Google Kubernetes Engine 1.10 is generally available and ready for the enterprise
Yoshi Tamura
Product Manager, Google Kubernetes Engine and gVisor
[Editor's note: This is the first of many posts on enterprise capabilities enabled by Kubernetes Engine 1.10. For complete coverage, follow along here.]
Today, we’re excited to announce the general availability of Google Kubernetes Engine 1.10, which lays the foundation for new features to enable greater enterprise usage. Here on the Kubernetes Engine team, we’ve been thinking about challenges such as security, networking, logging, and monitoring that are critical to the enterprise for a long time. Now, in parallel to the GA of Kubernetes Engine 1.10, we are introducing a train of new features to support enterprise use cases. These include:
- Shared Virtual Private Cloud (VPC) for better control of your network resources
- Regional Persistent Disks and Regional Clusters for higher-availability and stronger SLAs
- Node Auto-Repair GA, and Custom Horizontal Pod Autoscaler for greater automation
Networking: global hyperscale network for applications with Shared VPC
Large organizations with several teams prefer to share physical resources while maintaining logical separation of resources between departments. Now, you can deploy your workloads in Google’s global Virtual Private Cloud (VPC) in a Shared VPC model, giving you the flexibility to manage access to shared network resources using IAM permissions while still isolating your departments. Shared VPC lets your organization administrators delegate administrative responsibilities, such as creating and managing instances and clusters, to service project admins while maintaining centralized control over network resources like subnets, routes, and firewalls. Stay tuned for more on Shared VPC support this week, where we’ll demonstrate how enterprise users can separate resources owned by projects while allowing them to communicate with each other over a common internal network.

Storage: high availability with Regional Persistent Disks
To make it easier to build highly available solutions, Kubernetes Engine will provide support for the new Regional Persistent Disk (Regional PD). Regional PD, available in the coming days, provides durable network-attached block storage with synchronous replication of data between two zones in a region. With Regional PDs, you don’t have to worry about application-level replication and can take advantage of replication at the storage layer. This replication offers a convenient building block for implementing highly available solutions on Kubernetes Engine.
Reliability: improved uptime with Regional Clusters, node auto-repair
Regional clusters, to be generally available soon, allows you to create a Kubernetes Engine cluster with a multi-master, highly-available control plane that spreads your masters across three zones in a region—an important feature for clusters with higher uptime requirements. Regional clusters also offers a zero-downtime upgrade experience when upgrading Kubernetes Engine masters. In addition to Regional Clusters, the node auto-repair feature is now generally available. Node auto-repair monitors the health of the nodes in your cluster and repairs any that are unhealthy.
Auto-scaling: Horizontal Pod Autoscaling with custom metrics
