Using the Cloud Natural Language API to analyze Harry Potter and The New York Times
Sara Robinson
Developer Advocate, Google Cloud Platform
Ever wanted a way to easily extract and analyze meaningful data from text? Now you can! The new Cloud Natural Language API has a feature that lets you extract entities from text — like people, places and events — with a single API call.
Let’s take the following sentence from a recent news article:
LONDON — J. K. Rowling always said that the seventh Harry Potter book, “Harry Potter and the Deathly Hallows,” would be the last in the series, and so far she has kept to her word.
I could write my own algorithm to find the people and locations mentioned in this sentence, but that would be difficult. And it would be even more difficult if I wanted to gather more data on each of the mentioned entities, or analyze entities across thousands of sentences, while accounting for mentions of the same entity that are phrased differently (e.g., "Rowling" and "J.K. Rowling").
With Cloud Natural Language API, I can analyze the above sentence with the API’s analyzeEntities method. In the response, the Natural Language API finds mention of two people (both real and fictional), and one location. It also returns the corresponding Wikipedia URL for each entity. And regardless of whether the entity is “Rowling,” “J.K. Rowling,” or even “Joanne Kathleen Rowling,” they all point to the same Wikipedia entry.
Here's the response:
Analyzing top news trends
Analyzing one sentence with the API is cool, but it’s even cooler to analyze entity trends in text over time. News data is full of entities, so I used The New York Times Top Stories API to gather data on the latest news stories. I built a Node server that calls the Top Stories API, sends the title and abstract for each article to the Natural Language API for entity analysis and inserts the associated article and entity data into a Google BigQuery table. With the entity data in BigQuery, I’ll be able to run queries to analyze entity mentions in top news and visualize the results with Google Data Studio:
Let’s dig deeper into the API’s analyzeEntities method.
In our example, we can build our NL API entity analysis request using the text of the article’s abstract:
