Visualizing the mechanics of on-demand pricing in big data technologies
Tino Tereshko
Product Manager, Google BigQuery
Welcome back! If you’ve been reading our brand new Big Data Blog, you may have seen us finish a 4 Terabyte query in 30 seconds, you may have read about all the technologies that make up the BigQuery service, and you probably used our discussion on how big data technologies scale as a powerful sleeping aid.
In this blog post, we'll talk about the economics of big data — how resources are deployed, utilized and paid for. What happens when resource utilization is low? What happens when analytics demands exceed availability of resources? How can cloud-native technologies claim to be both inexpensive and fast at the same time? What about for large-scale deployments?
Resources, resources, resources…
To help our argument, let’s define an umbrella term — resources. Resources can mean CPU, RAM, networking, coordination software and anything else that goes into giving databases the power to execute analytics in SQL. Let’s also assume for a moment that all analytics technologies consume roughly equal amounts of resources for specific workloads, and that workloads are perfectly parallelizable. Let’s also call them all databases, fully aware that the term is stretched for various Hadoop and Spark use cases, among others.Now let’s plot resources versus time:
Fantastic! An empty chart is rarely entertaining, so let’s deploy a big data cluster. We could pick an open source technology like Hadoop, Spark or Presto; alternatively, we can deploy a proprietary database like Redshift or Vertica. We can even truck in a refrigerator-sized big data appliance!
In order to deploy this cluster, we must allocate a certain amount of resources — some number of nodes, instance types and instance sizes. On this chart, we can represent this deployment process by drawing a horizontal line at some resource point:
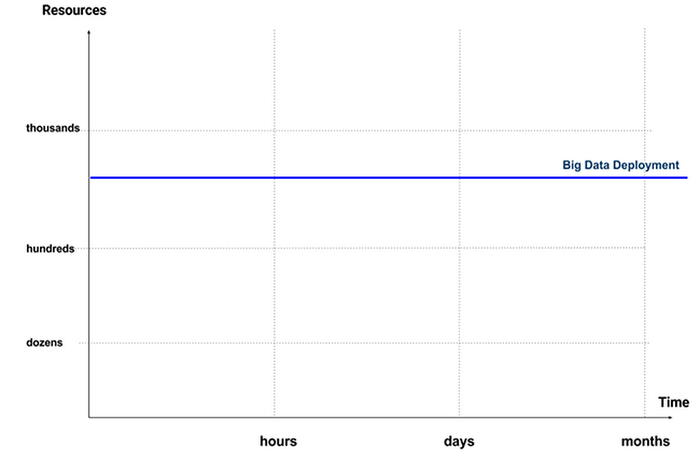
We now have an analytics cluster, hopefully very large, distributed, redundant and highly available. The actual amount of resources is not too relevant to our discussion, so let’s just assume that the cluster is very large.
How do we pay for this analytics cluster? We pay for all the aggregate resources that make up the cluster, ignoring perpetual licensing and support costs. In our chart, this is the area underneath the blue line:
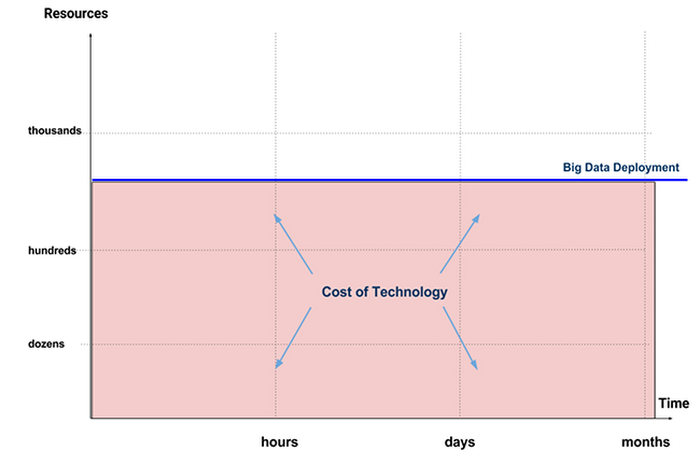
Note that we haven’t run a single query, and we’re already paying the full amount!
Let’s take a look at a typical analytics workload, which tends to be quite volatile:
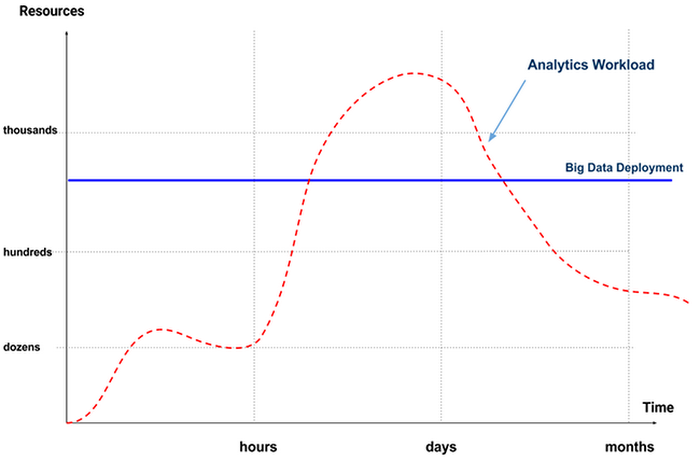
Given this sample analytics workload, what happens in the first few hours? There isn't much load on the system, so the deployment performs well. However, the cluster is vastly underutilized.
In economic terms, we're paying for the entirety of resources that we deployed, even if much of these resources remain unused. In our graph, we see that this is the area above the red line and below the blue line:
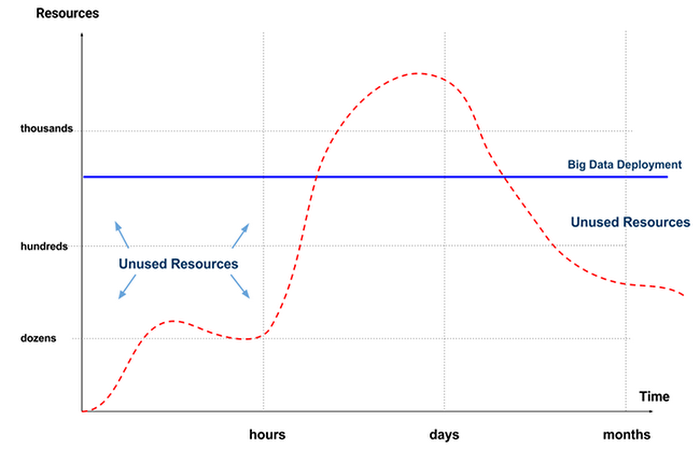
Why must we pay for these resources when they aren't used? Traditional technologies charge you for the amount of resources that you provision, rather than the resources actually utilized. All resources must be paid for, whether they’re used or not.
Throttled performance
What happens when analytic demands on our big data cluster are very high? A traditional deployment will have finite resources at its disposal, and you will not be able to exceed this amount of resources (barring autoscaling, which we discuss later on). In our graph, we simply cannot go above the blue line. Our overall performance is throttled, all jobs slow down, and we must either wait out this period or cancel some jobs to bring resource utilization back below the blue line: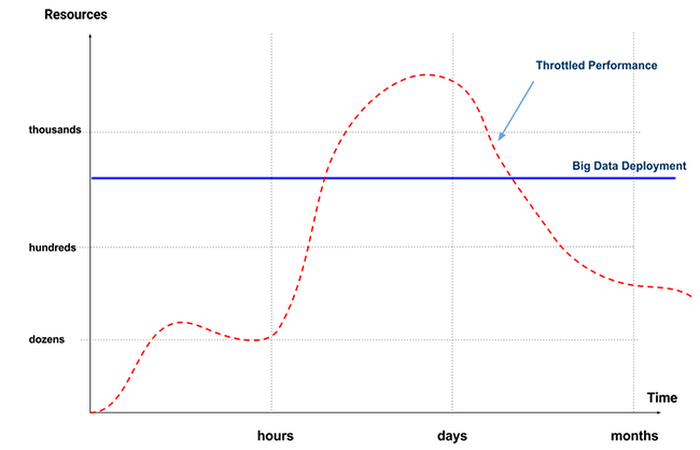
Scaling your analytics cluster
If your resource demands frequently exceed cluster size, you might need to upgrade. In a previous blog post, we discussed in great detail the effectiveness of scaling analytic technologies. The short story is, resizing analytic clusters is done rather infrequently, if ever. There are some exceptions; for example, Google Dataproc lets you resize your resources in less than 90 seconds and charges you per-minute, rather than per-hour.Generally, administrators decide that a certain higher line is now more appropriate for their business, and increases the amount of resources available:
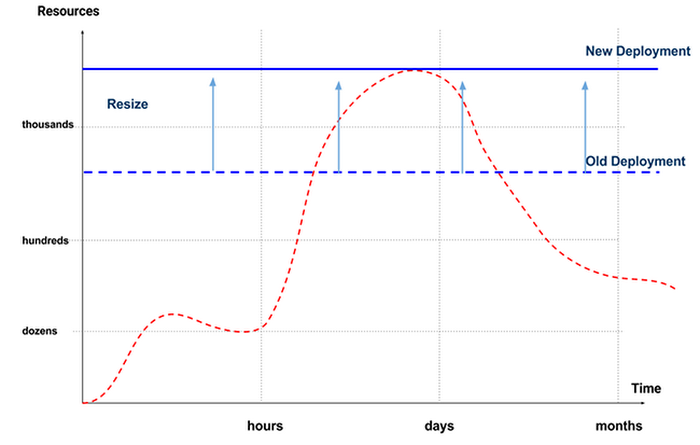
You may notice that scaling the cluster up only exacerbates the cost inefficiency — when the analytics workload is low and the big data cluster is underutilized, we end up paying more for the luxury of having a larger cluster!
