How Waze tames production chaos using Spinnaker managed pipeline templates and infrastructure as code
Tom Feiner
System Operation Engineer, Waze
At an abstract level, a deployment pipeline is an automated manifestation of your process for getting software from version control into the hands of your users.
― Jez Humble, Continuous Delivery Reliable Software Releases through Build and Deployment Automation
At Waze, we’ve been using Spinnaker for simultaneous deployments to multiple clouds since it was open sourced by Netflix in 2015.
However, implementing deployment pipelines can raise issues when your organization has more than 100 microservices (and growing), multiplied by the number of environments/regions/cloud providers.
- Managing hundreds of clusters and their deployment pipelines can quickly become a major maintenance burden. Once you have a few hundred deployment pipelines or more, keeping them up to date, or making a big change to all of them, is far from trivial.
- There’s no code reuse among pipelines, even though many of them are probably identical. For example, bake stages, deploy stages and resize/clone/destroy stages tend to be identical except for some parameters.
- Providing a paved road for deployments is easier said than done. Even though each development team should decide on their deployment strategy, it’s important to have a paved road — a way that works for most teams, which saves them time and effort. Start with that, and change as needed. However, there’s no easy way to create such a paved road and maintain it over time across all relevant pipelines in the system.
Unlike cloud vendor-specific solutions, Spinnaker managed pipeline templates work on top of all supported providers. (Currently: Azure, GCP, AWS, Kubernetes, OpenStack, App Engine and more are on the way.)
This means that for the first time, we can start realizing the dream of infrastructure as code across multiple clouds, whether you’re deploying to multiple public clouds, to a local Kubernetes on prem or to a mixed environment. We can see a future where automation, or some form of AI, decides to change instance types and other factors to reduce cost, improve utilization or mitigate real-time production incidents.
Runnable pipelines are composed of a pipeline template combined with pipeline configurations (using variables). Multiple configurations can use the same pipeline template as their base. In addition, pipeline templates support inheritance.
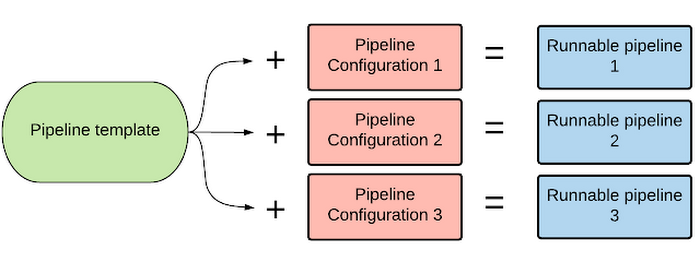
The benefits of pipeline templates
Multi-cloud/provider continuous delivery and infrastructure as code (without vendor lock-in)
Saving pipeline templates and configs in version control, subjecting them to code review and leaving an audit trail of why each infrastructure change was made are all extremely important for keeping your production system clean. These practices allow each production change to be understood, tracked in case there are any problems, and reproducible.
Being able to reproduce infrastructure enhances existing standards like reproducible builds, provides stability across the system and makes debugging, when required, easier. For example, changing an instance type, or adding a load balancer, is no longer just a “Clone” operation in Spinnaker; it’s now a code commit, a code review and a Jenkins job picking up the pipeline-template config change and publishing it to Spinnaker. After that, you just run the resulting pipeline(s) to apply the infrastructure change. You can easily track the infrastructure’s change history.
All of this is done in a way that supports multiple cloud providers. This may even be relevant for companies using Kubernetes on a single cloud provider, because they're required to interact with two sets of APIs and two control planes to manage their infrastructure. This is also why Kubernetes is treated as a separate cloud provider in Spinnaker. Spinnaker neatly abstracts all of that, while other solutions could lead to vendor lock-in.
Code reuse for pipelines
In a continuous-delivery environment, many pipelines can contain identical components, except for parameters. Managed pipeline templates provide a perfect way to reduce code duplication and centralize pipeline management, affecting hundreds or thousands of pipelines downstream. This method reduces mistakes, saves time and allows the same template-based configuration to provision multiple identical environments, such as staging, QA and production.
Automated checks and canary analysis on each infrastructure change
You’re probably familiar with using deployment pipelines to manage application and configuration changes, but now you can use them for infrastructure changes, too — changed instance types, firewall rules, load balancers and so on. Having an official deployment pipeline for each application means you can now run automated testing and canary analysis to even these changes, making infrastructure changes much safer.
Defining a clear paved road for deployments + override capabilities by each application
We've found that most deployment pipelines follow a very simple pattern:

However, most teams customize these pipelines based on their requirements. Here are just a few examples:
- Resize previous group to zero instead of destroying.
- Lots of parameters for the deploy stage, wait stage.
- Two canary analysis stages (first with 1% of traffic, the next with 50% of traffic).
- Various parameters passed on to the canary analysis.
Conditional stages use variables to control which stages are enabled. By utilizing conditional stages, you can use a single template for more than one use case. Here’s a video demo showing how it looks in practice.
Injecting stages allows any pipeline child template or configuration to add stages to the pipeline stage graph. For example, if a team uses a basic Bake -> Deploy -> Disable -> Wait -> Destroy pipeline template, they can easily inject a Manual Judgement stage to require a human decision before the previous group is disabled and destroyed. Here’s how this looks in practice.
Automatic deployment pipeline creation for new services
When a new service comes online — whether in the development, staging or production environments — pipeline templates can be used to create automatic deployment pipelines as a starting point. This reduces the effort of each team as they get a tested and fully working deployment pipeline out of the box (which can later on be customized if needed). Traffic guards and canary analysis give us the confidence to do this completely automatically.
Auto-generate pipelines to perform a rolling OS upgrade across all applications
Applying OS security updates safely across an entire large scale production system can be quite a challenge. Doing so while keeping the fleet immutable is even harder. Spinnaker pipeline templates combined with canary analysis can provide organizations with a framework to automate this task.
We use a weekly OS upgrade pipeline, which spawns the official deployment pipelines of all production applications, in a rolling manner, from least critical to most critical, spreading the upgrades to small batches which are then cascaded across the entire work week. Each iteration of the pipeline upgrades more applications than it did the day before. We use the official deployment pipelines for each application, sending a runtime parameter which says “Don’t change the binary or configuration — just rebake the base operating system with latest security updates,” and we get a new immutable image unchanged from the previous image except for those security updates. All this while still going through the usual canary analysis safeguards, load balancer health checks and traffic guards.
Pipeline templates can take this pattern one step further. Any new application can be automatically added to this main OS upgrade pipeline, ensuring the entire production fleet is always up to date for OS security updates.

Conclusion
Spinnaker pipeline templates solve a major issue for organizations running a lot of deployment pipelines. Plus, being able to control infrastructure as code for multiple providers, having it version-controlled and living alongside the application and configuration, removes a major constraint and could be a big step forward in taming operational chaos.Getting-started references
To get started with pipeline templates:- Set up Spinnaker.
- Read the spec, review the pipeline templates getting started guide.
- Check out the converter from existing pipelines into templates, a good place to start.
- roer, the spinnaker thin CLI used to validate and publish templates and configurations to Spinnaker. (Note: Better tooling is on the way.) Remember: roer pipeline-template plan is your friend. Also, orca.log is a great place to debug after publishing a template.
- Watch the full demo.
- Try out some example templates.
- Join the Spinnaker slack community and ask questions on the #declarative-pipelines channel.


