Predicting community engagement on Reddit using TensorFlow, GDELT, and Cloud Dataflow: Part 2
Sergei Sokolenko
Cloud Dataflow Product Manager
In Part 1 of our blog series, we combined traditional NLP techniques, such as topic extraction; and deep learning techniques, such as embeddings, to preview TensorFlow models that predicted with 92% accuracy which Reddit community (subreddit) a news article would land in for discussion. We then estimated the popularity score and volume of comments such a post would generate. In this blog, we go into detail of developing and tuning these models.
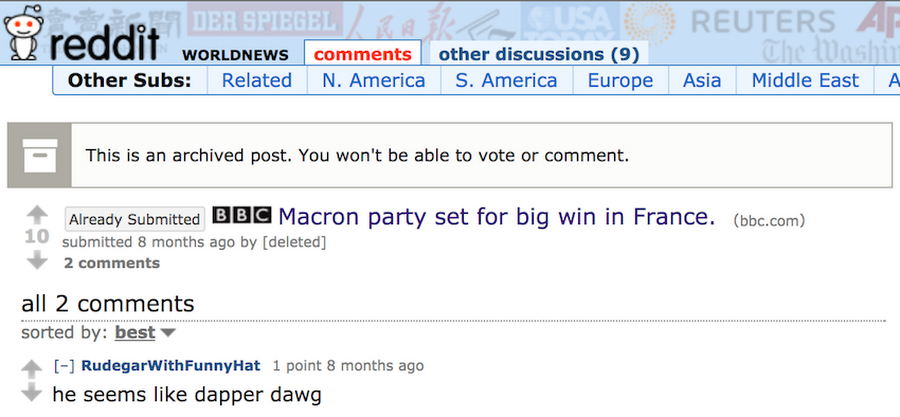
As a reminder, we sourced our data from GDELT’s catalog of news coverage and Reddit discussion threads. These are both available as BigQuery datasets (here and here). GDELT has the features (the inputs) for our training model, and Reddit has the labels (the outputs) for our predictions. GDELT indexes articles by the article URL and has attributes such as the author, publication date, the full content of the article, etc. Reddit also has the article URL and provides the submitter of the article, the subreddit (topic area), the popularity score, and all of the user-created comments on the submission. Here is an example of a news article posted to the worldnews subreddit. It’s popularity score is 10, and it gathered 2 comments from Reddit users.
Predicting subreddit selection
As we shared in Part 1, our hunch is that the content of article and where it was published plays a role in piquing the interest of a Reddit user, and her subsequent selection of the subreddit where she will post it for discussion. In short, we expect the following predictors and outcomes:| Predictor | Predictor | Outcome | Outcome |
| WHERE PUBLISHED | WHAT ABOUT | WHO POSTED | WHICH COMMUNITY |
| Domain | Tags, GDELTEntities | Submitter | subreddit |
In Part 1, we also explained Sirocco Tags and GDELT Entities features of our model—they are the result of traditional text summarization on article copy, further encoded as multi-dimensional vectors for easier processing in deep learning models.
Let’s evaluate how well the Sirocco Tags and GDELT Entities embeddings work for our prediction task. The following cell runs the TensorFlow model that predicts subreddits based just on the Tags.
The model includes a Bag-of-Concepts InputLayer/Embedding/Flatten layers (see Part 1), followed by a densely connected layer with 500 neurons, a dropout layer, and connection to an output layer “subreddit_output” for subreddit predictions. Here are the model training stats:
Using just the Tags results in a low 22.5% accuracy for subreddit prediction, but this is not necessarily a disappointing outcome. A closer look at the our Reddit dataset reveals the same news article can be posted by multiple Reddit users into different subreddits. This means that the same Tags value can be associated with multiple subreddits. Looking only at the top predicted class for a specific subreddit unnecessarily penalizes our model.
For this reason, we have also chosen to track the “Top 5 Accuracy” metric, which represents the percentage of test dataset samples where the true label fell within the top 5 predicted classes generated by the model. According to this metric, our model has a 54.2% Top 5 Accuracy.
| Model | Top 1 Accuracy | Top 5 Accuracy |
| Inputs=’Tags’ Output=’Subreddit’ | 22.5% | 54.2% |
Let’s look at some of these predictions. The following cell will print one example per case type:
Here is a sample prediction:
Here, tags “digital_currency virtual_currency tokyo_stock_exchange bitcoin_exchange” led to class predictions related to Bitcoin. Class probabilities can be found in brackets and sum up to 100% over all 150 classes that were found in our dataset. The Actual Label, meaning the subreddit where this news article was posted, was “BitcoinAll”, predicted class #3.
Let’s run another model that uses GDELT entities encoded as a Bag-of-Concepts:
With this model we gained 2.4% in Top 1 Accuracy and 3% in accuracy for Top 5 predictions:
| Model | Top 1 Accuracy | Top 5 Accuracy |
| Inputs=’BOWEntitiesEncoded’ Output=’Subreddit’ | 24.9% | 57.2% |
Let’s see if we can do better than 57% accuracy and add Domain as one of the inputs:
Our model now combines an embedded input (`BOWEntitiesEncoded`) and a categorical input (Domain) that are then concatenated and connected to a Dense layer with 500 neurons. We gained 12.2% in Top 1 accuracy, and 16.7% in Top 5 Accuracy.
| Model | Top 1 Accuracy | Top 5 Accuracy |
| Inputs= ’BOWEntitiesEncoded’,‘Domain’ Output=’Subreddit’ | 36.6% | 73.9% |
Follow the Reddit post URLs below to see for yourself if our predictions make sense.
What have we learned so far? At the beginning of this blog, we posed a hypothesis that the publication domain and the contents of news articles influence the selection of the subreddit by Reddit users (submitters). We were able to achieve a 74% accuracy in our predictions of subreddit, but so far we ignored another interesting prediction outcome: the post submitter.
Multi-output models
Keras makes it really simple to define a TensorFlow model that has two output predictions:The model looks like this:
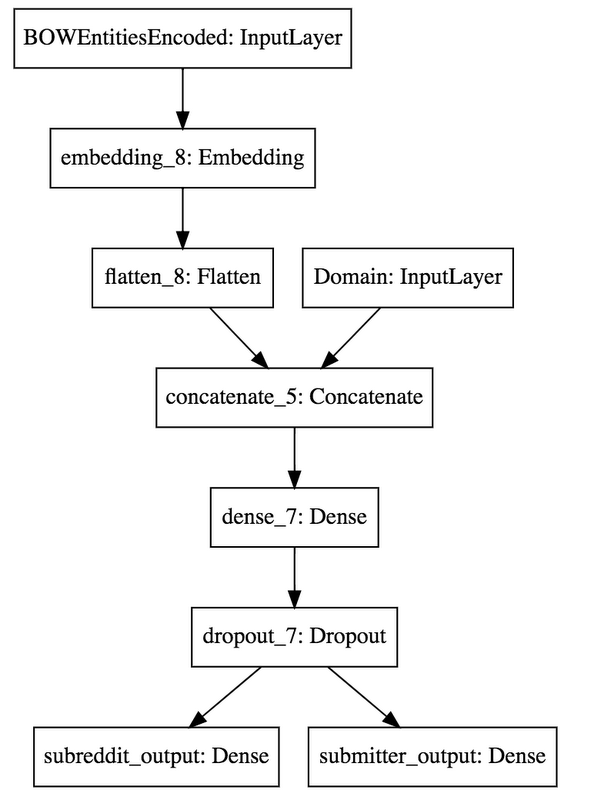
The output of training gives us the accuracy and loss scores for our test dataset.
Summarized, adding the second output actually pulled the Top 1 Accuracy of the first output up by +0.9% to 37.3% (although the Top 5 Accuracy barely budged +0.1% to 74.0%). The accuracy of the submitter output was moderately high (at 69.1%).
| Model | Top 1 Accuracy | Top 5 Accuracy |
| Inputs=’BOWEntitiesEncoded’, ‘Domain’ Output= ’subreddit’, ‘RedditSubmitter’ | subreddit 37.3% (+0.9%) Submitter 33.4% | subreddit 74.0% (+0.1%) Submitter 69.1% |
What else can we do to increase the accuracy of our subreddit predictions? So far, we’ve been looking at our input dataset from the perspective of a Reddit post, meaning each post was treated as a separate sample, regardless of whether the underlying news article was posted into another subreddit. We were aware of this frequent cross-posting, and hence looked at the Top 5 accuracy metric as a measure of our modeling success. Other than that, we made no adjustments to the model. Our training data maintained the format shown in the following table:
| BOWEntitiesEncoded | Domain | subreddit | Submitter |
| 12 453 22 ... 6544 12 | businessinsider.com | neutralnews | reddituser1 |
| 12 453 22 ... 6544 12 | businessinsider.com | worldnewshub | reddituser2 |
Multi-label classification
There is a better technique for predicting outcomes that are sets of classes, called Multi- Label Classification. To implement it, one needs to prepare the output labels as N-hot encoded vectors. For example, if we have 150 classes that are the possible outcomes of the prediction, and a particular set of inputs has class #44 and class #75 as outcomes, then this sample record needs to be encoded as an array of zeros in all indexes except in positions 44 and 75.| 0 | 0 | .. | 1 | .. | .. | 1 | .. | 0 | 0 |
We created a handy function that uses the Keras Tokenizer to create N-hot encoded vectors.
