Cloud Bigtable now supports HDD storage for big analytics workloads at lower cost
Misha Brukman
Product Manager, Cloud Bigtable
Today, we're announcing the availability of hard disk drive (HDD) as a storage option for your Google Cloud Bigtable data. HDD storage enables teams with large analytics workloads to cost-effectively keep more data, longer. Now you can continue to derive value from historical data instead of removing older data or letting it age out.
We launched Cloud Bigtable — a fully-managed, high-performance, scalable NoSQL database, with an HBase-compatible API — a year ago. Since launch, we’ve seen amazing adoption for many workloads, including IoT, financial services and advertising.
Bigtable, which is the same database that drives many of Google’s core services, including Search, Analytics, Maps and Gmail, stores data on an underlying distributed file system that has been optimized for high-throughput read and write workflows. As a result, Cloud Bigtable can offer HDD as a storage option with very high performance, even when compared to HBase running with local SSD. To demonstrate it, we decided to run some benchmarks.
First, we created several clusters:
- a 3-node Cloud Bigtable HDD cluster
- a 3-node Cloud Bigtable SSD cluster
- an HBase cluster with 4 Google Compute Engine VM instances, one running the master and 3 region servers, each running on n1-standard-8 VM
We ran the ingestion test below with 8 n1-standard-8 Google Compute Engine VM instances, using the following command:
$ hbase pe -Dmapreduce.map.speculative=false \
--presplit=60 --size=100 sequentialWrite 8
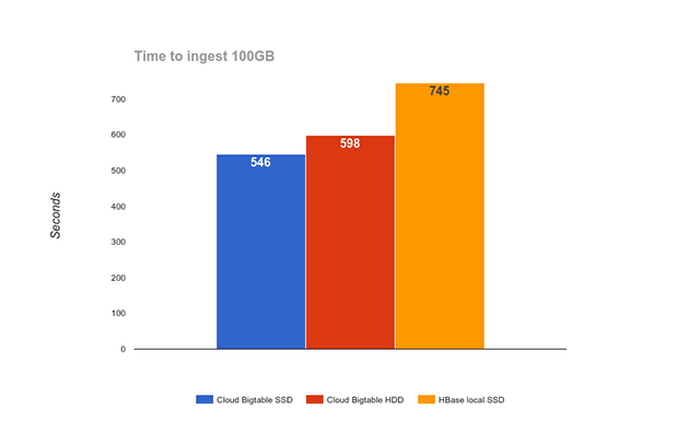
As the graph below shows, Cloud Bigtable with HDD ingests 100GB of data in less time than HBase running on local SSD.
Similarly, Cloud Bigtable performs really well at scanning the data. We ran the scan benchmark with the following command:
$ hbase pe -Dmapreduce.map.speculative=false --size=100 scan 8
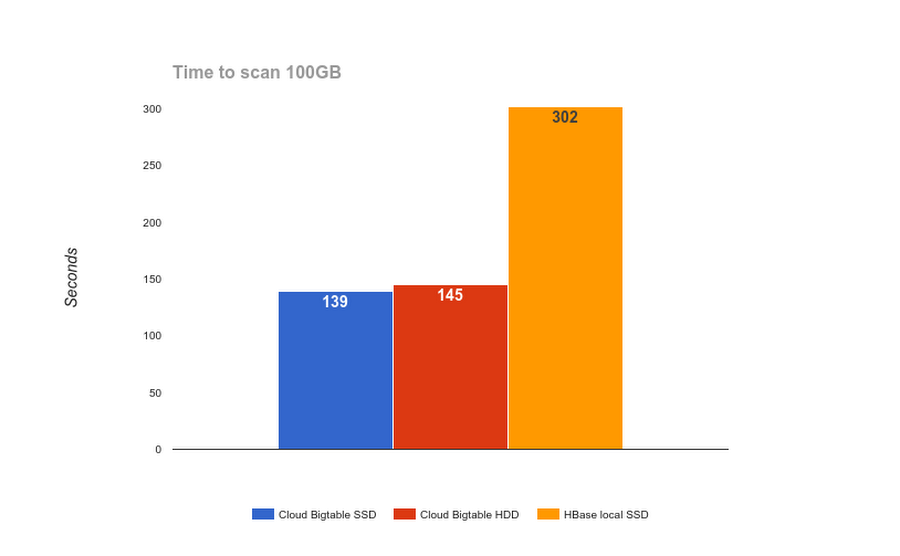
As you can see from the graphs above, Cloud Bigtable HDD does really well with ingestion as well as scans. However, for interactive use cases in which user-visible latency matters, you should choose SSD for low-latency reads and writes as well as a high number of simultaneous reads and writes. Below we can see the performance of random reads for SSD vs. HDD in Cloud Bigtable.
We ran the following command on our Cloud Bigtable clusters after populating each with 1TB of data. This benchmark starts 10 threads, each doing 45K random reads on a 400GB subset of the data; we're measuring total time elapsed.
$ hbase pe -Dmapreduce.map.speculative=false --size=400 \
--sampleRate=0.001 randomRead 1
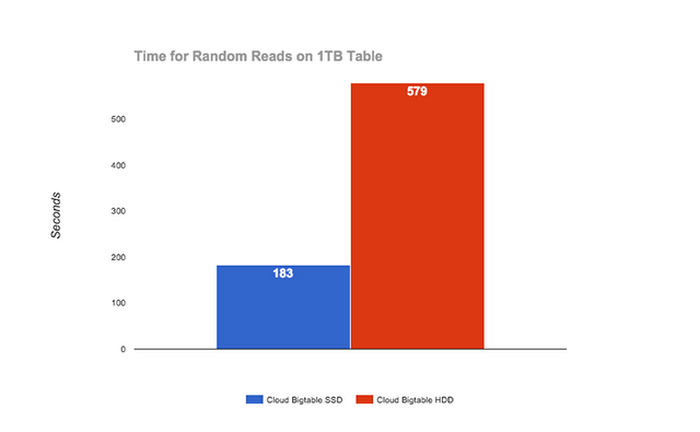
Here we can clearly see the value of SSD in powering real-time applications where end-user latency matters.
If you’re looking for a less expensive option for very large, batch-oriented or latency-insensitive analytics workloads, then Cloud Bigtable HDD storage may be a good choice for you, as it reduces the per-GB storage costs, while still providing a high throughput, fully-managed database.
To get started with Cloud Bigtable to power your large-scale analytics use cases, start with the documentation, compare SSD and HDD storage options and pricing, and try out the quickstart to begin your journey.