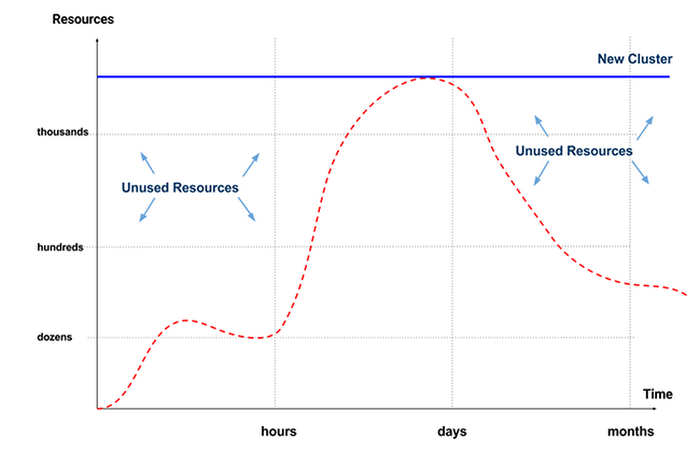
In this exercise, we’ve assumed that our analytics technology has perfect separation of storage and compute. If we're dealing with a technology where storage and compute are co-tenant, like Redshift, HDFS, and Vertica, we might have to scale our cluster simply to gain more storage space, meaning we would need to pay for even more unused compute capacity.
To quickly recap — if you get too far below the blue line, you waste money by not using the resources that you're paying for; by contrast, if you try to go above the blue line, you saturate the available resources, your performance is throttled and all your jobs slow down.
The BigQuery approach
As we previously demonstrated, BigQuery scales in seconds and charges you per-job. Therefore, BigQuery’s elasticity is fast enough to address scalability demands of ad-hoc analytics (and we can all agree that even 90 seconds is too long for ad-hoc SQL). BigQuery doesn’t require you to deploy resources and to size your cluster. Instead, BigQuery automatically contours to the demands of your analytics workloads: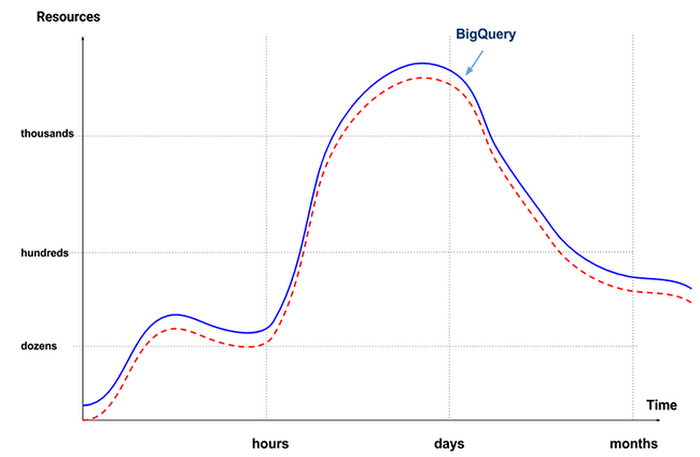
BigQuery utilization matches analytics demands one to one. By definition, BigQuery carries 100% utilization, which means that no resources go idle, and you don’t pay a premium for resources that you do not utilize.
Perhaps more importantly, you don't need to go through the confusing exercise of measuring your workloads, sizing your database and being asked to resize it to a different magnitude. In fact, the fully-managed, Serverless nature of BigQuery gives you the ability to not worry about resources at all. You get the benefit of a highly cost efficient database that’s always fast.
Conclusion
To recap, the following BigQuery features ensure that you don’t pay for wasted resources:- BigQuery seamlessly scales in seconds to match workload demands
- BigQuery charges just for the jobs that you run, rather than for deployed resources
- Fully-managed, Serverless service nature of BigQuery
- High availability, security and durability
- Separation of storage and compute