The response is an object containing each of the entities found in our text. For each entity, we get an object with its name, type, metadata, salience and mentions. Looking at one entity from our example sentence above, let’s break down the API response:
There are eight different possibilities for entity type (detailed here), the most common being PERSON and LOCATION. In the current API, metadata returns the entity’s associated Wikipedia URL if there is one. salience refers to the importance of the entity in the given text on a [0, 1.0] scale. The mentions object returns the indexes of where the entity was found in the text.
Analyzing entity trends with BigQuery
Now that we have entities from each top story in The New York Times, let’s go one step further and look for trends in those entities for a given day or week. We can do this with BigQuery. Our first step is to insert each entity into a BigQuery table. We can use the gcloud Node client library to access BigQuery, and initialize it with the following code:Next, for each entity we can create a row with the entity data and associated article metadata:
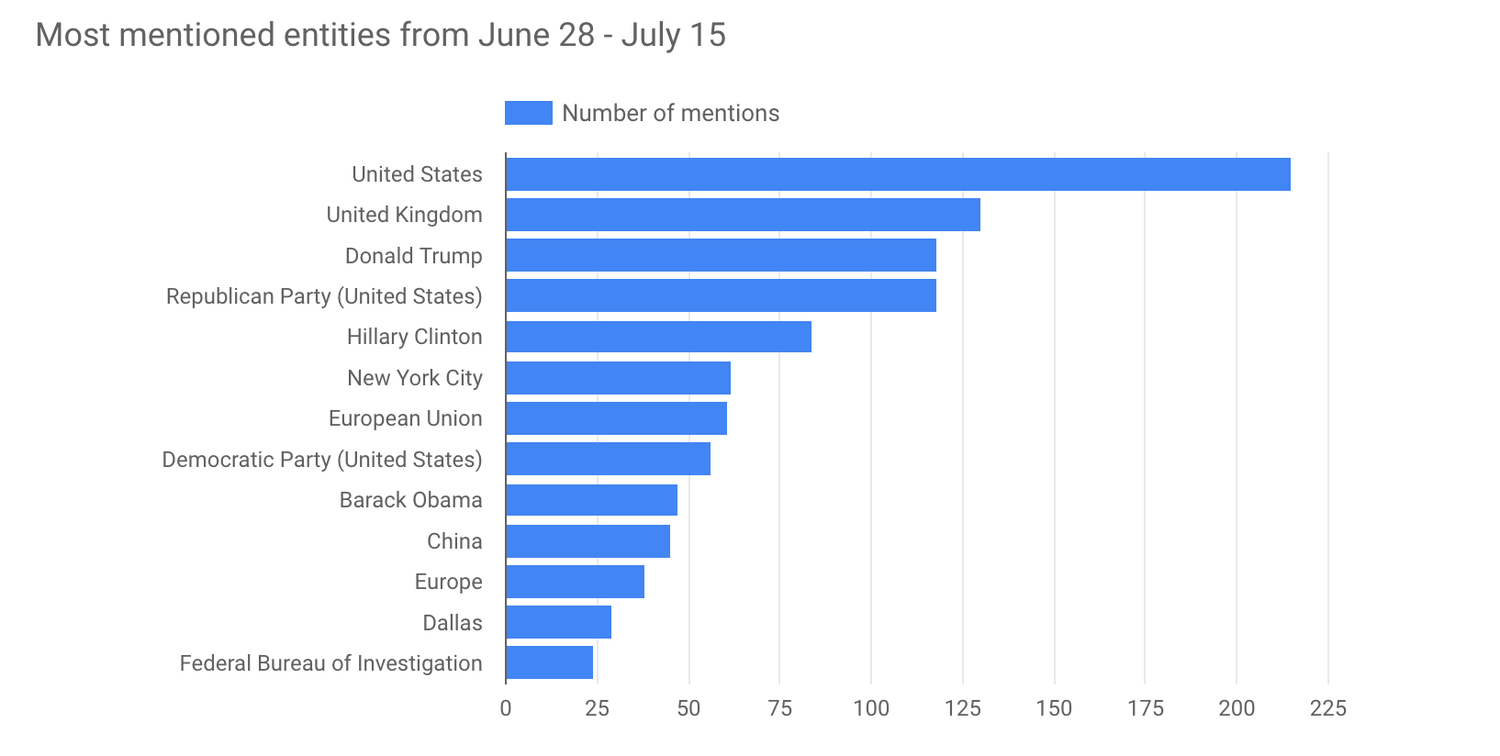
Now that the data is in BigQuery, we’re ready to analyze it! We can do this from the BigQuery web UI. First, let’s find the entities with the most mentions with this query:
Here are the results visualized with Google Data Studio.
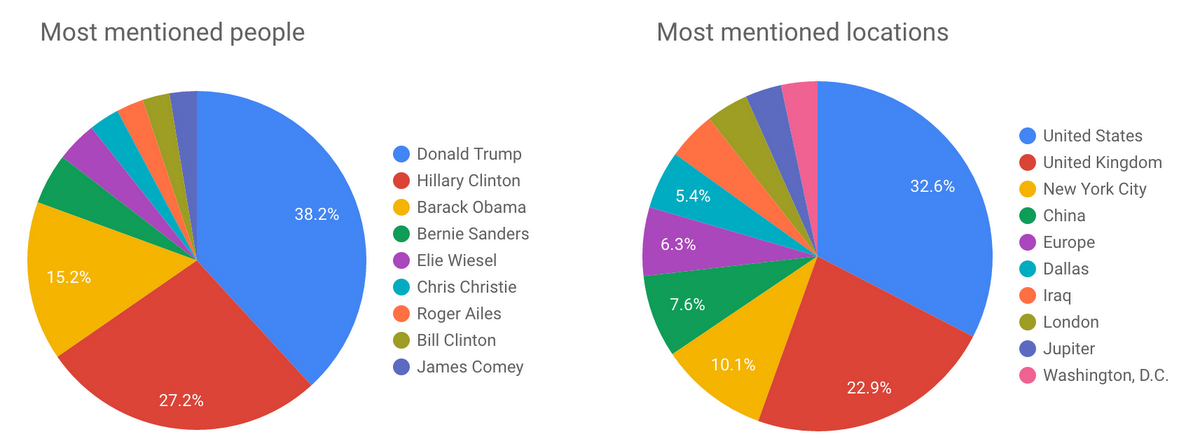
We can modify this query to filter results by the entity_type returned from the NL API to see the most mentioned locations and people in recent New York Times stories:
Sentiment analysis with the Natural Language API
In addition to extracting entities, the Natural Language API also lets you perform sentiment analysis on a block of text. The code looks the same as in the above example, we just need to change the request URL to use theanalyzeSentiment endpoint:In the response, we get an object with a double value for the polarity and magnitude of the text. Polarity is a number from -1.0 to 1.0 indicating how positive or negative the statement is. Magnitude is a number ranging from 0 to infinity that represents the weight of sentiment expressed in the statement, regardless of polarity. Longer blocks of text with heavily weighted statements have higher magnitude values. If we send this statement to the API:
I love everything about Harry Potter.
