Lessons learned from a year of using live migration in production on Google Cloud
Scott Van Woudenberg
Product Manager, Google Compute Engine
It's been a little over a year (and millions of migrations) since the last time we talked about our live migration technology and how we use it to keep your virtual machines humming along while we patch, repair and update the software and hardware infrastructure that powers Google Compute Engine. It’s also an important differentiator for our platform compared to other cloud providers.
Our customer base has grown exponentially in the past year, and brought with it a lot of new and interesting workloads to test the mettle of our live migration technology. The vast majority of customers and workloads have been able to go about their business without noticing our maintenance events, with a few exceptions.
Down and to the right
A picture is worth 1,000 words and the following graph shows the improvements we've made to live migration blackout times (the amount of time your VM is paused) over the last year (note the log scale):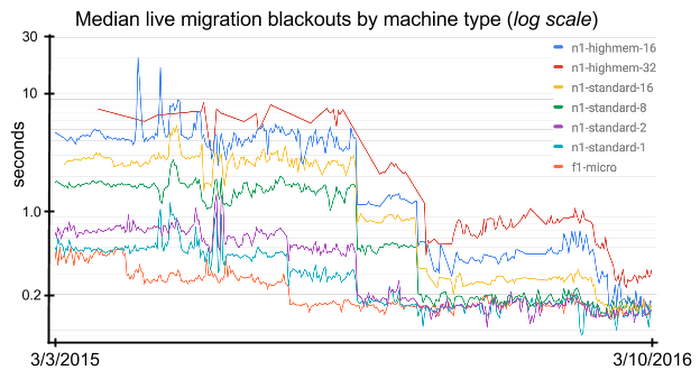
We've done millions of live migrations in the last year and as you can see from the graph, we've made significant improvements to median blackout duration and variance. The 99th percentile blackout graph is too noisy to display nicely, but we've improved that by a factor of six in the last year as well.
Lessons learned
The graph also shows that we didn't always get it right, and we've learned a lot from working closely with the handful of customers whose applications just don't play well with live migration.The most important thing we learned is that the current 60 second pre-migration signal is overkill for the vast majority of customers. At the same time, the 60 second signal is too short for the handful of customers that needed to perform some sort of automated drain or failover action.
We also learned that the older in-place upgrade maintenance mechanism (not captured in the above graph) we use to update our hypervisor is problematic for customers whose applications are sensitive to live migration blackouts.
Finally, we learned that surfacing VM migrations as system events in our ZoneOperations list led to a lot of confusion for little incremental value, since the events were also logged, in greater detail, in Compute Engine’s Cloud Logs. In many cases, customers noticed an issue with their service, saw the migration system event in the ZoneOperations list, and spent a long time investigating that as the cause, only to find that it was a red herring.
What's next?
Aside from continuing to measure and improve the impact of our maintenance events, the first thing we're going to do is drop the 60 second notice for VMs that don't care about it. If a VM is actively monitoring the metadata maintenance event URI, we'll continue to give 60 seconds notice before the migration. If a VM is not monitoring the URI, however, we'll start the migration immediately. This will not change the behavior of VMs that are configured to terminate instead of migrate. We expect to roll this out by mid-May.In the coming quarters we’ll also begin providing a longer, more usable advance notice for VMs that are configured to terminate instead of migrate. This advance notice signal will be available via the metadata server as well as via the Compute Engine API on the Instance resource.
We'll also add a new API method to the Instance resource to allow customers to trigger maintenance events on a VM. This will give customers a means to determine if a VM is impacted by maintenance events and if so, to validate that its drain/failover automation works correctly.
The second major change we'll make is to use live migration for all instance virtualization software stack updates, replacing in-place upgrades. This will make these maintenance events visible, actionable and less disruptive while allowing us to focus our improvements on one maintenance mechanism rather than two. Finally, we'll remove VM migration events from our Operations collections and expand on the details of the events we log in Cloud Logs.
We strongly believe that fast, frequent, reliable, and above all, transparent infrastructure maintenance is essential to keeping our systems secure and to delivering the new features and services that customers want. We're pleased with the results we've seen so far, and we're excited to continue making it better. Follow us on G+ and/or Twitter to stay informed as we start rolling out these improvements. If you have any questions or concerns, please reach out —
we'd love to hear from you.



