Cloud Functions pro tips: Building idempotent functions
Slawomir Walkowski
Software Engineer
In a previous blog post we discussed how to use retries to make your serverless system resilient to transient failures. What we didn’t mention is that if you’re going to retry a function, it needs to be able to run more than once without producing unexpected results or side effects.
In computer science, this refers to the notion of idempotence, meaning that operation results remain unchanged when an operation is applied more than once. Likewise, a function is considered idempotent if an event results in the desired outcome even if the function is invoked multiple times for a given event. In other words, if you want your functions to behave correctly upon retries, you have to make them idempotent. In this post, we’ll show you how to do that.
Exploring idempotent functions
To better understand idempotency, let’s analyze a workflow. In this example, we have a function that processes incoming data, writes the results to one storage system, and then to another one.
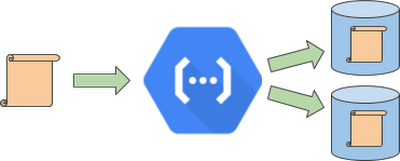
The problem arises when, as you may expect, an upload to one of the storage systems fails. For example, imagine the second upload fails; this can result in data loss or inconsistency.
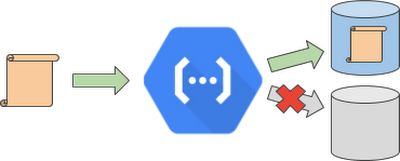
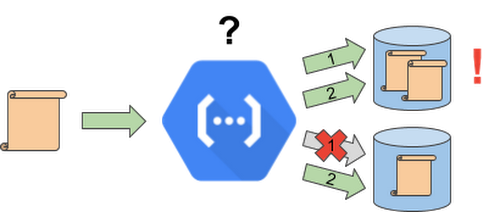
We already know how to handle such a failure—apply retries. But is it always safe to apply a retry? In this example, executing the function a second time stores the output in the second storage system (if the upload succeeded) but also results in writing a duplicate record or object into the first storage system. This could be unexpected by other systems, and result in further problems. Let’s discuss how to prepare a function for retried executions to avoid this kind of data duplication.
First, let’s look at a non-idempotent background function. It performs two uploads—first, it adds a document to Cloud Firestore, our flexible, scalable NoSQL database, and then uploads the document to another storage system off GCP. In a possible scenario when the upload to Cloud Firestore succeeds but the second upload fails, retrying the function results in a duplicate document, with the same contents, in the Cloud Firestore database. Of course, we don’t want duplicates, as they could cause confusion, accounting problems, and further inconsistencies.
Use your event IDs
One way to fix this is to use the event ID, a number that uniquely identifies an event that triggers a background function, and— this is important—remains unchanged across function retries for the same event.
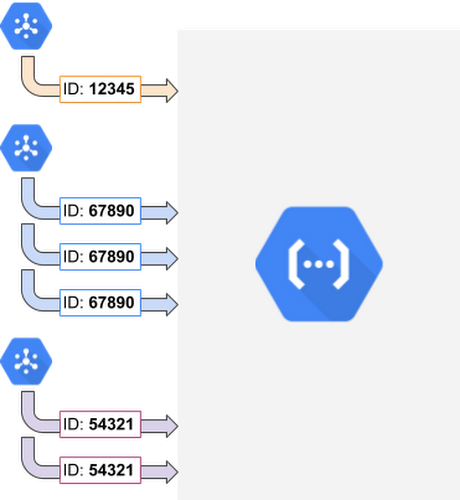
To use an event ID to solve the duplicates problem, the first thing is to extract it from the event context that is accessed through function parameters. Then, we utilize the event ID as a document ID and write the document contents to Cloud Firestore. This way, a retried function execution doesn’t create a new document, just overrides the existing one with the same content. Similarly, some external APIs (e.g., Stripe) accept an idempotency key to prevent data or work duplication. If you depend on such an API, simply provide the event ID as your idempotency key.
There! Now that you’ve applied this event ID mechanism, you shouldn’t see any more duplicates—in Cloud Firestore, or in another system that accepts idempotency keys.
But what if the system you call does not support idempotency? Consider the following example. Here, we call Sendgrid, the email delivery service, to send an email from the function. But the call isn’t idempotent so retrying the function may result in duplicate emails. What can you do to avoid this problem?
The general solution here is note when a system has handled an event, by recording its event ID. This way, you reduce the chance of unwanted retried calls to other services. In this example, we record the event ID in Cloud Firestore, but you can use another database or storage system as well. On each function execution, check whether the given event has already been recorded. If not, run the code and store the event ID in Cloud Firestore.
A new lease on retries
While this approach eliminates the vast majority of duplicated calls on function retries, there’s a small chance that two retried executions running in parallel could execute the critical section more than once. To all but eliminate this problem, you can use a lease mechanism, which lets you exclusively execute the non-idempotent section of the function for a specific amount of time. In this example, the first execution attempt gets the lease, but the second attempt is rejected because the lease is still held by the first attempt. Finally, a third attempt after the first one fails re-takes the lease and successfully processes the event.
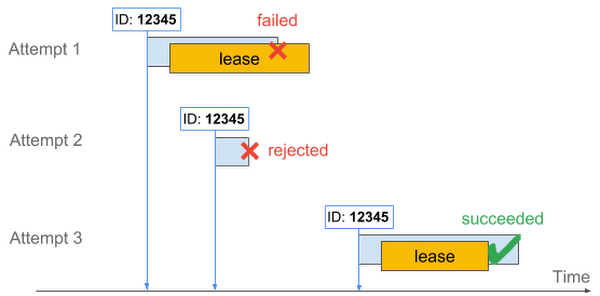
To apply this approach to your code, simply run a Cloud Firestore transaction before you send your email, checking to see if the event has been handled, but also storing the time until which the current execution attempt has exclusive rights to sending the email. Other concurrent execution attempts will be rejected until the lease expires, eliminating all duplicates for all intents and purposes.
By now, you can see that there are multiple ways to make a function idempotent, and doing so is an important part of handling failures and improving the reliability of your system. First, you can ensure that mutations can happen more than once without changing the outcome. You can also record event IDs that have been processed, query database state in a transaction before mutating the state, and supply an idempotency key if you’re calling APIs that support them. To learn more, check out cloud.google.com/functions/ and you can also find all the code we used in this blog post on GitHub. Stay tuned for the next post in the series, where we’ll demonstrate how to use retries and idempotency as part of a simple restaurant order-processing system.


