Improving the efficiency of your helpdesk with serverless machine learning
Matthieu Mayran
Cloud Solutions Architect, Google Cloud
Great customer service builds trust, inspires brand loyalty, and earns repeat business. So it’s no surprise that, according to Deloitte, close to 90 percent of organizations name improving the quality of their customer service as a strategic focus. But achieving — and maintaining — a high standard for customer service not always easy. Customer service helpdesks know this all too well. They often deal with an ongoing flow of tickets that sometimes have little information or context, which can slow down agents and impact service quality.
What if you could use historical data to predict key KPI or fields of a support ticket to handle it in the most efficient way? Some support ticket data — such as resolution time, priority, tags, or sentiment — is only known once a ticket is being handled or once closed. Knowing that information in advance can give the agent the opportunity to involve subject experts faster, add more resources, or treat it with more attention or empathy, as required.
But building something on top of an existing helpdesk tool, and setting up servers, monitoring, and developer operations (DevOps) might seem like a daunting set of tasks. Thankfully, with today's technology, it’s possible to build such a flow without much technical overhead.
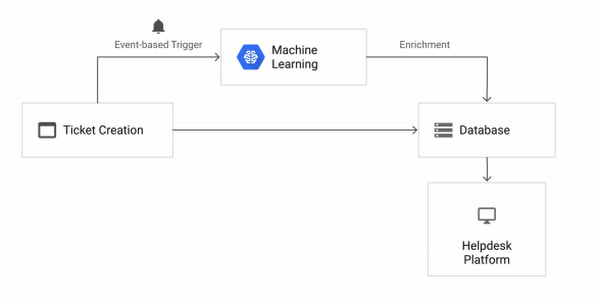
In a two-part solution and tutorial linked in the Next Steps section of this post, you’ll learn how to leverage a few Google Cloud Platform technologies to build a serverless data augmentation platform on top of an existing CRM product using:
- Firebase as a real time, fully managed database.
- Cloud Natural Language as a pre-trained and pre-built model that can do sentiment analysis and find word salience in new text.
- Cloud Datalab to build custom TensorFlow models for training and prediction.
- Cloud Machine Learning Engine to train, deploy and run predictive models with minimum management overhead.
- Cloud Functions to build serverless code that brings all the products together with minimum required DevOps: A ticket submission triggers machine learning models to augment the ticket with auto-populated fields. Cloud Functions then saves the enhanced ticket into a 3rd party tool through its API.
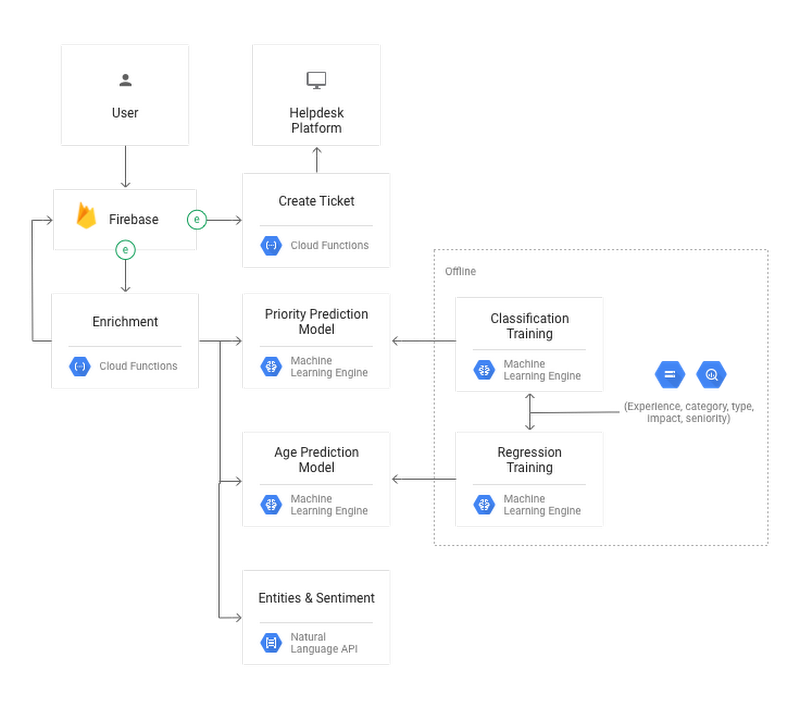
As you can see in the diagram, there are two main machine learning parts:
- Cloud Natural Language is one of Google Cloud's pre-trained AI models, which are ready-to-use and accelerate development cycles. Predictions generated from Cloud Natural Language, such as sentiment and entity detection, can be used to build more complex machine learning models that are capable of finding deeper insights or answers to outliers or unusual problems.
