Parsing our #olympics fever with the Cloud Natural Language API and BigQuery
Sara Robinson
Developer Advocate, Google Cloud Platform
The Olympics always generate lots of strong emotions, and this year’s Rio games were no exception. But how can you quantify that? For example, what were the most common adjectives used to describe the Olympics on Twitter during the closing ceremonies? I decided to use the Twitter Streaming API, the Cloud Natural Language API and BigQuery to find out. Here are the results, visualized with Data Studio:
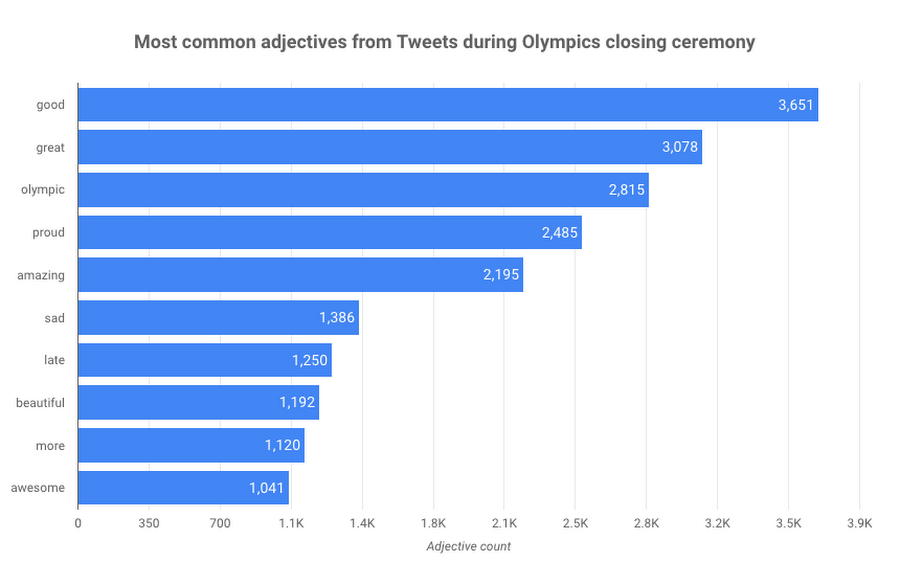
How did I get from raw tweets to counting the most common adjectives? For 6 hours before and after the closing ceremonies, I streamed all tweets with the hashtags #Rio2016, #RioOlympics2016 or #olympics, excluding tweets starting with “RT.” I used the Cloud Natural Language API’s annotateText method to analyze the text of the tweets, and stored each tweet as a row in BigQuery. After 6 hours I collected over 77,000 tweets.
Syntactic analysis with the Cloud Natural Language API
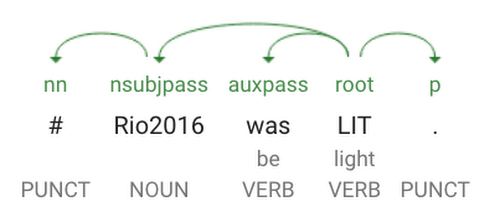
The Natural Language API lets you analyze the structure and meaning of text. It has three methods: entity, sentiment and syntax analysis. This post will focus on the syntax analysis method (called annotateText), but you can check out this post for an intro to the other two. When you send text to the annotateText endpoint, the API returns data on each token in the sentence, where a token is a word or punctuation. Let’s see an example looking at the text from this tweet:#Rio2016 was LIT, so we put together a list of the 16 best moments from the last 17 days. https://t.co/pjWu38lbcj pic.twitter.com/QMjB2lYIVb
- NBC Olympics (@NBCOlympics) August 22, 2016
Sending the above text to the Natural Language API, we get an object for each token in the sentence. The full JSON response is pretty long, but here’s a sample of the first four tokens:
This provides data on the part of speech of each word, along with how all the words in the sentence relate to each other. Looking at the "Rio2016" token above, the tag tells us that it's a noun. Its label is NSUBJPASS, which means it’s the passive nominal subject in this sentence. Every sentence has one ROOT verb, in this case it’s “LIT”. lemma is the canonical form of the word, as the lemma for “LIT” is “light.” The lemma value in useful for grouping variations of the same word together, which is what I used to count adjectives in the first example. We can use all of this data to visualize how the sentence is structured with a dependency parse tree:
Diving into token data with BigQuery
Since I wasn’t sure exactly what type of linguistic analysis I wanted to perform until after streaming all the tweets, I decided to insert the JSON token data for each tweet into BigQuery and analyze the data after collecting it. Over the course of 6 hours, I streamed 77,838 tweets into a BigQuery table with the following schema:
Each row is a single tweet. user_followers_count is a proxy for tweet quality and popularity, since tweets from the Streaming API are “fresh” and have 0 retweets or favorites. The most important field here is tokens, which is the full JSON response from the Natural Language API. Luckily BigQuery supports user-defined functions (UDFs), so I can write a JavaScript function to parse the tokens' JSON for each tweet. To generate the adjective bar graph above, I wrote the following query with an inline UDF:
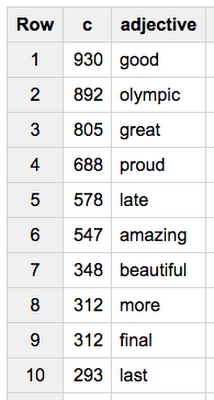
In the first line of my UDF, I pass the schema for my output column. In this case, I’ll have one column with each adjective and a count of mentions for each. Then I loop through each token and add it to my output table if it’s an adjective. Here’s the first 10 rows from the resulting table:

Interestingly, this list changes slightly if I look only at tweets from users with more than 1000 followers:
Comparing adjectives for different athletes
What if I want to look at all the adjectives used to describe a particular athlete? I could get all adjectives from tweets containing the name of the athlete I’m looking for, but I really only want sentences where the athlete is the subject of the sentence.To accomplish this I can use the label value returned by the NL API, by checking to see if the nominal subject (NSUBJ) of each sentence matches the athlete we’re looking for. If it does, we can find all the adjectives in that sentence using the same approach we used above. Here’s what our modified UDF looks like (in this example, we’re looking at all the tweets with Simone Biles as the subject):
Let’s compare the results from this query to the adjectives used in tweets about Usain Bolt. Here are visualizations for both Bolt and Biles, created with Tableau:
While there are some overlapping words (“amazing,” “olympic,” “great”), many of the adjectives used to describe Bolt focus on his performance (“fast,” “last,” “different”), while many of Biles’ adjectives are related to her appearance (“cute,” “american,” “nervous,” “excited”).
Analyzing emojis
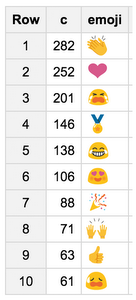
Many tweets contain emojis, and it would be cool to find out which emojis were most common on Twitter during the closing ceremonies, because who doesn’t love emojis? The Natural Language API parses each emoji as its own token, even if it’s part of a word. We can use a user-defined function to extract all emojis from our JSON.Emojis fall under the “X” part of speech tag, which categorizes foreign words, typos and abbreviations. First, using the same approach as above, we’ll get all tokens with “X” as the value for tag. From here, we need to filter out only the emojis and count them. To do this, we’ll use a regular expression to see if each token’s content matches any of the Unicode emoji values. Here’s the result:
This is better analyzed with a visualization. Below is a tag cloud I created with JavaScript:




