Predicting community engagement on Reddit using TensorFlow, GDELT, and Cloud Dataflow: Part 1
Sergei Sokolenko
Cloud Dataflow Product Manager
What happens when you take a huge cross-section of the world’s news from GDELT, a global news data repository, cross-reference it with data from Reddit, and try to predict what drives community engagement with current events on the world's largest online discussion site? For example, how much does the content of the news article influence the choice of the subreddit community it will be discussed within and its popularity score? How important are the human factors, the individual preferences, or the biases of the Reddit user submitting the news?
Getting answers to these questions on what engages Reddit audiences can be helpful to news publishers or marketing specialists interested in broadening their reach. It can also be used for anomaly detection of behavior that lies outside of “seen” activity and could indicate new emerging trends or bot activity. Without prematurely sharing too much of our final results, it turns out we can predict with 92% accuracy which subreddit a news post will be discussed in by using a TensorFlow model that combines information from GDELT and other public data sources.
In this blog you will learn how to:
- Combine traditional NLP techniques such as entity detection with newer techniques such as word embeddings in a deep learning TensorFlow model
- Maintain your train and test data in BigQuery for reproducibility of your results
Getting to know the data
The data sources used for training our TensorFlow model included:As we went about building the TensorFlow model for this prediction task, we first assembled our training dataset. In the third blog of this blog series, we will explain how we built this input dataset, bringing GDELT and Reddit data together by using Cloud Dataflow and BigQuery. Users of Dataflow and Keras will appreciate the similarity between the two frameworks, as both of them make it very easy to develop layered data transformation graphs.
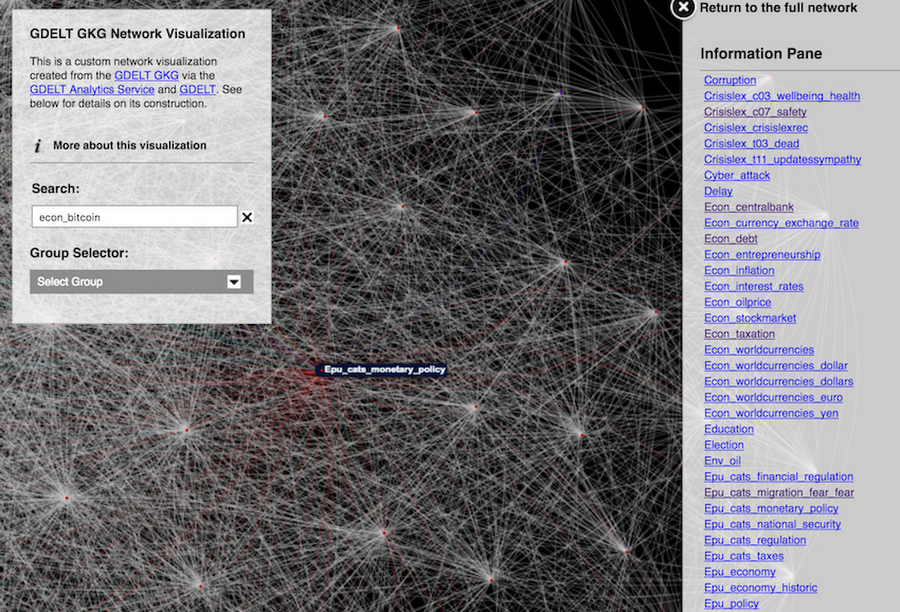
GDELT analysis service showing connections between news themes related to Bitcoin
Let’s start by posing a hypothesis about user behavior on Reddit. Our hunch is that the content of the article and where it was published plays a role in piquing the interest of a Reddit user and her subsequent selection of the subreddit where she will post it for discussion. To evaluate this theory, we will develop a model that makes the following prediction: “Based on WHERE the article was published, and WHAT it was ABOUT, WHO will share it on WHICH subreddit”. If the accuracy of the model is high, we will consider our hunch proved true. This is, by the way, a methodical approach for developing ML models grounded in some basic knowledge of the data and intuition about the human behavior involved.
| Predictor | Predictor | Outcome | Outcome |
| WHERE PUBLISHED | WHAT ABOUT | WHO POSTED | WHICH COMMUNITY |
| Domain | Tags, GDELT Entities | Submitter | subreddit |
For this model, we will use text topics supplied by GDELT and the open source library Sirocco, as well as domains extracted from the Article URL (e.g. foxnews.com or washingtonpost.com).
In recent months, techniques such as Word Embeddings, Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) have become popular for text processing. These techniques have been successfully applied to predict various attributes of text, including its sentiment, its topic, etc.
There are two basic approaches with word embeddings:
In the first one, words are encoded as multi-dimensional vectors and then a bag-of-words technique is applied to create an aggregate vector that represents all words of the text. With this approach, the order of words is not preserved. Below is a 2-dimensional projection of 200-dimension encodings created with Word2Vec for words related to politics, with “violence” on one extreme of this spectrum, and “discussion” and “relations” on the other.
