What's new in Google Cloud databases: More unified. More open. More intelligent.
Andi Gutmans
VP/GM, Data Cloud, Google Cloud
Every organization is going through some form of digital transformation and serving their customers in new ways. Modern conveniences have taught consumers that their experience is paramount — no matter how big or small the company or how complex the problem. Powering these digital experiences are operational databases, the backbone of most applications. The quality of the customer experience is critically dependent on how reliable, scalable, performant, and secure these operational databases are.
At Google Cloud, our mission is to accelerate every organization’s ability to digitally transform. A large part of that is helping our customers and partners innovate faster with a unified, open, and intelligent data cloud platform. At Google Cloud Next, we’re excited to announce new Google Cloud databases capabilities that enable more opportunities for growth and innovation within your organization.
The four key areas we’ve focused on are:
Building a unified and integrated data cloud for transactional and analytical data
Breaking free from legacy databases and our commitment to open ecosystems and standards
Infusing AI and machine learning across data-driven workflows
Empowering builders to be more productive and impactful
Unifying transactional and analytical data
Traditionally, data architectures have separated transactional and analytical workloads, including their underlying databases — and for good reason. Transactional databases are optimized for fast reads and writes, while analytical databases are optimized for aggregating large data sets. Because these systems are largely decoupled, it can create many inefficiencies. Enterprises struggle to piece together disparate data solutions, they spend valuable time managing complex data pipelines, and they expend a lot of effort replicating data between databases. Ultimately, they find it difficult to build intelligent, data-driven applications.
At Google Cloud, we’re uniquely positioned to solve this problem because of how we’ve architected our data platform. Our transactional and analytical databases are built on a highly scalable distributed storage system, with disaggregated compute and storage, and high-performance Google-owned global networking. This combination allows us to provide tightly integrated data cloud services across Cloud Spanner, Cloud Bigtable, AlloyDB for PostgreSQL, and BigQuery.
We’re excited to announce the Preview of Bigtable change streams for easy data replication. Bigtable is a highly performant, fully managed NoSQL database service that processes over 5 billion requests per second at peak and has more than 10 exabytes of data under management. With change streams, you can track writes, updates, and deletes to Bigtable databases and replicate them to downstream systems such as BigQuery. Change streams helps support real-time analytics, event-based architectures, and multicloud operational database deployments. This capability joins recently launched Spanner change streams.
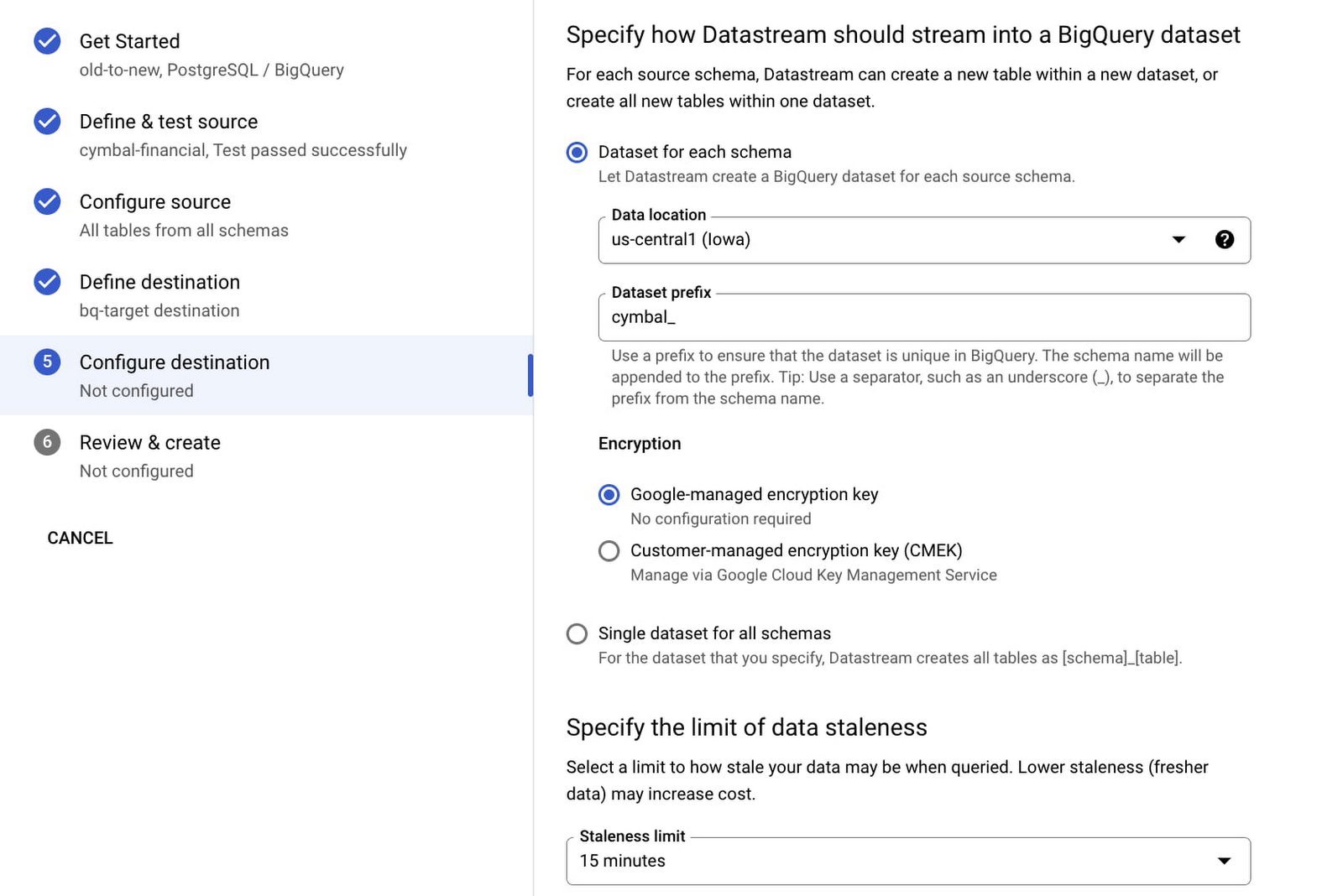
We also recently announced Datastream for BigQuery in Preview, which provides easy replication of data from operational database sources such as AlloyDB, PostgreSQL, MySQL, and Oracle, directly into BigQuery with a few simple clicks. With a serverless, auto-scaling architecture, Datastream allows you to easily set up an Extract, Load, Transform (ELT) pipeline for low-latency data replication, enabling real-time insights in BigQuery.
Greater freedom and flexibility with open source and open standards