- Cloud ML Engine, while requiring more technical expertise, offers more flexibility by letting you train custom models and deploy them for prediction with minimum DevOps overhead. It also handles key machine learning optimizations such as fine-tuning hyperparameters.
- Inputs: Identify which types of inputs you’ll use, and make sure they’re consistent over time. For example:
| Task | Inputs example | Watchpoint examples |
| Image classification (unstructured data) | Pixels’ grayscale vectors | If you built and train a model to classify 30x30 gray images, do not provide 150x100 color images. |
| Ticket classification (structured data) | CSV columns: seniority, experience, type | Use the same columns when doing prediction. Do not add job title, for example. |
- Processing: Perform feature engineering to turn your inputs into relevant features, then tingest and represent those features to map the data to a model. See Tensorflow feature columns for more details. Within Datalab, it can sometimes be done in a declarative way such as:
- Model: Choose a machine learning task to perform (ex: classification, regression) and choose relevant models to try out.
| Task | Example of possible models |
| Image classification (unstructured data) | Convolutional neural network model using the Estimator API. |
| Ticket classification (structured data) | Canned Estimator such as LinearClassifier or DNNClassifier. |
- Training: In some cases you might want to use a pre-trained model. In others, it might be better train one yourself.
| Task | Training strategy |
| Sentiment analysis (unstructured data) | Use Natural Language API, which is trained on a bigger corpus than what’s available to many companies. |
| Text Classification (unstructured data) | Leverage pre-existing word embedding dictionaries, then train your model to predict your custom labels. |
| Ticket classification. (structured data) | Define the columns that you want to use for training, then train your model to predict your custom labels. |
- Prediction: Decide whether the model will get deployed for online or offline prediction. This might affect the way a client interacts with the model. For example, an online prediction done on a website would require a RESTful endpoint. This makes the prediction available to various programming languages. On the other hand, an offline prediction might only need to call the model through a command line. Those are important considerations to make.
- ML Workbench provides extra magic cells that do not require TensorFlow programming knowledge, and facilitates model training and deployment directly from Cloud Datalab.
- Google Cloud Platform products run tasks at scale, such as feature engineering, by leveraging the cloud.
- Cloud Datalab is a great central place to call those services, but still interact with the returned data.
The workflow explained in the solution — which you can build via the tutorial — follows these steps:
- A user creates a ticket through an HTML page.
- The ticket is saved in the Firebase provided real-time database.
- Cloud Functions is triggered to call the Natural Language API and custom-built Cloud ML Engine models.
- This augments the ticket in Firebase by filling in empty fields.
- Cloud Functions calls the Salesforce API to create the new improved ticket into Salesforce (note that you can do the same with Jira or any other support tool that offers a RESTful API).
Next steps
- Read the two-part solution to learn more about the architecture of a serverless machine learning model — and understand the steps required to build one.
- Run the companion tutorial to build an enrichment platform for a helpdesk, which includes:
- A Firebase-derived real-time frontend.
- A machine-learning based enrichment platform.
- A connection to an existing Salesforce.com Case instance.
- Customize your text classification, starting with word embedding techniques such as word2vec.