In addition to N-hot encoding the outputs, we also need to change our loss function from categorical_crossentropy to binary_crossentropy, and change the output activation from softmax to sigmoid. This will ensure that the probabilities the model will produce for each predicted class are independent from each other. Review the _create_subreddit_model function in our notebook for its implementation.
The last step in converting our model to a multi-label classification problem is changing our dataset to aggregate subreddits and submitters by the news article. Instead of two samples for our news article, as in the table above, we need to have just one, with subreddits and submitters represented as lists. Our training data needs to look like this:
| BOWEntitiesEncoded | Domain | subredditList | SubmitterList |
| 12 453 22 ... 6544 12 | businessinsider.com | neutralnews, worldnewshub | reddituser1, reddituser2 |
After running the above code, we get the following results:
Our train dataset is now more compact—we have 64,000 train samples vs the 110,000 we had previously—the result of grouping by news article. The accuracy metrics are amazing: Top 1 Accuracy of 99.2% and Top 5 Accuracy of 83.1%! However, it is still too soon to declare victory.
Since we changed our loss function and our output activation from softmax to sigmoid, the old accuracy metrics that applied previously are no longer representative. In multi-label classification, different accuracy metrics need to be used. Hamming loss represents the fraction of labels that are incorrectly predicted. Ranking loss averages over the samples the number of label pairs that are incorrectly ordered, i.e. true labels have a lower probability than false labels.
Let’s check how well our multi-label prediction model performs according to these metrics:
Our model now shows the following accuracy scores:
| Model | Multi-Label classification accuracy |
| Model type = Multi-Label Inputs=’BOWEntitiesEncoded’, ‘Domain’ Output=’subreddit’ (Multi-Label) | Top 5 Accuracy of 83.1% (just to compare to Single-Label models) Total correctly predicted: 4391 out of 17683 (absolute accuracy: 0.248) Hamming loss: 0.014 Label ranking loss: 0.031 |
The model accurately predicted 24.8% multi-label outcomes for our test dataset of 17,700 samples, meaning a perfect match for true positives and true negatives, and no false positives or false negatives. Considering that we have 150 subreddits we are predicting against, qualifying for a perfect match meant the model had to predict 1s only where there were posts to the corresponding subreddit, and 0s for all other subreddits. It’s 150 values to get right!
Hamming loss was 0.014, meaning that only 1.4% predicted 1s or 0s were incorrect, and Ranking loss was 0.031 , meaning that only 3.1% of labels had incorrectly ordered probabilities. These are pretty good numbers, but there is a catch: our model has 150 possible subreddit classes, and most news articles are posted to a small number of subreddits. Our n-hot vectors are sparse - they are full of 0s and have only a few 1s in them. All these (correctly) predicted 0s are driving Hamming loss and Ranking loss artificially low.
A correct prediction of a 1, a true positive, for a subreddit is more valuable to us than the correct prediction of a 0, a true negative. We have decided to calculate stats for true positive and true negative distributions, and pivot them by the number of subreddits per sample.
Here is the output:
| Number of subreddits per News Post | 100% Perfect Match | 50%+ True Positives | 1-49% True Positives | 0% True Positives | Number of Samples | Percent of Total |
| 1 | 3,939 | 4,229 | 0 | 3,772 | 11,940 | 68% |
| 2 | 346 | 1,999 | 0 | 742 | 3,087 | 17% |
| 3..4 | 102 | 961 | 544 | 288 | 1,895 | 11% |
| 5..8 | 4 | 263 | 321 | 60 | 648 | 4% |
| 9..16 | 0 | 23 | 82 | 3 | 108 | 1% |
| 17..32 | 0 | 0 | 5 | 0 | 5 | 0% |
| Total | 4,391 | 7,475 | 952 | 4,865 | 17,683 | 100% |
| % of Ttl | 25% | 42% | 5% | 28% | 100% |
For example, among the 648 news articles with 5 to 8 subreddits each, the model was able to make 4 perfect predictions (100% True Positive and True Negative). A more common prediction for this kind of test samples was one or more correct subreddits (but not all). Let’s look at test sample #8945, one of these four perfect matches.
Running this cell:
Returns the following output (feel free to explore the Reddit posts and the news article links):
Overall, we made 24.9% perfect multi-label predictions, 42.2% predictions with more than half true positives, 5.4% predictions with at least 1 true positive, and 27.4% predictions where we weren’t able to predict any true subreddits. In other words, we made at least one correct subreddit prediction in 72.6% of test cases.
