Google Cloud
Spotify’s experiments with stream processing on Google Cloud Dataflow
March 11, 2016
Tino Tereshko
Product Manager, Google BigQuery
Yesterday, Spotify engineer Igor Maravić released the third and final blog post in a series that talks about Spotify’s experience implementing streaming pipelines using Google Cloud Dataflow, and prototyping the solution so far. Of note:
- Lessons learned working with the unified batch and stream processing model offered by Cloud Dataflow
- Dataflow’s concepts of window and watermark to work with late arriving data
- Performance and scalability of running Dataflow pipelines
- Plans to mature Spotify’s Pub/Sub - Dataflow architecture to production
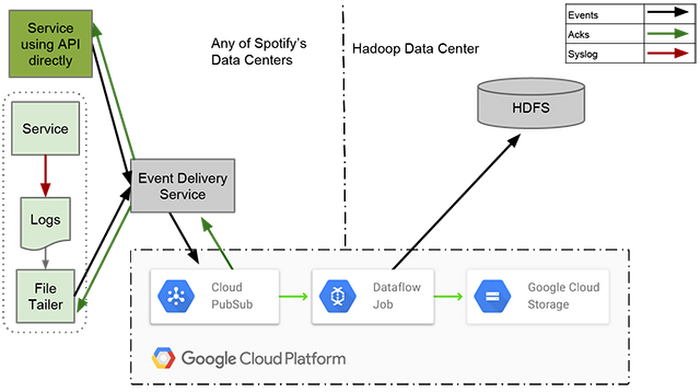
Two weeks ago, Igor shared details with us about Spotify’s existing event delivery architecture, largely based on Kafka, HDFS. and Crunch-MapReduce.
You can find Igor’s latest blog post and the previous two posts in this series on the Spotify Engineering blog.



