Using Apache Beam and Cloud Dataflow to integrate SAP HANA and BigQuery
Babu Prasad Elumalai
Technical Program Manager, Enterprise Partner Engineering
Mark Shalda
Technical Program Manager & ML Partner Engineering Lead
SAP HANA is an in-memory columnar database that you can use either as a persistence layer for applications in the SAP ecosystem, or as an independent enterprise database.
BigQuery is Google's fully managed, petabyte scale, low-cost enterprise data warehouse for analytics. BigQuery is serverless, so you won’t need to manage any infrastructure, and you don't need a database administrator, so you can focus on analyzing data to find meaningful insights using familiar SQL. BigQuery can scan a terabyte in seconds and a petabyte in minutes. With BigQuery, you can easily scale your database size by several orders of magnitude with little administrative or operational overhead.
In this blog post, we will talk about leveraging both SAP HANA and BigQuery for your analytics needs. This integration can help you address cost optimization, high throughput performance, and low maintenance needs for your application.
Dataflow for data integration
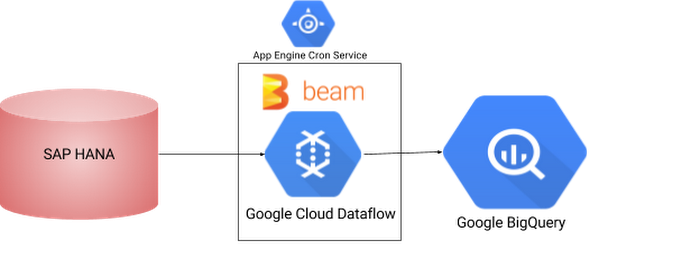
Google Cloud Dataflow makes it easy to integrate SAP HANA with BigQuery.Google Cloud Dataflow is a fully-managed service for transforming and enriching data in stream (real time) and batch (historical) modes with equal reliability and expressiveness -- no more complex workarounds or compromises needed. And with its serverless approach to resource provisioning and management, you have access to virtually limitless capacity to help solve your biggest data processing challenges, while paying only for what you use.
Cloud Dataflow supports fast, simplified pipeline development via expressive Java and Python APIs in the Apache Beam SDK, which provides a rich set of windowing and session analysis primitives as well as an ecosystem of source and sink connectors. Plus, Beam’s unique, unified development model lets you reuse more code across streaming and batch pipelines.
Apache Beam SDKs provide a JDBC implementation to read and write data from data sources. This implementation can be used to connect to and read data off of SAP HANA. In this blog, we will demonstrate code that will read data and process the data read from SAP HANA using Google Cloud Dataflow engine and write to Google BigQuery. The code can also be customized to incrementally extract data using a timestamp column in the SAP HANA table by providing a WHERE clause (see below) in the SQL definition.

Scheduling the pipeline
We have created a process that can extract data from SAP HANA and copy it over to Google BigQuery. Once you have tested that this job runs successfully, you might automate this by scheduling it so you do not have to run it manually every time.You can use App Engine Cron Service to achieve this. App Engine Cron Service allows you to configure and run cron jobs at regular intervals. These cron jobs are a little different from regular Linux cron jobs in that they cannot run any script or command. They can only invoke a URL defined as part of your App Engine app via HTTP GET. In return, you don’t have to worry about how or where the cron job is running. App Engine infrastructure ensures your cron job runs at your preferred, intended interval.
You should refer to this blog for additional details on how to configure a servlet and deploy it on App Engine.
Code snippets and implementation
Now that we have conceptually defined a few useful pipelines, let’s walk through the code required to build the integration.The following code uses the built-in Apache Beam JdbcIO source class to read in data from SAP Hana. In order to do this, we had to provide the ngdbc.jar file from the SAP Hana client download library as our jdbc driver. We used the following command to install it with maven:
mvn install:install-file -Dfile=ngdbc.jar -DgroupId=sap -DartifactId=sap-hana-jdbc -Dversion=1.0 -Dpackaging=jar -DgeneratePom=true
And then used the following maven dependency in our pom.xml file:
Once this was setup, we could use the necessary com.sap.db.jdbc.Driver class to access the SAP Hana instance from our Beam Java pipeline. Our implementation used a parameterized query and a row mapper function. The row mapper allows us to prepare our data to be serialized and used throughout our pipeline. In this case, we are using a custom AutoValue class to package up the column values to be used later when creating our entry into BigQuery.
The parameterized query allows us to use a parameter setter to create multiple queries to chunk our data read operation so that we can scale in a more efficient manner.
We then make whichever Beam transformations we want on our data, but in this case we will simply take our custom DBRow object and convert it to a BigQuery TableRow object that can be used by the BigQueryIO sink in Beam. So for that, we create a custom DoFn which will extract each data field in the correct order and put them in the BigQuery TableRow object and then emit the result.