Another way to look at the quality of our multi-label model is to evaluate the recall and precision for each individual class, or subreddit (look for the calc_multilabel_precision_recall function in our notebook). Recall is a measure of how exhaustive our predictions are compared to the actual subreddits, the ground truth. Precision, on the other hand, gives an indication of how many true positives were among the predictions we made. These two measures tend to work against each other, so a single “F1 score” metric is also used, representing a harmonized mean of precision and recall. The following chart shows 13 subreddits (out of 150 predicted by the model) of different F1 score bands:
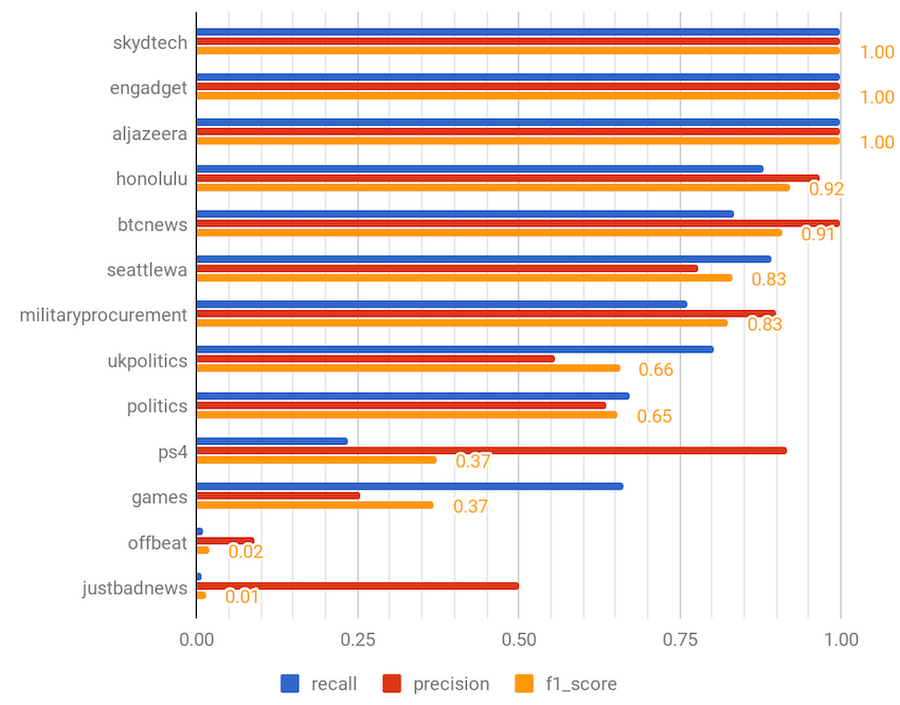
The first 3 subreddits with the perfect 1.0 F1 score and 100% precision and recall are examples where the domain input variable dominates the model. SkydTech posts articles from a small number of technology-focused domains (Ars Technica, etc.), and the Engadget and Al Jazeera subreddits are populated by newsbots that are just reposting news articles from their respective domains. Earlier in this blog, we mentioned that we excluded from analysis all news posts that were posted to autopost subreddits. The Engadget and Al Jazeera subreddits did not match our exclusion filter (‘%auto’), and so we didn’t exclude them. The precision and recall analysis is valuable because it allows us to fine tune our model and exclude such subreddits in the future.
The next batch of subreddits have high F1 scores ranging from 0.92 for Honolulu to 0.65 for politics. This can be explained by the GDELT topic extraction framework. GDELT is great at extracting locations (helping with precision and recall for such subreddits as Honolulu, ukpolitics and seattlewa) and political, economic, and conflict-related events and topics (which drives precision and recall for btcnews, militaryprocurement, ukpolitics, and politics subreddit predictions). GDELT seems to be less fine-tuned for sensing gaming and entertainment news topics, and this is reflected in the low F1 scores for ps4, games, and offbeat subreddits. One way to improve the accuracy of our model would be building an ensemble TensorFlow model where GDELT Entities would drive the prediction of one set of classes, while another input, e.g. Sirocco Tags, would predict the classes that GDELT was struggling with (e.g. gaming).
There is something about our predictors that does not allow us to push above the 70-80% accuracy. It could be because we are missing another important feature of the article in the model, or it could be because the submitter of the post, the Reddit user, exercises discretion in selecting the subreddit he posts to. We decided to add the submitter to the model, not as an output of predictions, but as an input—a predictor.