Our users have long asked for the ability to scale horizontally any way they like. In Kubernetes Engine 1.10, Horizontal Pod Autoscaler supports three different custom metrics types in beta: External (e.g., for scaling based on Cloud Pub/Sub queue length - one of the most requested use cases), Pods (e.g., for scaling based on the average number of open connections per pod) and Object (e.g., for scaling based on Kafka running in your cluster).You can read more about this here.
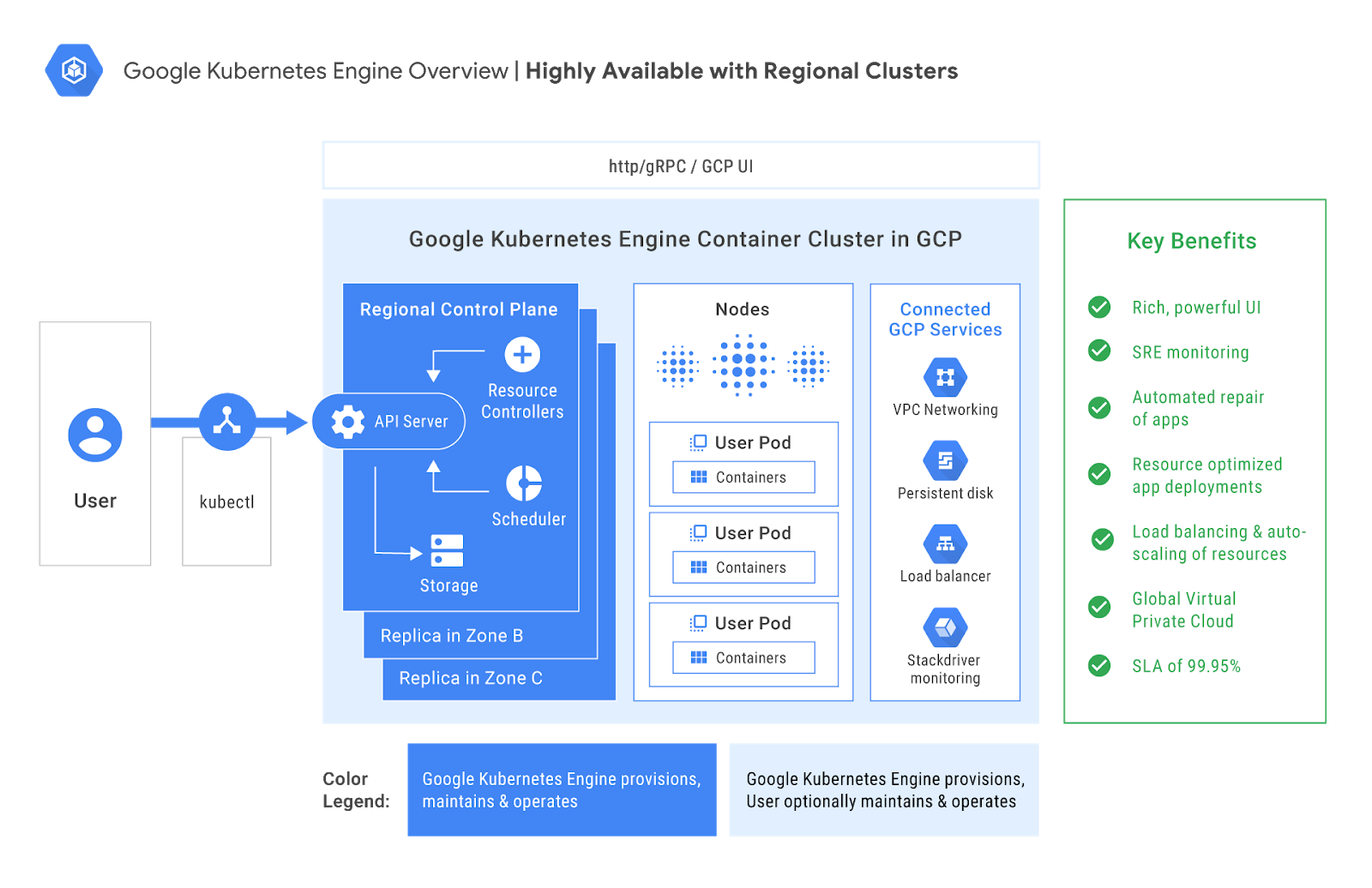
Kubernetes Engine enterprise adoption
Since we launched it in 2014, Kubernetes has taken off like a rocket. It is becoming “the Linux of the cloud,” according to Jim Zemlin, Executive Director of the Linux Foundation. Analysts estimate that 54 percent of Fortune 100 companies use Kubernetes across a spectrum of industries including finance, manufacturing, media, and others.Kubernetes Engine, the first production-grade managed Kubernetes service, has been generally available since 2015. Core-hours for the service have ballooned: in 2017 Kubernetes Engine core-hours grew 9X year over year, supporting a wide variety of applications. Stateful workload (e.g. databases and key-value stores) usage has grown since the initial launch in 2016, to over 40 percent of production Kubernetes Engine clusters.
Here is what a few of the enterprises who are using Kubernetes Engine have to say.
Alpha Vertex, a financial services company that delivers advanced analytical capabilities to the financial community, built a Kubernetes cluster of 150 64-core Intel Skylake processors in just 15 minutes and trains 20,000 machine learning models concurrently using Kubernetes Engine.
Google Kubernetes Engine is like magic for us. It’s the best container environment there is. Without it, we couldn’t provide the advanced financial analytics we offer today. Scaling would be difficult and prohibitively expensive.
Michael Bishop, CTO and Co-Founder, Alpha Vertex
Philips Lighting builds lighting products, systems, and services. Philips uses Kubernetes Engine to handle 200 million transactions every day, including 25 million remote lighting commands.
Google Kubernetes Engine delivers a high-performing, flexible infrastructure that lets us independently scale components for maximum efficiency.
George Yianni, Head of Technology, Home Systems, Philips Lighting
Spotify the digital music service that hosts more than 2 billion playlists and gives consumers access to more than 30 million songs uses Compute Engine for thousands of backend services.
Kubernetes is our preferred orchestration solution for thousands of our backend services because of its capabilities for improved resiliency, features such as autoscaling, and the vibrant open source community. Shared VPC in Kubernetes Engine is essential for us to be able to use Kubernetes Engine with our many GCP projects.
Matt Brown, Software Engineer, Spotify
Get started today and let Google Cloud manage your enterprise applications on Kubernetes Engine. To learn more about Kubernetes Engine, join us for a deep dive into the Kubernetes 1.10 enterprise features in Kubernetes Engine by signing up for our upcoming webinar, 3 reasons why you should run your enterprise workloads on Kubernetes Engine.