Now we can create our pipeline using our new PTransform and DoFn. We first manually create a PCollection of Strings that indicate how we will chunk up our input and then apply our PTransform and DoFn in order. Lastly, we utilize the BigQueryIO class to write our PCollection of TableRows.
We can also connect manually to Hana outside of the pipeline operation to grab our table schema so that we could provide this to BigQuery in case it was needed.
The full and most up to date version of the code is available from a public git repository here.
Final output
To run our pipeline, we use Maven to automate our build and execution. We pass some parameters to our program which specify some information regarding how and which table to access from our SAP Hana instance and where in BigQuery we should store the data when transferred. Since we are going to use the Cloud Dataflow execution engine to run our Apache Beam code, we also need to pass in some additional parameters which tell the Dataflow Runner class where it can store files for staging and temporary purposes and what project it can use to run.We’ve omitted a lot of the maven details, but you can see that the program logs the simple SQL query it will run to pull data from Hana, along with some information about how to check the progress of our pipeline in our GCP Console and the execution time to deploy the pipeline.
Following that link brings us to the Cloud Dataflow UI, which gives us a visual display of our pipeline, plus useful information about its execution.
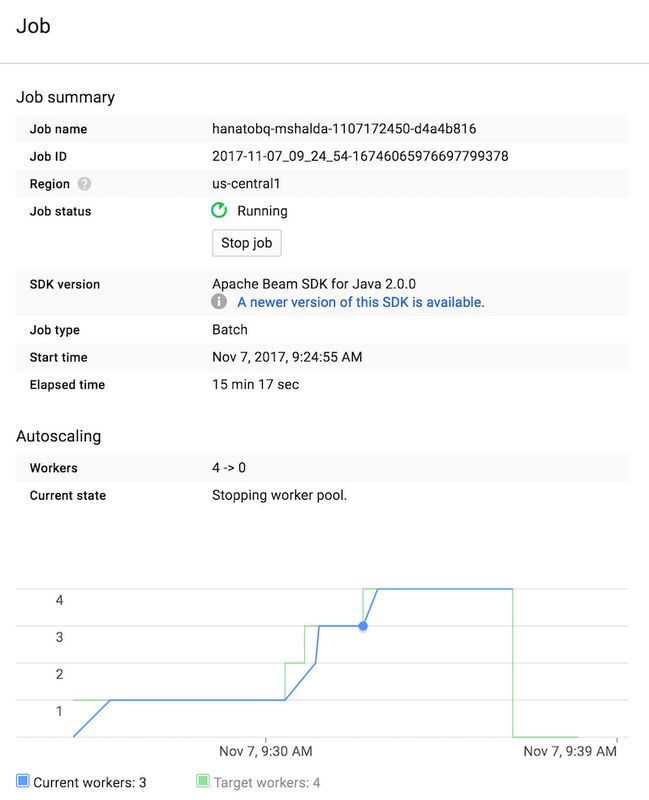
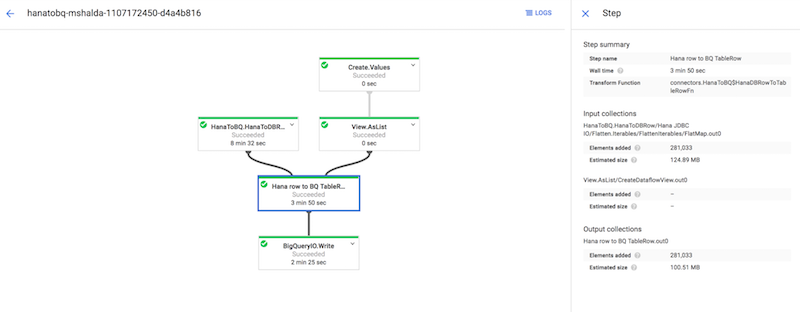
The screenshots from the UI were taken after the pipeline finished executing. From it, we can gather a lot of information like execution time, worker scaling, size of the data in and out of the pipeline and other helpful metrics.
There is a lot more work to be done to make this pipeline robust and performant but this gives an initial look at how a tool like Apache Beam and Cloud Dataflow can be used to create a cost effective and usable data environment.
Caveats
The code provided here allows you to extract data from SAP HANA and does not throttle the reads from SAP HANA. You should first test this code on your development environment and understand the impact. If you choose to run this on your production database, you should run it during periods of low activity to avoid any regression.You should work with SAP to understand if there are any licensing implications to extracting data from SAP HANA into a third party data store like Google BigQuery.
Currently the pipeline requires a timestamp column (or really any sort of numeric value) and a start value and end value so that you can extract a portion of your data. We do envision that this will be a major use case, but also given that JdbcIO’s does not parallelize the query, any query of significant size could cause a single worker to go out of memory. Future work on the repository will aim to accept just a column that can be used to partition the data into chunks that can be parallelized across multiple workers to read in larger sets of data.