Anomaly detection model
We are going back to a multi-class, single-label prediction model, because a Reddit user would not be expected to post the same news article to multiple subreddits (although we could implement a multi-label predictor easily). We are calling this model an anomaly detection model because it allows us to answer the question: “Based on past user behavior, how probable is it that a given Reddit user will share a particular news post to a given subreddit?”. If the predicted probability is low, but the Reddit user ends up submitting this post anyway, this is an anomaly worth investigating.| Predictor | Predictor | Predictor | Outcome |
| WHERE PUBLISHED | WHAT ABOUT | WHO POSTED | WHICH COMMUNITY |
| Domain | GDELTEntities | Submitter | subreddit |
The accuracy of the results is impressive:
Compared to the last Single-label model, we gained 35% in Top 1 Accuracy to reach 72.3%, and 17.7% in Top 5 Accuracy to reach 91.7%.
| Model | Top 1 Accuracy | Top 5 Accuracy |
| Inputs=’BOWEntitiesEncoded’,‘Domain’, ‘Submitter’ Output= ’subreddit’ | subreddit 72.3% (+35%) | subreddit 91.7% (+17.7%) |
The human factor does indeed matter!
Predicting user engagement metrics
Now that we are able to predict the subreddit a news post will land in, let’s try to predict its popularity and level of engagement by the Reddit user community. Our hunch is that several of the below predictors will influence user engagement. The publication domain and the content of the article may gather a very specific readership for the post, while the submitter of the post may attract followers due to her social reputation, and the subreddit could influence user engagement because of the regular (and continuous) audience it attracts.| Possible predictors | Outcomes |
| publication domain content of the article Reddit user, submitter of the post subreddit | popularity score number of commenters number of comments |
To evaluate this theory, we will build TensorFlow models that attempt to predict the outcomes with high accuracy. Similar to our subreddit prediction model, we’ll source our data from BigQuery. This time, though, we’ll include posts created by auto posting bots, because we are equally interested in their popularity scores and the comments they gather. It also gives us a bigger dataset to train our models on. Our total dataset consists of 425K records, and from that set we randomly pick 50%, resulting in 170K train and 43K test samples.
Some of our earlier models were regression models, which attempted to predict the scores as numbers, but they suffered from non-converging loss functions and low accuracies. We decided to run distribution stats on our outcomes, and the results were eye-opening: all three user engagement metrics had exponential distributions.
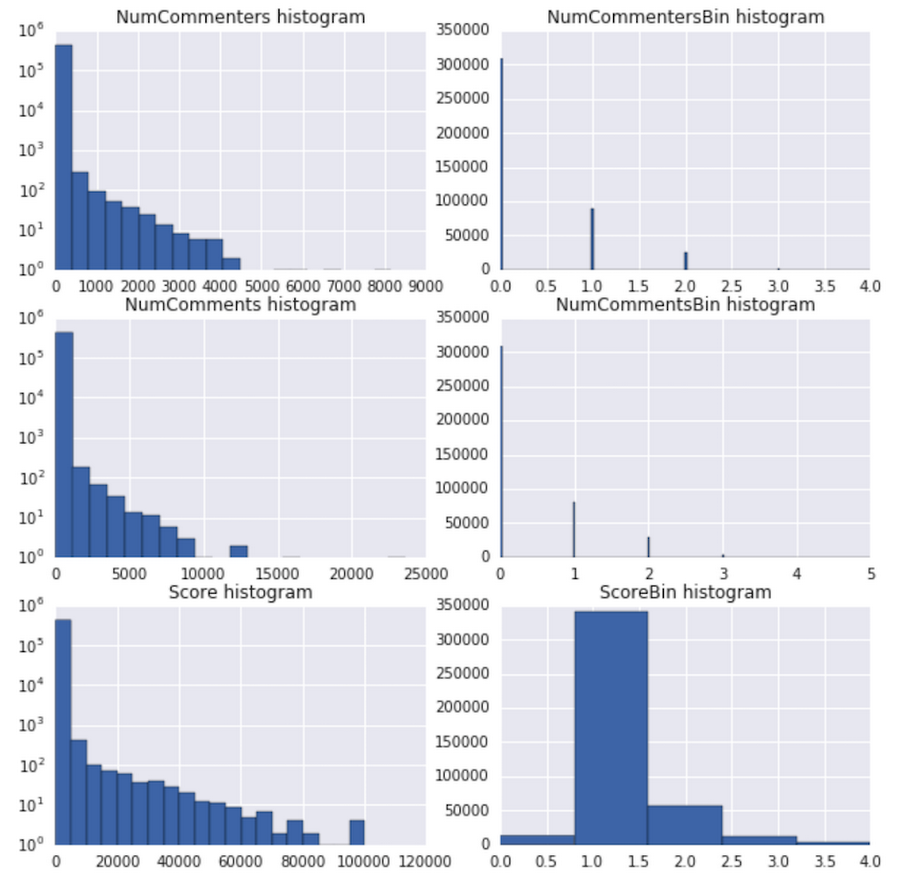
Note: Graphs on the left have a log-scale y-axis.
We therefore normalized our values using log10(x+1) scaling (see add_engineered_columns function in our notebook) and binned them into discrete classes, allowing us to do classification instead of regression. You can review the bin distributions for each of the engagement metrics in the above graph. Each bin corresponds to the following values of the original metric:
| Bin | Range of original values |
| 0 | 0 |
| 1 | 1-9 |
| 2 | 10-99 |
| 3 | 100-999 |
| 4 | 1,000-9,999 |
| 5 | 10,000-99,999 |
Our first model, with Domain and Tags as inputs, with ScoreBin and NumCommentersBin as outputs, had a pretty good accuracy for ScoreBin, at 80.3%.
However, after running a confusion matrix plot on this model, we realized that the model took the path of least resistance and predicted the `ScoreBin` value of “1” pretty much everywhere. Why? The number of samples in our training dataset with this value is dominant (~80%) and the model achieved the best accuracy by selecting “1” for every prediction. Moving forward, we’ll track how many classes we predicted well with each model.
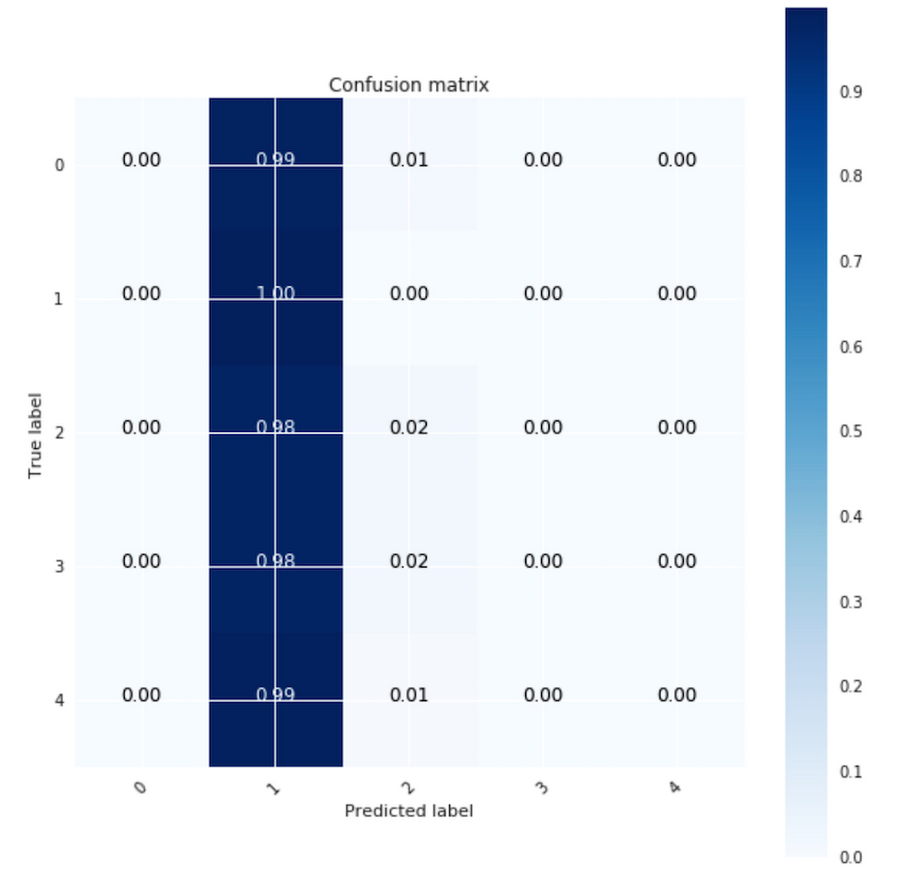
| Model | Top 1 accuracy | Well predicted classes |
| Inputs= ‘Domain’,’Tags’ Output=’ScoreBin’,’NumCommentersBin’ Without Weights | ScoreBin: 80.3% NumCommentersBin: 74.6% | ScoreBin: 1 (Bin 1) |
To improve the quality of our predictions, we assigned to each sample a weight that was the inverse of the frequency of its class (a square root of the frequency, actually, to reduce but not completely eliminate the importance of large classes):
Then, we enabled sample_weight usage in our Keras model:
There is now more variety in the confusion matrix, but most classes except Bins 1 and 2 still have the majority of predictions misplaced in other classes.
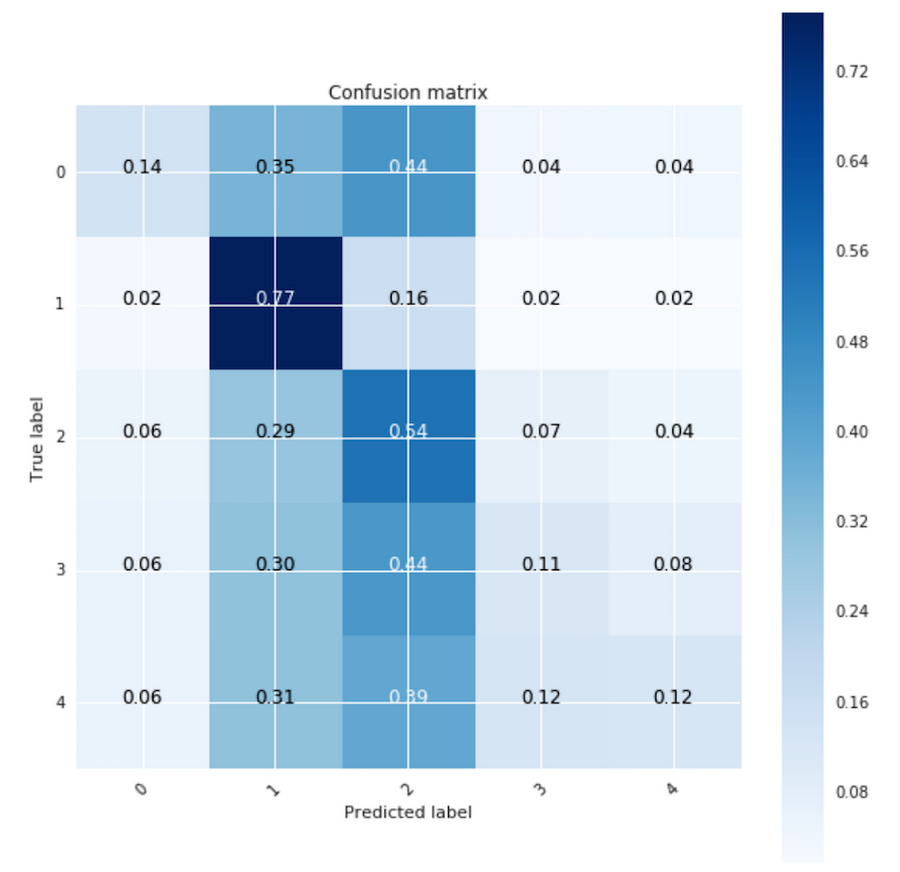
| Model | Top 1 Accuracy | Well-Predicted Classes |
| Inputs= ‘Domain’,’Tags’ Output=’ScoreBin’,’NumCommentersBin’ Using Sample Weights | ScoreBin: 70.1% NumCommentersBin: 71.4% | ScoreBin: 2 (Bins 1,2) |
Let’s try another set of predictors (Subreddit and Submitter):
Using Subreddit and the Submitter as predictors and using sample weights, we get:
| Model | Top 1 Accuracy | Well-Predicted Classes |
| Inputs= Subreddit’, ’RedditSubmitter’ Output=’ScoreBin’,’NumCommentersBin’ Using Sample Weights | ScoreBin: 76% NumCommentersBin: 80.5% | ScoreBin: 4 (Bins 0,1,2,4) |
Our confusion matrix is now better populated along the diagonal line, which is where we want it to be. Four ScoreBin classes are now predicted well: 0, 1, 2, and 4. For bin 3, the largest predicted label bin is 2 (40% of samples), but our model can take partial credit for predicting an adjacent class. Our classification bins represent popularity scores and predicting a range of 10..99 (bin 2) for a true range of 100..999 (bin 3) is more useful than predicting a score of 0 (bin 0).
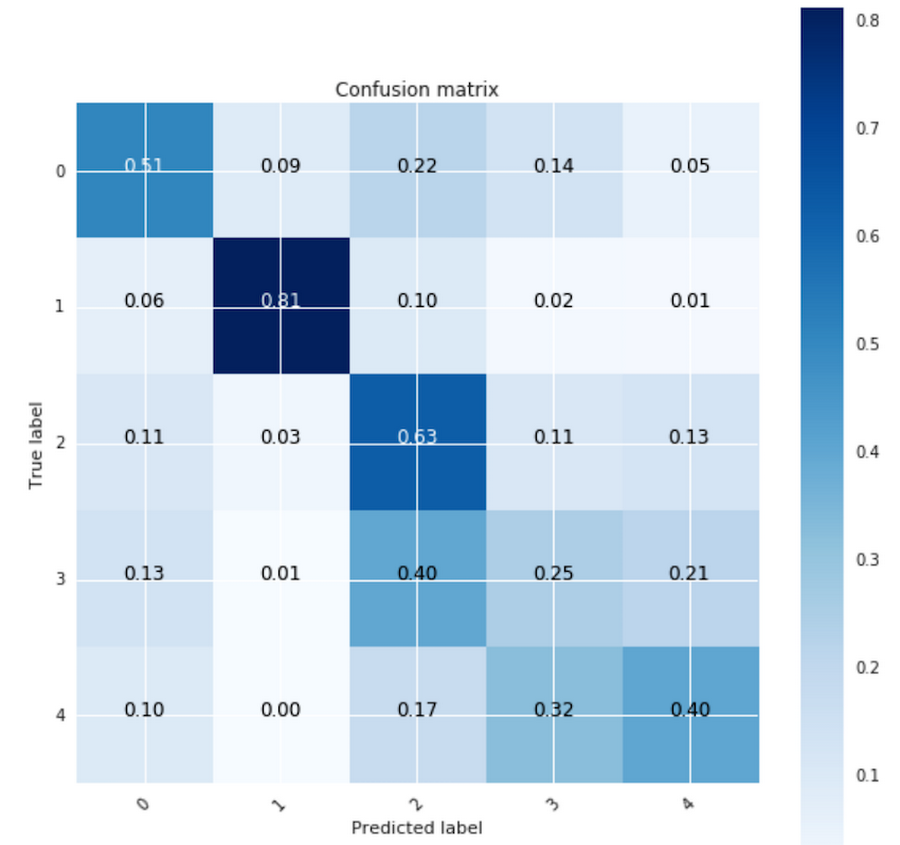
Summary and next steps
For subreddit predictions, the models we developed can be used for a variety of objectives. Our first model classifies a news article according to the interests of the Reddit user community based just on its textual content. Our multi-output model predicts not only the subreddit, but also the submitter. The best subreddit prediction accuracy for articles before they are submitted is provided by our multi-label model. Lastly, our anomaly detection model validates with a 92% top-5 accuracy whether a Reddit post fits previously seen behaviour or is potentially an anomaly.Nick Caldwell, VP of Engineering at Reddit, had the following to say about our models:
The hundreds of thousands of communities on Reddit produce one of the world's largest and most compelling datasets. It's amazing to see how quickly Google's suite of tools can produce models that are both academically insightful and have immediate practical applications for Reddit's 330M users.
| Model Type | Best Fit for Uses |
| Multi-Class, Single-output Example: Sirocco Tags predicting subreddit | Classify an article according to interests of Reddit users based just on its content |
| Multi-Output Domain, GDELT Entities predicting subreddit and Submitter | For cause-effect analysis, predict all results of an action simultaneously |
| Multi-Label Domain and GDELT Entities predicting subreddit | Achieve best accuracy when an output is a set of labels/classes |
| Anomaly Detection Domain, GDELT Entities, and Submitter predicting subreddit | Maintain a high-accuracy model of “typical” or “seen” behaviour, and flag events that have a low prediction score |
For user engagement, it turns out that the best predictors are the subreddit where the post was submitted, and the person who submitted it. While the textual content of articles does influence the selection of the subreddit, it does not seem to impact the popularity or the breadth of the discussion much. Lastly, by using sample weights we were able to improve the classification of labels that were underrepresented in our training set.
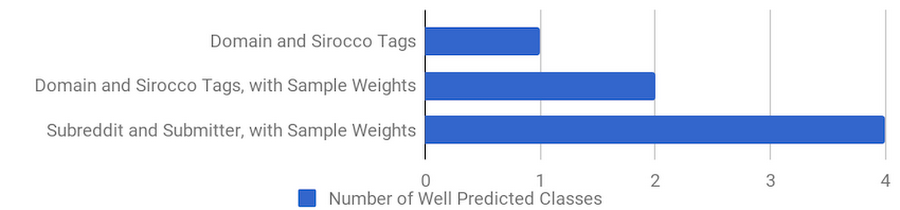
In our next (and final) blog of this series, we will review the feature preprocessing infrastructure based on Cloud Dataflow that we built for this model. Here are a few useful links if you want to learn more:
- Predicting community engagement on Reddit using TensorFlow, GDELT and Cloud Dataflow: Part 1 (previous post in series)
- Predicting community engagement on Reddit using TensorFlow, GDELT and Cloud Dataflow: Part 3 (next post in series)
- IPython notebook for all TensorFlow models mentioned in this blog
- Dataflow Opinion Analysis github repo