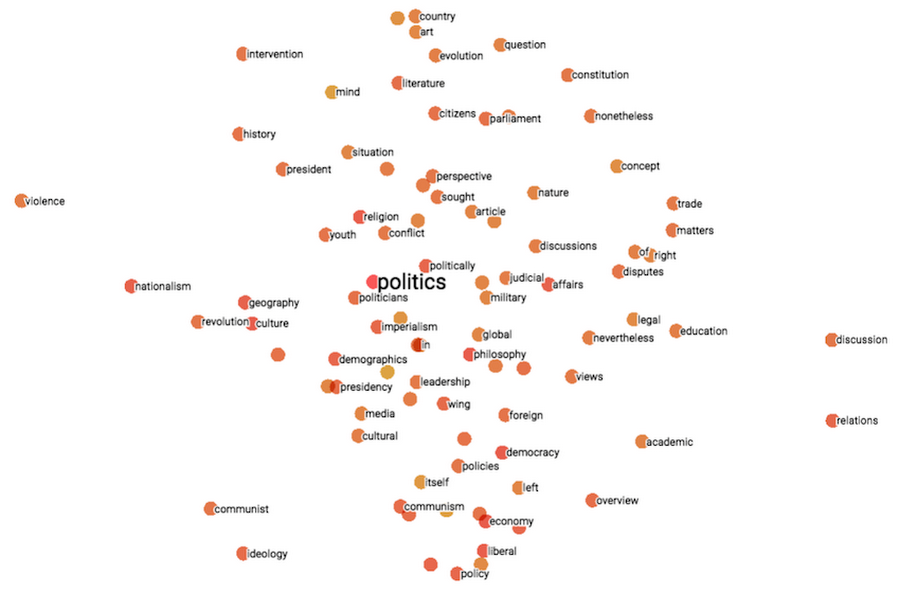
Word2Vec embeddings available here
In the second, sequence-based approach, words are first encoded as vectors just like in the first approach, but their order is preserved and sentences are represented as sequences of word vectors. Then, CNN and RNN layers are added on top of these sequences in order to uncover the meaning of words when they appear in context of other words.
The word embedding-based approach differs from the natural language processing techniques that were developed in early 2000s. In those prior techniques, text went through stages such as part-of-speech tagging, chunking, and parsing of input text. The result was a dependency or a constituency tree linking the words in the sentence.
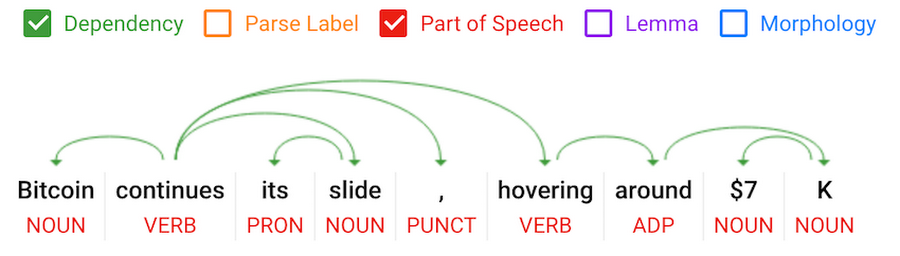
A sentence dependency tree parsed by Google Cloud Natural Language API using traditional NLP techniques, available at cloud.google.com
In our research we decided to combine the two approaches and use NLP techniques as a preprocessing step to create sets and sequences of higher-level concepts. Once we encoded text into human-defined taxonomy of concepts, we could then apply the embedding techniques and layer densely-connected layers for unordered bags-of-concepts or convolutional or recurrent layers for sequences of concepts.
Although novel, this approach is analogous to layering techniques, where multiple RNN or CNN layers are placed on top of each other, and where the higher-level layers are learning more sophisticated concepts than just words. In our approach, we cut short the initial learning, and opt to supervise the first level of learning ourselves.
You can extend this approach beyond encoding text. For example, if you have user-created tags associated with images, you could add an embedding of these tags to the image data to provide additional input into your predictions. This technique works well when you have sets of concepts of varying size that you want to vectorize in order to use them as input features.
Let’s see how this works for our model. If you remember, we have two data sources for textual concepts. The first one is GDELT, and the second one is Sirocco. The GDELT global knowledge graph table gdelt-bq.gdeltv2.gkg has fields such as V2Themes, AllNames, and V2Locations, containing themes, names, and locations mentioned in news articles. Using the article URL, we can match these data points with the Reddit BigQuery dataset. Run this query against the GDELT gkg table:
It returns the following themes, names, and locations for one of the posts from the GCP Big Data blog (here shown in JSON format):
All three fields contain an offset at which a particular theme, name, or location was found in text (e.g. in this theme mention, “WB_470_EDUCATION,383”, 383 is the offset). We will use this offset to order the themes and names into sequences.
