Learn to run Apache Spark natively on Google Kubernetes Engine with this tutorial
Anirudh Ramanathan
Software Engineer
Palak Bhatia
Product Manager
Apache Spark, the open-source cluster computing framework, is a popular choice for large-scale data processing and machine learning, particularly in industries like finance, media, healthcare and retail. Over the past year, Google Cloud has led efforts to natively integrate Apache Spark and Kubernetes. Starting as a small open-source initiative in December 2016, the project has grown and fostered an active community that maintains and supports this integration.
As of version 2.3, Apache Spark includes native Kubernetes support, allowing you to make direct use of multi-tenancy and sharing through Kubernetes Namespaces and Quotas, as well as administrative features such as Pluggable Authorization and Logging for your Spark workloads. This also opens up a range of hybrid cloud possibilities: you can now easily port and run your on-premises Spark jobs on Kubernetes to Kubernetes Engine. In addition, we recently released Hadoop/Spark GCP connectors for Apache Spark 2.3, allowing you to run Spark natively on Kubernetes Engine while leveraging Google data products such as Cloud Storage and BigQuery.
To help you get started, we put together a tutorial to learn how to run Spark on Kubernetes Engine. Here, Spark runs as a custom controller that creates Kubernetes resources in response to requests made by the Spark scheduler. This allows fine-grained management of Spark applications, improved elasticity and seamless integration with logging and monitoring tutorials on Kubernetes Engine.
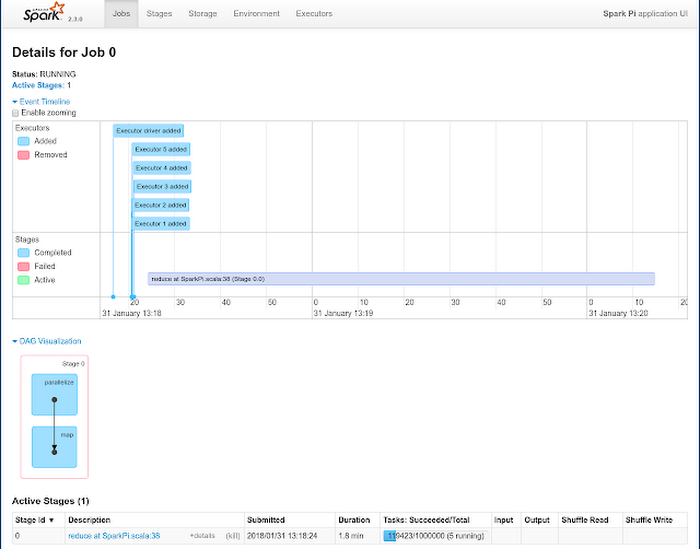
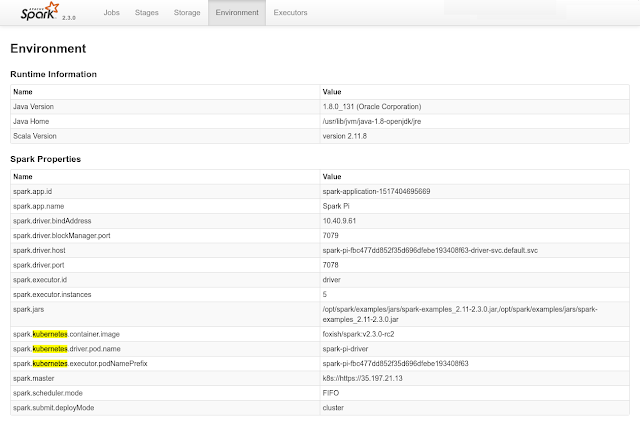
This tutorial brings together some of the best data storage and processing services of Google. In addition to Cloud Storage and BigQuery, it shows you how to use Google Cloud Pub/Sub with Spark for streaming workloads. The tutorial details the Spark setup, including credentials and IAM to connect to Google’s services and provides runnable code to perform data transformations and aggregations on a public dataset derived from Github. This is a good approach to take if you're looking to write your own Spark applications and use Cloud Storage and BigQuery as data sources and sinks. For instance, you can store logs on Cloud Storage, and then use Spark on Kubernetes Engine to pre-process data, and use BigQuery to perform data analytics.
Designed for flexibility, use this tutorial as a jumping-off point, and customize Apache Spark for your use-case. Alternately, if you want a fully managed and supported Apache Spark service, we offer Cloud Dataproc running on GCP.
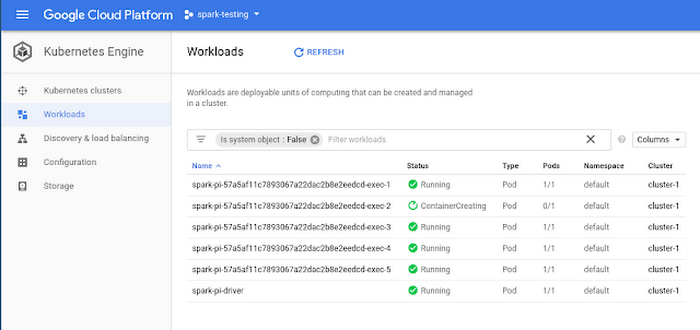
We have lots of other plans for Apache Spark and Kubernetes: For one, we’re building support for interactive Spark on Kubernetes Engine. In addition, we’re also working on Spark Dynamic Resource Allocation for future releases of Apache Spark that you’ll be able to use in conjunction with Kubernetes Engine cluster autoscaling, helping you achieve greater efficiencies and elasticity for bursty periodic batch jobs in multi-workload Kubernetes Engine clusters. Until then, be sure to try out the new Spark tutorial on your Kubernetes Engine clusters!