It gives us this response:
The polarity of the statement is 100% positive (indicated by the word “love”), but the magnitude of the statement is relatively low. On the other hand, with this statement:
With a new set of movies on the horizon, some fans worry that Ms. Rowling will make the same mistake that George Lucas did after the three original “Star Wars” films, producing inferior work that detracts from the brilliance of the original.
We get a more negative polarity with a lower magnitude:
Lots of negative words (“worry,” “mistake,” “inferior” and “detracts”) contribute to the negative polarity, and the overall strength of those words determine the magnitude.
Analyzing sentiment in top news stories
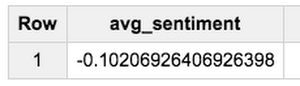
Now, let’s send the abstracts of the same articles returned from The New York Times API in the entity example to the Natural Language API for sentiment analysis. In this example, we’ll insert the result into a different BigQuery table, where each row represents an article and the polarity and magnitude values for that article’s abstract.With the following query, I can find the average sentiment of all articles by multiplying the polarity times the magnitude:
With another query, I can compare this value to the average sentiment for each section:
Here are the results visualized with Data Studio:
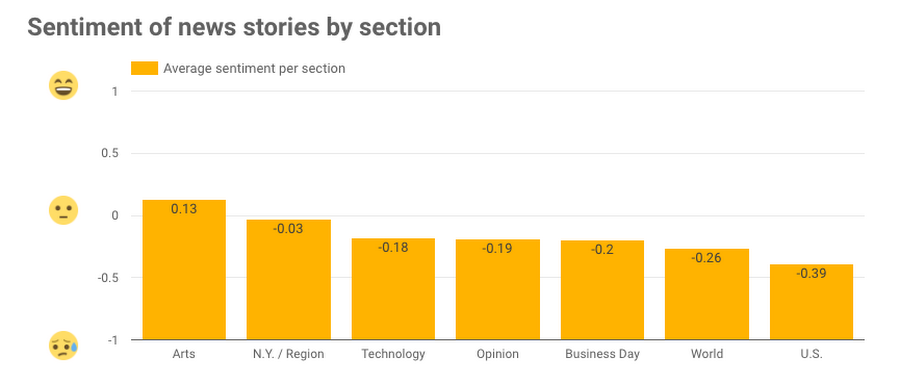
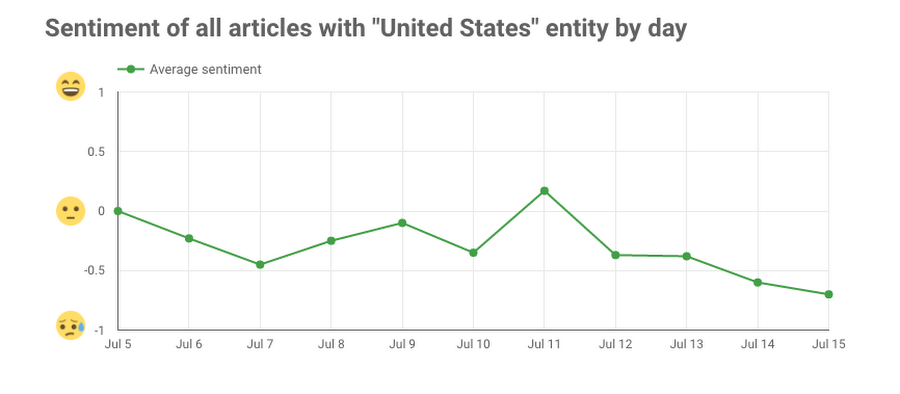
Based on this subset of news data, U.S. news has the lowest sentiment and Arts has the highest. In addition to analyzing sentiment by section, we can also use the NL API to do sentiment analysis on all article abstracts containing a specific entity. Here, we look at the average sentiment by day for all articles with the entity “United States”