Three steps to Compute Engine startup-time bliss: Google Cloud Performance Atlas
Colt McAnlis
Developer Advocate
Scaling to millions of requests, with less headaches, is one of the joys of working on Google Cloud Platform (GCP). With Compute Engine, you can leverage technologies like Instance Groups and Load Balancing to make it even easier. However, there comes a point with VM-based applications where the time it takes to boot up your instance can be problematic if you’re also trying to scale to handle a usage spike.
Before startup time causes woes in your application, let’s take a look at three simple steps to find what parts of bootup are taking the most time and how you can shorten your boot time.
Where does the time go?
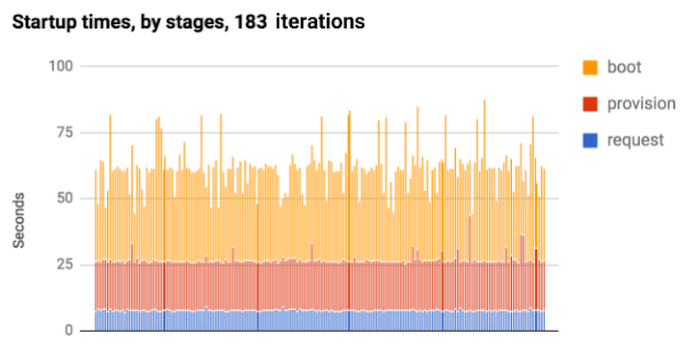
One of the most important first steps to clearing up your startup time performance is to profile the official boot stages at a macro level. This gives you a sense of how long Compute Engine is taking to create your instance, vs. how much time your code is taking to run. While the official documentation lists the three startup phases as provisioning, staging and running, it’s a little easier to do performance testing on request, provisioning and booting, since we can time each stage externally, right from Cloud Shell.- Request is the time between asking for a VM and getting a response back from the Create Instance API acknowledging that you’ve asked for it. We can directly profile this by timing how long it takes GCP to respond to the insert instance REST command.
- Provisioning is the time GCE takes to find space for your VM on its architecture; you can find this by polling the Get Instance API on a regular basis, and wait for the “status” flag to change from “provisioning” to “running.”
- Boot time is when your startup scripts, and other custom code, executes; all the way up to the point when the instance is available. Fellow Cloud Developer Advocate Terry Ryan likes to profile this stage by repeatedly polling the endpoint, and timing the change between receiving 500, 400 and 200 status codes
Profiling your startup scripts
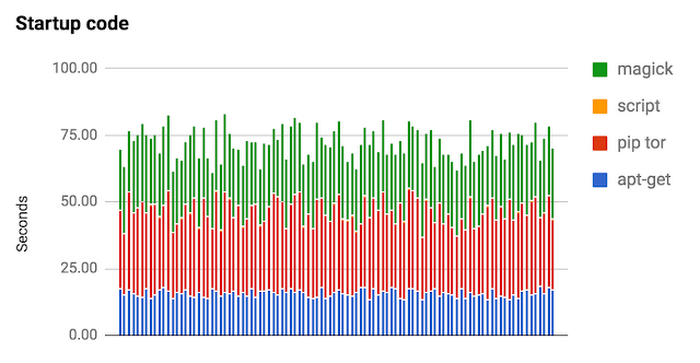
Barring some unforeseen circumstance, the majority of boot-up time for your instances usually happens during the boot phase, when your instance executes its startup scripts. As such, it’s extremely helpful to profile your boot scripts in order to see which phases are creating performance bottlenecks.Timing your startup scripts is a little trickier than it may seem at first glance. Chances are that your code is integrated into a very powerful tooling system (like Stackdriver Custom Metric API, statsd or brubeck) to help you profile and monitor performance. However applying each one to the startup scripts can create a difficult interaction and boot time overhead, which could skew your profiling results, thus making the testing meaningless.
One neat trick that gets the job done is wrapping each section of your startup script with the SECONDS command (if you're on a linux build), then append the time elapsed for each stage to a file, and set up a new endpoint to serve that file when requested.
This allows you to poll the endpoint from an external location and get data back without too much heavy lifting or modification to your service. This method will also give you a sense of what stages of your script are taking the most boot time.
Moving to custom images
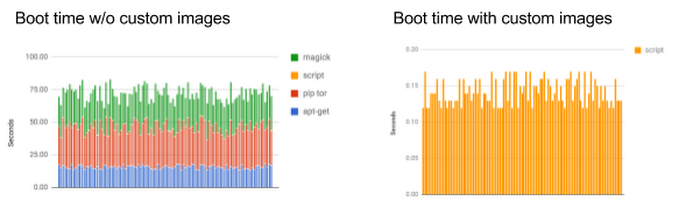
For most developers, most of the time that a startup script runs is bringing down packages and installing applications to allow the service to run properly. That’s because many instances are created with public images — preconfigured combinations of OS and bootloaders. These images are great when you want to get up and running fast, but as you start building production-level systems, you’ll soon realize that the large portion of bootup time is no longer booting the OS, but the user-executed startup sequence that grabs packages and binaries and initializes them.You can address this by creating custom images for your instance. Create a custom image by taking a snapshot of the host disk information (post-boot and install), and store it in a distribution location. Later, when the target instance is booted, the image information is copied right to the hard drive. This is ideal for situations where you've created and modified a root persistent disk to a certain state and would like to save that state to reuse it with new instances. It’s also good when your setup includes installing (and compiling) a number of big libraries, or pieces of software.
Every millisecond counts
When you’re trying to scale to millions of requests per second, being serviced by thousands of instances, small change in boot time can make a big difference in costs, response time and most importantly, the perception of performance by your users.If you’d like to know more about ways to optimize your Google Cloud applications, check out the rest of the Google Cloud Performance Atlas blog posts and videos because when it comes to performance, every millisecond counts.



