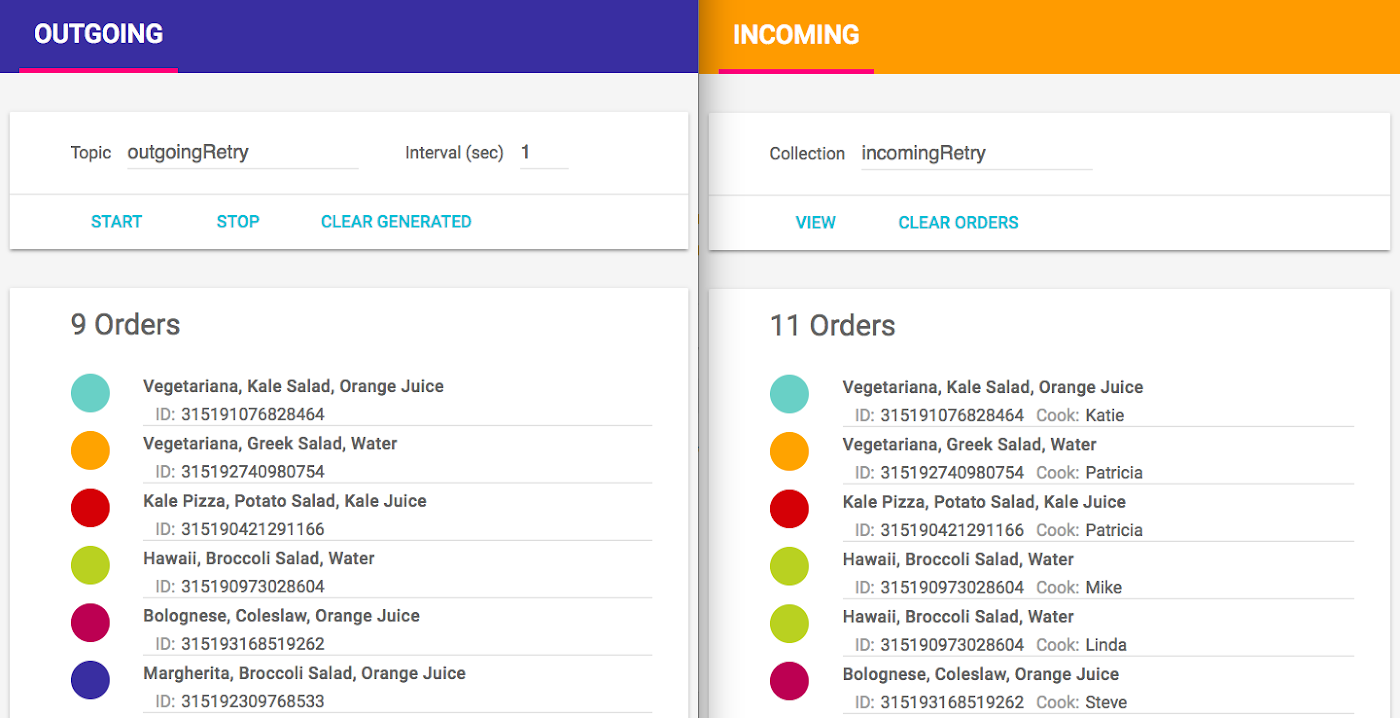
Unfortunately, the order counts still don’t match. But this time the restaurant website has more orders (11) than the customer site (9). By reviewing the restaurant’s order list, we see the reason for this situation: duplicate orders. For example, an order for Hawaii, Broccoli Salad, Water was created by the customer only once but appears twice on the restaurant site, assigned to two different cooks! Customers may be fine with that but just like missing customer orders, delivering extra pizzas is not good for Kale Pizza & Pasta’s business.
Why are we getting duplicate orders? By looking into the reported errors, we see that not only does the chooseCook function return transient errors but the prepareMeal function does as well. Now, looking into the processOrder function source code again, we see that a new order document is added to Cloud Firestore every time a function executes. This results in duplicates in the following scenario: when an order is added to Cloud Firestore and then the call to prepareMeal function fails, the function is retried, resulting in the same order (potentially with a different cook assigned) being written to Cloud Firestore as a separate document.
Applying idempotency
We discussed situations like this in our blog post about idempotency, showing how you must make a function idempotent if you want to apply retries without duplicate results or side effects.
