Around the world: landmark detection with the Cloud Vision API
Sara Robinson
Developer Advocate, Google Cloud Platform
I’ve been playing around with Google’s machine learning tools recently, especially image recognition. By far, my favorite feature of the Cloud Vision API is landmark detection: you send the API a picture of a popular (or obscure) landmark and it returns JSON with the name of the landmark, its latitude / longitude coordinates, a bounding box indicating where the landmark was found in the image, and even more landmark metadata. To see the Vision API in action and understand how it works behind the scenes, let’s look at some landmarks from around the world.
First, let’s see what a JSON response looks like. We’ll start with this image of the Eiffel Tower:

If at first glance you thought this was a picture of the Eiffel Tower in Paris, you were wrong (don’t worry, I was too). But the Vision API was not fooled. Let’s see what it found:
It’s actually a picture of the Paris Hotel and Casino in Las Vegas! We can get even more data about this landmark by digging into the response.
The mid is an ID for the entity in Google’s Knowledge Graph, which has its own API that we can use to get more information on the entity. description is the name of the landmark and score is a value in the [0,1] range indicating how confident the API is that the image is in fact of the suggested landmark. If we look at the boundingPoly vertices, we can find the exact region in the image where the API found the Eiffel Tower Casino. And the latitude / longitude values point us to its exact location.
But how exactly is the Vision API able to differentiate between the Eiffel Tower in Vegas and Paris? And what’s included in its database of landmarks? I chatted with Tobias Weyand, a software engineer on the landmark recognition model, to find out the details.
Landmark detection behind the scenes
When you call the Vision API’s landmark detection method, you’re accessing the same machine learning models used to power landmark search in Google Photos (for example, when you search your photo library for “Golden Gate Bridge”). These landmark models also power the “Search by Image” feature in Google Images.To perform landmark recognition, the Vision API references a database of over 70,000 landmarks with Knowledge Graph entities, populated by analyzing public photos. Each row in this database includes the name, location and Knowledge Graph mid of each landmark. This landmark data is continuously updated to include new landmarks.
To build the landmark models, a landmark mining pipeline clusters similar photos together and tags them with metadata. The pipeline works like this:
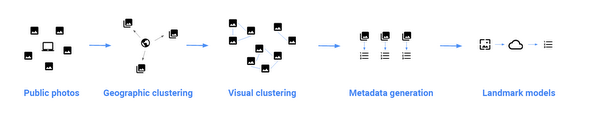
If the pipeline identifies an image as a possible landmark, it's sent to the next step of the pipeline for clustering. Photos are then clustered in two ways: by geolocation data and by visual match. One cluster is mapped to a single landmark. For example, a cluster could include multiple photos of the Statue of Liberty taken at different angles, some with objects in the foreground, and some with textual metadata that helps identify the landmark. Once a cluster is identified, the pipeline generates the associated metadata for the landmark: its name, Knowledge Graph mid and latitude / longitude coordinates. Clusters that aren’t associated with a real landmark are discarded.
That explains how the canonical list of landmarks was built, but what happens when an image is sent to the landmark recognition endpoint? The clusters of pictures for a given landmark are used as model images, and a given query image is matched against them using the nearest neighbor principle. A match score is then computed, which reflects the confidence of the visual match between the query and the closest matching model image. If the score is above a certain threshold, it's identified as a landmark. This clustering approach allows the Vision API to identify the same landmark as seen from different perspectives. For example, the Vision API identified both photos below as the Trevi Fountain in Rome. I’ve highlighted the bounding box returned by the Vision API in blue (this is the region in the image where the API identified the landmark).


Two images taken at different times of day, and from different angles, are both mapped to the same landmark by the API.
You can also see the API’s JSON response for both Trevi Fountain photos:
Next steps
I’ll end with my personal favorite landmark detection response from a photo taken in Jordan with my teammates Bret and Robert. I initially sent it to the Vision API expecting only a face detection response, but was pleasantly surprised with the results from landmark detection:



