New codelab: running OpenCV on Google Cloud Dataproc using Apache Spark
Ashwin Raghavachari
Software Engineer Intern
Jim McBeath
Software Engineer
Cloud Dataproc makes it easy to use external libraries, such as OpenCV, for computation and data processing on extremely large datasets.
Google Cloud Dataproc is a fast, easy-to-use and cost-effective managed Apache Spark and Apache Hadoop service. With Cloud Dataproc, you can easily process large datasets. However, to run an application that uses libraries not already installed on a Cloud Dataproc cluster, you must install the relevant libraries manually. To save time and energy, the installation can be automated by using an initialization action, or the installation can be avoided altogether by deploying a fat JAR containing the project files and all the project dependencies.
In this post, we’ll introduce a new codelab that explains how to build and submit a fat JAR to the Cloud Dataproc cluster using OpenCV as the case example.
About OpenCV
OpenCV is an open source computer vision and machine-learning library that provides a common infrastructure for computer vision applications. OpenCV contains more than 2,500 optimized algorithms, and is used by a community of nearly 50,000 people, with a total estimated number of downloads exceeding 7 million.OpenCV jobs are generally very compute intensive, so running an OpenCV application on a large dataset requires a scalable approach. As we’ll explain in the next section, running OpenCV with Spark on Cloud Dataproc enables much faster processing for a large dataset as compared to a single machine, and provides a much more scalable and efficient computer vision-processing platform.
A classic example of an OpenCV job is detecting faces in images. Other common applications for OpenCV are feature detection, object and gesture recognition, motion tracking, 3D modeling and augmented reality.
Results on Cloud Dataproc
In our own testing, we implemented an OpenCV application that detects and outlines specific features, such as faces, on a set of images. This application was developed on a single workstation. This local setup allowed faster and easier debugging when coupled with a small test dataset. After the application was working correctly on the test dataset, we moved onto running the application on a Cloud Dataproc cluster for use on our large dataset.Running this application for 1,000 images (average file size: 223KB) on a single workstation with 12 cores took approximately 208 seconds, including setup and cleanup time. However, on a Cloud Dataproc cluster with five worker nodes, each with 16 cores, processing 1,000 images only took approximately 62 seconds, including setup and cleanup time. (Note: These results are representative of running on a large cluster versus one machine; your own results may vary depending on cluster size, image complexity and the size of data processed involved.)
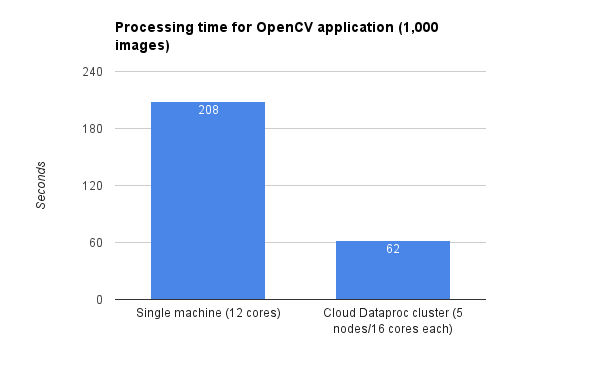
These results demonstrate that when running complex OpenCV applications on large datasets, it makes sense to develop and test the program on a local machine, then move to Cloud Dataproc for larger, more rigorous datasets.
Next steps
You can explore the codelab that guides you through this same process here. To learn more about Cloud Dataproc:- Learn how to get started
- Review all the Quickstarts
- Sign up for a free trial