In this case, to make the processOrder function idempotent, we can use a Cloud Firestore transaction in place of the add() call. The transaction first checks if the given order has already been stored (using the event ID to uniquely identify an order), and then creates a document in the database if the order does not exist yet:
After deploying the function with this change applied, and ‘Retry on failure’ still enabled, we start to generate orders again:
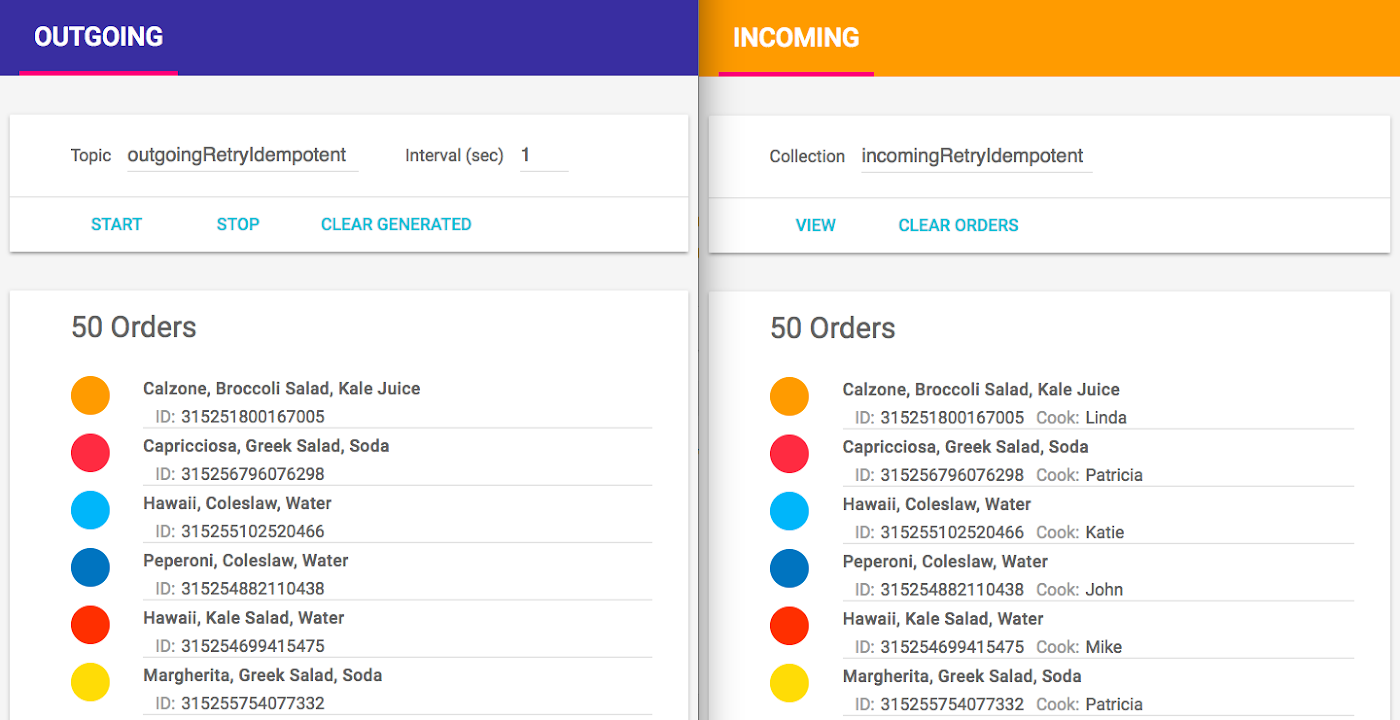
Success! The restaurant receives all the orders, and not a single duplicate! Even if we wait a bit and generate more events, the number of orders created on the customer side and received by the restaurant still match.
In this example we showed you how to apply retries and idempotency to a real-life scenario. We made the process reliable by handling failures gracefully, without having to change the dependent services. They may still fail occasionally, but this won’t affect the workflow. It is also worth noting that we used GCP’s built-in observability features to help us analyze the problem. To learn more about how to build simple, scalable and reliable systems on GCP, check out cloud.google.com/functions/. You can also find the source code for the functions we used in this blog post on GitHub.