We wanted reproducibility of our model training, so we retrieved our data directly from BigQuery without using intermediate data files. This step also allowed us to more quickly iterate on our model because new data was just one query execution away. We joined 3 months worth of GDELT articles and Reddit posts (June through August 2017) for this analysis and excluded all posts in subreddits populated by auto posting bots (e.g. TheNewsFeed and all subreddits ending in 'auto’) because the publication domain was the sole driver for such posts, making the article content irrelevant.
We also did a little feature engineering right in our SQL query, and BigQuery was able to handle the additional complexity with speed and flexibility. One such enhancement was to initially encode GDELT themes before bringing them over into our Jupyter notebook. We did this because GDELT uses a multitude of taxonomies for themes, and each article is customarily tagged with hundreds of them, in addition to a large number of organizations, person names, and locations mentioned in the article. Our SQL query filters out names and locations that were mentioned infrequently and taxonomies that duplicate other taxonomies. (You can read up more on this on this Medium post.) Instead of textual tags (e.g. WB_470_EDUCATION), we represented each GDELT article as a set of numbers where each number stands for a theme, name, or location.
An alternative text preprocessing source is Sirocco, available in open source and used by the Dataflow Opinion Analysis project. Sirocco uses traditional NLP techniques such as part-of-speech tagging, parsing, and constituency trees. The same article is summarized by it into 7 tags.
Since the number of Sirocco summarization tags is typically less than 10, we do not encode them on the BigQuery side, and instead encode them using a Keras Tokenizer.
The create_bow_input function in our notebook (find it here) creates sequences of numbers representing the concepts we are trying to encode. And the next function create_bow_embedded_layer creates a series of Input, Embedding, and Flatten layers in Keras that implement a Bag-of-Concepts representation for any input feature and can then be merged with other inputs and connected with the upstream Dense, Recurrent, or Convolutional layers.
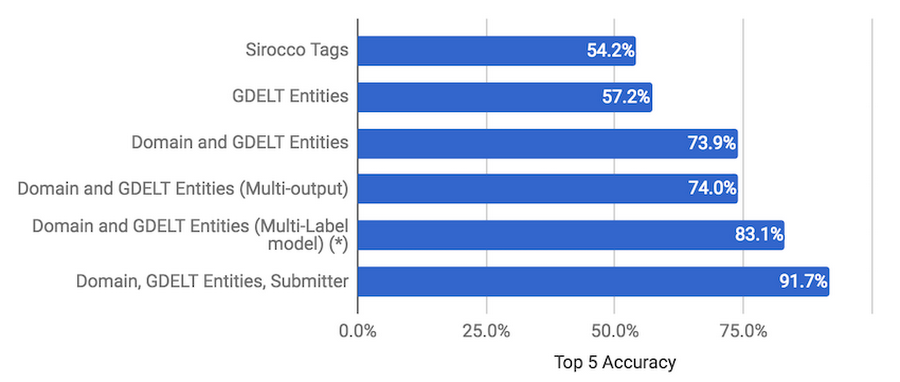
For our analysis, we compared Sirocco Tags and GDELT Entities encoded as Bag-of-Concepts. When we evaluated the suitability of GDELT entities for sequence analysis using CNN and RNN, the resulting accuracy of the model was not high because of the noisiness of the input. While the GDELT concepts (themes, names, locations) could be ordered into sequences by the occurrence offset, we just had too many taxonomies (original GDELT, Worldbank, UNDP, CrisisLex, etc.) integrated into one feature. In the future, we intend to build a better concept sequence representation of news articles by selecting just one of the taxonomies, and adding the emotion analysis concepts supplied by Sirocco.
In the second part of this series, we show how our model evolved from just having the news post content as a predictor, to combining post content with publication domain, to using a multi-output model. The model with the best accuracy of predictions (83.1% Top 5 accuracy) was one that used the Domain and GDELT Entities predictors and produced a multi-label subreddit output.
| Predictor | Predictor | Outcome | Outcome |
| Domain | GDELTEntities | Submitter | subreddit |
Regardless of how we tuned our model, however, we couldn’t improve its accuracy with the given set of predictors (GDELT Entities and Domain) beyond 80% range. That is, until we tried something new and made the submitter a prediction input instead of an output. The human factor must have some weight in the choice of the Reddit community, one would think.
The results of our new model are impressive. Compared to our next-best model we gained 8.6% in Top 5 Accuracy to reach 91.7%. The discretion of the submitter in her choice of subreddit indeed mattered.
We are calling this model an anomaly detection model for subreddits. Compared to models that used just the Domain and GDELT Entities as predictors, it can’t be used to make predictions of subreddits before the post is submitted to Reddit. But it can be used to verify submissions after the fact, whether they fit an established posting pattern, or whether it is an anomaly that is worth investigating. Here is the Keras plot of our anomaly detection model for subreddits.
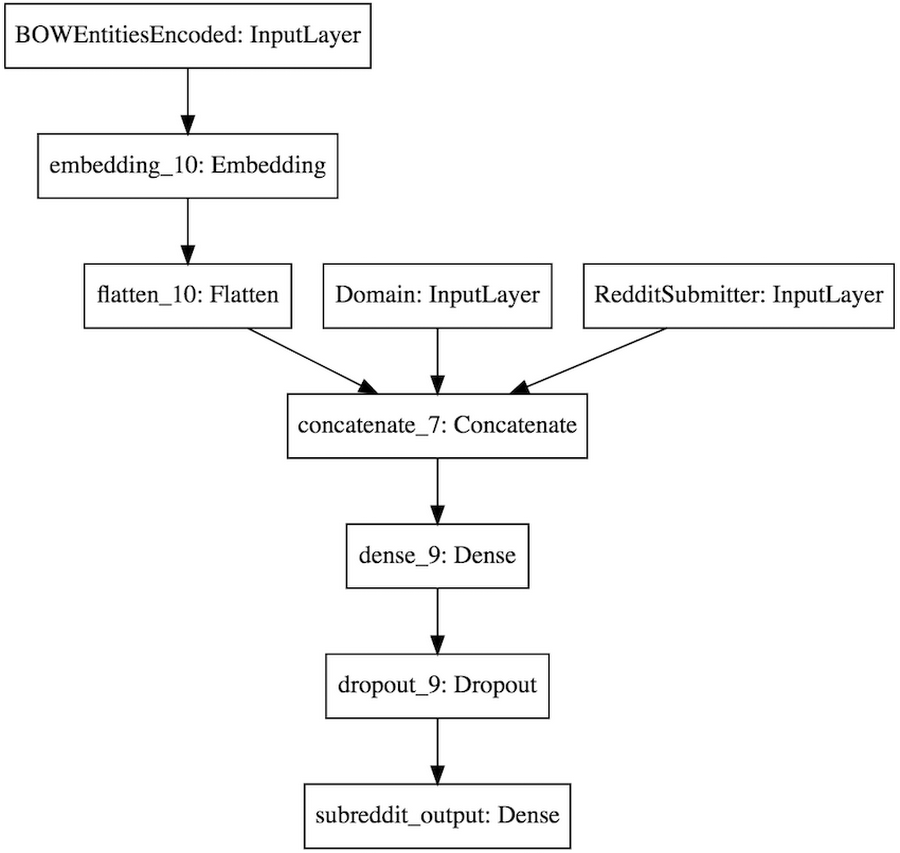
Now that we are able to make good subreddit predictions, what about predicting a post’s popularity score and the level of engagement by the Reddit user community? Similarly to our approach for subreddits, we shortlisted a few possible predictors: the publication domain and the content of the article may gather a very specific readership for the post, while the submitter of the post may attract her followers due to her social reputation, and the subreddit could influence user engagement because of the regular (and continuous) audience it attracts.
Part 2 of this series goes into detail of tuning our model, but the surprising learning from this exercise was that the best predictor was the combination of the subreddit and the submitter. While the textual content of articles does influence the selection of the subreddit, it does not seem to impact the popularity or the breadth of the discussion much. The prediction accuracy of the popularity score and number of commenters was in the 80% range.
Summary and next steps
Our most accurate model for classifying a news article according to interests of the Reddit user community based just on its content was a multi-label model that used publishing domains and GDELT entities as predictors. We also developed an anomaly detection model (with a 92% top 5 accuracy) that can be used for validating whether a posting to a subreddit fits already seen behaviour or constitutes a new trend or potentially an anomaly. We were also surprised to learn that once an article is posted to Reddit, its popularity and community engagement will depend on who posted the article to Reddit, and which subreddit it landed at, but not its content.More generally, we saw that traditional NLP techniques such as entity extraction can be combined with Deep Learning techniques such as embeddings for high accuracy predictions. And we learned two techniques for representing multi-value inputs and outputs in Tensorflow models (Bag-of-Concepts for inputs, and Multi-Label classification for outputs).
As GDELT founder Kalev Leetaru put it, "These results really showcase the immense potential of open datasets like GDELT and Reddit that provide the foundations for others to build upon to explore critically important and fascinating questions." He continued, "In a world in which we are struggling to understand how our news ecosystem is consumed and shared, the ability of a single researcher to rapidly assemble algorithms with these accuracy levels for anomaly detection and virality prediction stands as a testament to the power of open data in the cloud and the incredible power that tools like BigQuery, TensorFlow and Cloud Dataflow bring in making sense of the chaos of the real world."



