Introducing Cloud Dataflow Shuffle: For up to 5x performance improvement in data analytic pipelines
Tudor Marian
Software Engineer
Marián Dvorský
Software Engineer, Google Cloud Platform
Learn how the new service-based Shuffle feature brings significant performance improvements to your Cloud Dataflow pipelines.
Google Cloud Platform (GCP) has a track record of continually bringing innovations in data processing, such as streaming and Apache Beam-based SDKs, to Cloud Dataflow customers. Today, we're introducing a new feature (currently in beta) that significantly improves the performance and scalability of data shuffling operations: the service-based Cloud Dataflow Shuffle.
Cloud Dataflow is GCP’s fully-managed data processing service for streaming and batch data analytics pipelines. Shuffle is the ubiquitous Cloud Dataflow operation that enables transforms such as GroupByKey, CoGroupByKey and Combine by partitioning and sorting the data by key in a scalable, efficient and fault-tolerant manner. Currently, Cloud Dataflow’s shuffle implementation runs entirely on worker VMs and consumes worker CPU, memory and Persistent Disk storage. The new implementation, however, moves the shuffle operation out of the worker VMs and into the Cloud Dataflow service backend. This change leads to faster execution time of batch pipelines for most job types; furthermore, users can expect a reduction in consumed CPU, memory and Persistent Disk storage resources on worker VMs.
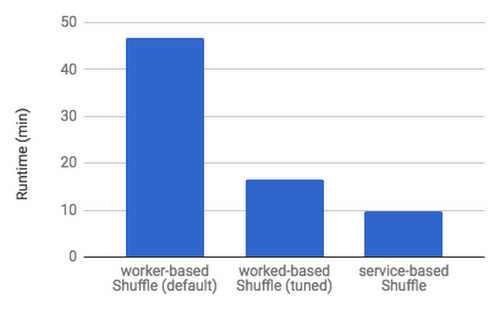
Below is an example of a Dataflow pipeline joining 1TB of data using the default configuration (worker-based shuffle on n1-standard-1 machine type using Persistent Disk storage), tuned configuration (worker-based shuffle on a larger n1-standard-4 machine type and using SSD storage) and the new Cloud Dataflow Shuffle. This new shuffle approach doesn’t require the user to specify any tuning parameters, and is almost 5x faster than the default configuration and 40% faster than the tuned version of the worker-based shuffle.
While we don’t expect every join or group-by job to improve their performance by a multiple of 5, we’ve seen significant speed improvements for a large number of users. Here’s what some customers say about Cloud Dataflow Shuffle:
Using Cloud Dataflow Shuffle is really simple: All we had to do was make a few flag changes. After switching to Cloud Dataflow Shuffle, our 20TB machine learning pipeline saw a 3x performance improvement in shuffle operations.
Jim Deng, VP Engineering, Moloco Ads
Using Cloud Dataflow Shuffle required no changes to our pipelines, our jobs ran twice as fast, and with more consistent runtimes, allowing us to better plan our workflows.
Elango Cheran, Software Engineer, Nest Labs
Next steps
The new service-based Cloud Dataflow Shuffle beta is currently available in the us-central1 (Iowa) region, and initially for batch pipelines created via the Cloud Dataflow SDK for Java version 1.9.x only. (Support for Cloud Dataflow SDK for Java version 2.0.0 and Cloud Dataflow SDK for Python, as well as availability in other regions, is forthcoming.) It will eventually replace the worker-based Shuffle implementation once it reaches General Availability. To activate the feature in your batch pipelines you would use the following parameter:To launch a Cloud Dataflow Shuffle-enabled job in the us-central1 (Iowa) region, omit the --zone parameter; Cloud Dataflow will auto-select the best zone in which to run the job. (Note: although there's a charge of $0.0216 per GB-hour associated with the use of Cloud Dataflow Shuffle, due to performance improvements, we expect the total cost of most Cloud Dataflow pipelines using it to be less than or equal to those utilizing the current worker-based Shuffle implementation.)



