Cloud Functions pro tips: Using retries to build reliable serverless systems
Slawomir Walkowski
Software Engineer
By now, you’re probably familiar with Cloud Functions, Google Cloud’s event-driven serverless compute platform. You may have even written a few functions yourself. Cloud Functions runs code in response to events emitted by Google Cloud Platform (GCP) or third-party services and clients. This is one of the simplest ways to run your code in the cloud: there are no servers to think about, you just wire your code to events, and pay only when it runs.
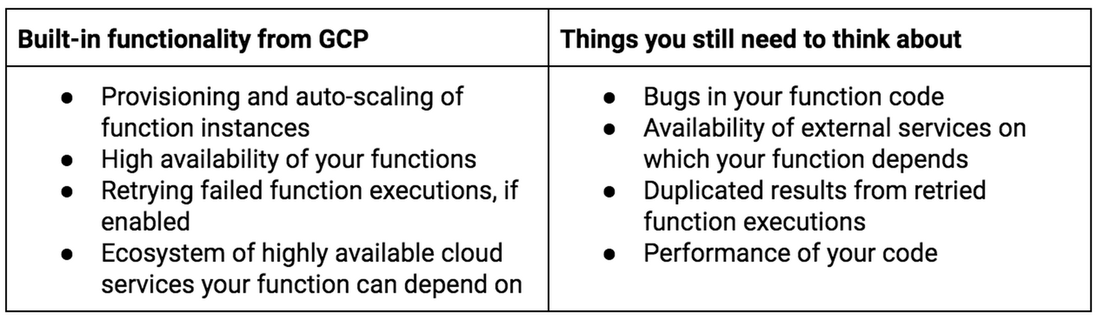
In theory, any service you build on top of Cloud Functions will scale automatically and also benefit from Cloud Functions’ availability and fault-tolerance characteristics, for example, provisioning and autoscaling of your functions, and its production-grade SLA.
But does that mean you don’t need to think about reliability issues associated with large-scale distributed systems? The answer is, not completely. While there are many things that GCP and Cloud Functions handle behind the scenes, you still need to keep a couple of best practices in mind while building a reliable serverless solution. In this post, we’ll discuss one of the key aspects of building reliable production systems with Cloud Functions: retrying executions.
Retrying executions in Cloud Functions
The first thing you need to accept is that in distributed systems, failures happen. In fact, they are an inherent part of complex distributed systems, and it’s practically impossible to build one without them. To learn more about fault tolerance in distributed systems, check out Distributed systems: principles and paradigms book by A. S. Tanenbaum and M. van Steen.
You can, however, follow system-design best practices on how to handle failures gracefully. GCP helps in many ways, for example, by handling hardware failures and replicating your data. When you call the Cloud Vision API to identify an image, GCP makes sure that the service is available and can handle your request; when you put an object into a Cloud Storage bucket, Google makes sure it is persisted, using replication. But the overall reliability of your software running in the cloud must be a shared priority between you and the cloud provider.
As mentioned, functions act on events. They are particularly useful for connecting different systems, for example processing incoming data and uploading it to a storage system. In a perfect world, everything works as planned—a function receives data and persists it, for example in a database.

Unfortunately, there are lots of ways a function can fail. For example, it could run out of memory, there could be an external network connection issue, or a dependent third-party service may respond with a transient error. All these issues may result in data loss if the data doesn’t make it to the storage system.
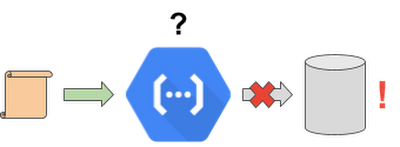
In a serverless environment, the simplest way to handle such failures is to retry executing the function, preferably automatically. (This is certainly better than asking your users to retry the failed requests to your system.)
HTTP vs. background functions
With Cloud Functions, all functions are typically invoked once for each request or event—unless an error occurs. Then, Cloud Functions offers different execution guarantees depending on what type of function you are using: an HTTP function or a background function.
- HTTP functions are invoked by standard HTTP requests, which wait for an HTTP response from the function.

- Background functions are invoked by cloud events, such as messages on a Cloud Pub/Sub topic, or changes in a Cloud Storage bucket.
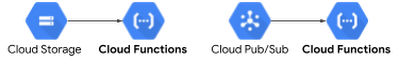
HTTP functions are invoked at most once, due to their synchronous nature. This means that Cloud Functions does not retry HTTP calls—the caller must handle any errors. This is as it should be, given that in the case of a network failure, an HTTP request might not even reach Google’s infrastructure in the first place.
On the other hand, background functions are invoked at least once because Cloud Functions can retry asynchronous function invocations triggered by events (as there is no caller who could do it otherwise).
Let’s look at some examples. Here is an HTTP function that uploads the incoming HTTP request body to another service, by sending a POST request to it. Simple, right?
The problem is that the dependent system could fail because of a network connectivity issue, for example. This would result in function execution failure, and potential data loss if the function was not retried.
In case of HTTP functions, the right approach is for the code that calls the function to perform the retries. To implement retries, you can either write custom retry logic, or reuse a common library, such as ‘promise-retry’ in the following sample code. Here, a rejected Promise results in retried calls to the function.
Now, here’s an example of a background function, which also uploads data to an external service. In this case, the data is extracted from a Cloud Pub/Sub message.
This background function has the same problem as our HTTP function—if the call to the dependent service fails, the function execution will fail, as we return the Promise as function result.
To retry background functions, you can usually just enable the ‘retry on failure’ option when deploying your function through the Cloud SDK or Cloud Console. This way, function execution is automatically retried for a given event until it completes successfully. The first retry is triggered almost immediately, and subsequent retries are performed according to the exponential backoff policy, capped at 10 second intervals, for up to seven days. You should be careful when using this option, though, because the function will be retried even if it crashes, returns an error because of a bug in your code, or because of unexpected event data. Therefore, you may want to make your function return an error only on transient issues (such as 503 Service Unavailable status code returned from an external service), and handle permanent problems (such as invalid input data) completely inside the function.

Overall, retries can by applied in multiple places. As in our examples, the caller can retry requests to an HTTP function, while background functions can be configured to automatically be retried on failure. You can also retry calls to dependent systems from inside a function. You can do this by configuring client libraries (look at the options they offer), or by writing custom code. Finally, be sure to distinguish persistent errors from transient failures, and apply retries only on the latter.
Gracefully handling failures with retries is a key aspect of building resilient, reliable serverless code. To help you get started, visit cloud.google.com/functions/ and you can also find all the code we used in this blog post on GitHub. Then, stay tuned for our next blog post, where we look at what to do when retrying a function isn’t enough.


