6 strategies for scaling your serverless applications
Preston Holmes
Product Manager
A core promise of a serverless compute platform like Cloud Functions is that you don't need to worry about infrastructure: write your code, deploy it and watch your service scale automatically. It’s a beautiful thing.
That works great when your whole stack auto-scales. But what if your service depends on an APIs or databases with rate or connection limits? A spike of traffic might cause your service to scale (yay!) and quickly overrun those limits (ouch!). In this post, we'll show you features of Cloud Functions, Google Cloud’s event-driven serverless compute service, and products like Cloud Tasks that can help serverless services play nice with the rest of your stack.Serverless scaling basics
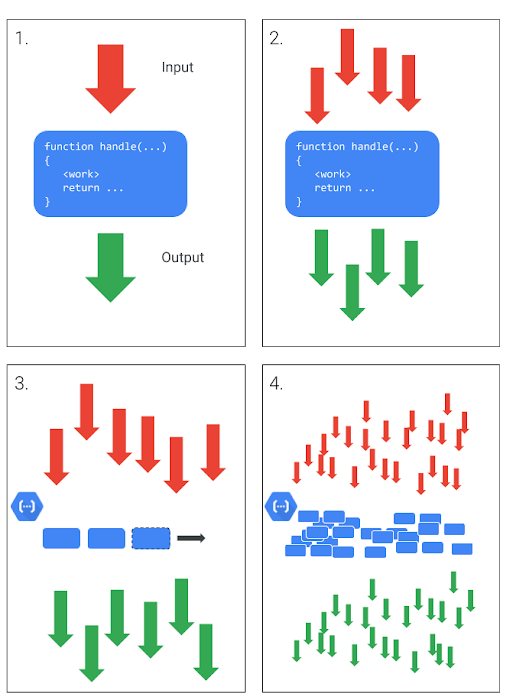
Lets review the basic way in which serverless functions scale as you take a function from your laptop to the cloud.
- At a basic level, a function takes input, and provides an output response.
- That function can be repeated with many inputs, providing many outputs.
- A serverless platform like Cloud Functions manages elastic, horizontal scaling of function instances.
- Because Google Cloud can provide near-infinite scale, that can have consequences for other systems with which your serverless function interacts.
Most scale-related problems are the result of limits on infrastructure resources and time. Not all things scale the same way, and not all serverless workloads have the same expected behaviors in terms of how they get work done. For example, whether or not the result of a function is returned to the caller or is only directed elsewhere, can change how you handle increasing scale in your function. Different situations may call for one or more different strategies to manage challenges scale can introduce.
Luckily, you have lots of different tools and techniques at your disposal to help ensure that your serverless applications scale effectively. Let’s take a look.
1. Use Max Instances to manage connection limits
Because serverless compute products like Cloud Functions and Cloud Run are stateless, many functions use a database like Cloud SQL for stateful data. But this database might only be able to handle 100 concurrent connections. Under modest load (e.g., fewer than 100 queries per second), this works fine. But a sudden spike can result in hundreds of concurrent connections from your functions, leading to degraded performance or outages.
One way to mitigate this is to configure instance scaling limits on your functions. Cloud Functions offers the max instances setting. This feature limits how many concurrent instances of your function are running and attempting to establish database connections. So if your database can only handle 100 concurrent connections, you might set max instances to a lower value, say 75. Since each instance of a function can only handle a single request at a time, this effectively means that you can only handle 75 concurrent requests at any given time.
2. Use Cloud Tasks to limit the rate of work done
Sometimes the limit you are worried about isn't the number of concurrent connections, but the rate at which work is performed. For example, imagine you need to call an external API for which you have a limited per-minute quota. Cloud Tasks gives you options in managing the way in which work gets done. It allows you to perform the work outside of the serverless handler in one or more work queues. Cloud Tasks supports rate and concurrency limits, making sure that regardless of the rate work arrives, it is performed with rates applied.
3. Use stateful storage to defer results from long-running operations
Sometimes you want your function to be capable of deferring the requested work until after you provide an initial response. But you still want to make the result of the work available to the caller eventually. For example, it may not make sense to try to encode a large video file inside a serverless instance. You could use Cloud Tasks if the caller of your workload only needs to know that the request was submitted. But if you want the caller to be able to retrieve some status or eventual result, you need an additional stateful system to track the job. In Google APIs this pattern is referred to as a long-running operation. There are several ways you can achieve this with serverless infrastructure on Google Cloud, such as using a combination of Cloud Functions, Cloud Pub/Sub, and Firestore.
4. Use Redis to rate limit usage
Sometimes you need to perform rate-limiting in the context of the HTTP request. This may be because you are performing per-user rate limits, or need to provide a back-pressure signal to the caller of your serverless workload. Because each serverless instance is stateless and has no knowledge of how many other instances may also be serving requests, you need a high-performance shared counter mechanism. Redis is a common choice for rate-limiting implementations. Read more about rate limiting and GCP, and see this tutorial for how to use serverless VPC access to reach a private Redis instance and perform rate limiting for serverless instances.
5. Use Cloud Pub/Sub to process work in batches
When dealing with a large number of messages, you may not want to process every message individually. A common pattern is to wait until a sufficient number of messages have accumulated before handling all of them in one batch. Cloud Functions integrates seamlessly with Cloud Pub/Sub as a trigger source, but serverless workloads can also use Cloud Pub/Sub as a place to accumulate batches of work, as the service will store messages for up to seven days.
Then, you can use Cloud Scheduler to handle these accumulated items on a regular schedule, triggering a function that processes all the accumulated messages in one batch run.
You can also trigger the batch process more dynamically based on the number and age of accumulated messages. Check out this tutorial, which uses Cloud Pub/Sub, Stackdriver Alerting and Cloud Functions to process a batch of messages.
6. Use Cloud Run for heavily I/O-bound work
One of the more expensive components of many infrastructure products is compute cycles. This is reflected in the pricing of many managed services which include how many time-units of CPU you use. When your serverless workload is just waiting around for a remote API call it may make to return, or waiting for a file to read, these are moments where you are not using the CPU, but are still "occupying it" so will be billed. Cloud Run, which lets your run fully managed serverless containers, allows your workload to specify how many concurrent requests it can handle. This can lead to significant increases in efficiency for I/O bound workloads.
For example, if the work being done spends most of its time waiting for replies from slow remote API calls, Cloud Run supports up to 80 requests concurrently on the same serverless instance which shares the use of the same CPU allocation. Learn more about tuning this capability for your service.
When to use which strategy
After reading the above, it may be clear which strategy might help your current project. But if you are looking a little more guidance, here’s a handy flow-chart.
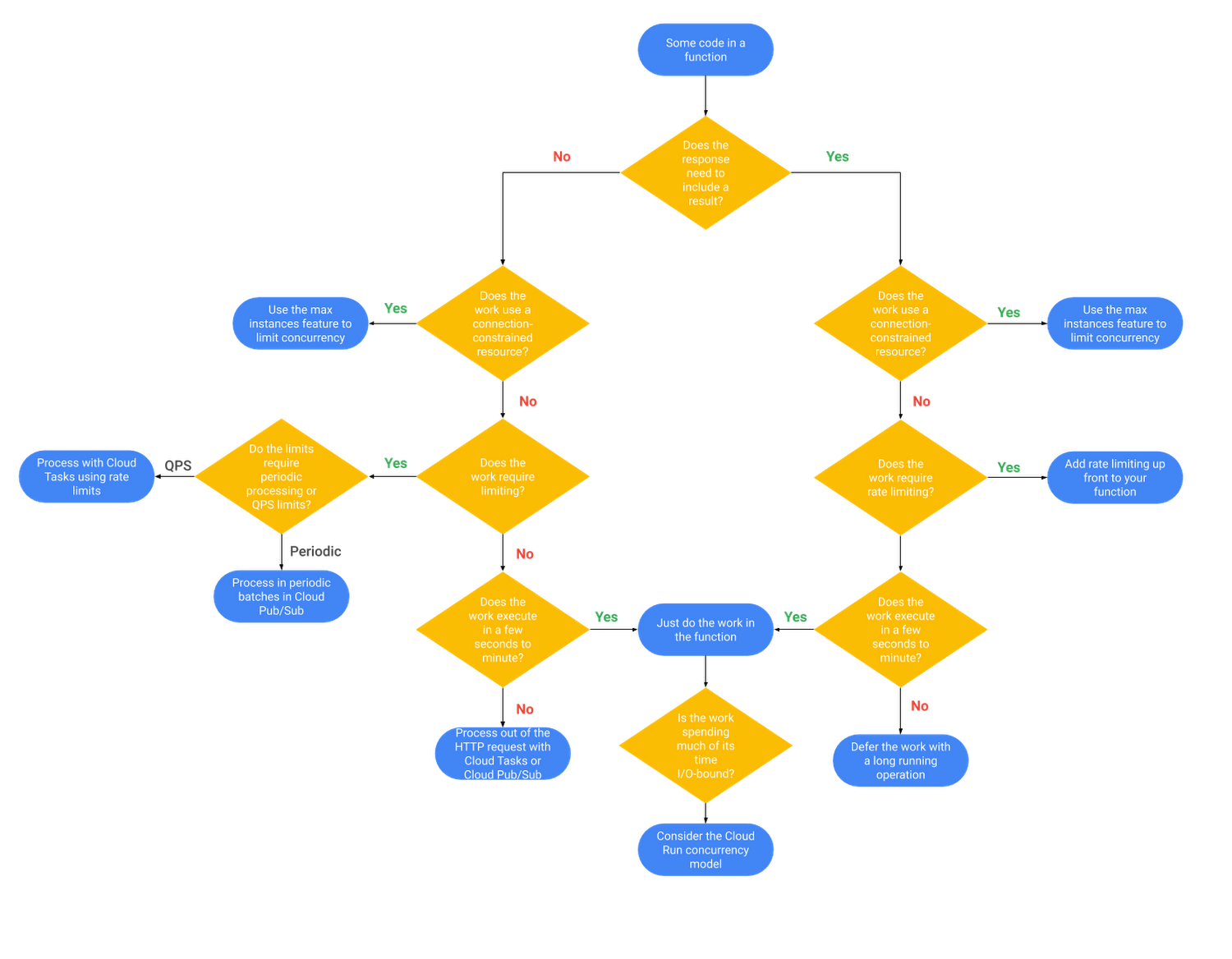
Of course you might choose to use more than one strategy together if you are facing multiple challenges.
Just let it scale
Even if you don’t have any scaling problems with your serverless workload, you may still be uneasy, especially if this is your first time building software in a serverless environment—what if you’re about to hit some limit, for example? Rest easy, the default limits for Google Cloud serverless infrastructure are high enough to accomodate most workloads without having to do anything. And if you do find yourself approaching those limits, we are happy to work with you to keep things running at any scale. When your serverless workload is doing something useful, more instances is a good thing!
Serverless compute solutions like Cloud Functions and Cloud Run are a great way to build highly scalable applications—even ones that depend on external services. To get started, visit cloud.google.com/serverless to learn more.




{kind=link}