In recent years, organizations have become unwilling to tolerate opaque costs, restrictive licensing, and vendor lock-in, and we’re seeing them increasingly adopt open-source databases and open standards. In particular, PostgreSQL has emerged as a leading alternative to legacy, proprietary databases because of its rich functionality, ecosystem extensions, and enterprise readiness.
To make sure we support your workloads, we offer three PostgreSQL options. First, AlloyDB for PostgreSQL is a PostgreSQL-compatible database, currently in preview, that delivers the performance, availability, scale, and functionality needed to support commercial-grade workloads. In our performance tests, AlloyDB is more than 4x faster than standard PostgreSQL for transactional workloads. We’re excited to announce a major expansion of the AlloyDB partner ecosystem, with more than 30 partner solutions to support business intelligence, analytics, data governance, observability, and system integration.
We also recently announced that our Database Migration Service supports migration of PostgreSQL databases to AlloyDB, in preview. This service helps you migrate to AlloyDB from any PostgreSQL database — whether it’s on premises, self-managed on Google Cloud, or on another cloud — in an easy-to-use, secure, and serverless manner, and with minimal downtime.
The second PostgreSQL offering is Cloud SQL for PostgreSQL, a fully managed, up-to-date version of PostgreSQL for easy lift-and-shift migrations or new application development. We support the most popular PostgreSQL extensions and over 100 database flags and you get the same experience of open source PostgreSQL, with the strong management, availability, and security of Cloud SQL. It’s no surprise that Cloud SQL is used by more than 90% of the top 100 Google Cloud customers. New customers can get started with a Cloud SQL free trial.
Finally, Spanner, our globally-distributed relational database with strong external consistency and up to 99.999% availability, offers a PostgreSQL interface that lets you take advantage of familiar tools and skills from the PostgreSQL ecosystem. We’re continuing to prioritize PostgreSQL compatibility of Spanner, and are excited to announce a key milestone — the Spanner PostgreSQL interface now supports its first group of PostgreSQL ecosystem drivers, starting with Java (JDBC) and Go (pgx). This support can reduce the cost of migrating apps to Spanner using off-the-shelf PostgreSQL drivers your developers already use. And to further democratize access to Spanner, we recently announced free trial instances.
Infusing AI and machine learning across data-driven workflows
AI and machine learning (ML) are critical to data-driven transformations, helping you get more value from your data. Among their many benefits, AI and ML tools can help recognize patterns, enhance and improve operational capabilities with new insights, and create compelling customer experiences. Most companies face significant hurdles not only trying to build ML models, but also integrating them into applications without extensive coding and specialized AI/ML skills. Harnessing AI and ML in workflows of all kinds should be easy, especially within your data platform.
At Google Cloud, we’ve invested in AI and ML technologies for both database system optimizations to make our services more intelligent, and for AI and ML service integrations. For database system optimizations, capabilities such as Cloud SQL cost recommenders and AlloyDB autopilot make it easier for database administrators and DevOps teams to manage performance and capacity for large fleets of databases.
In addition to infusing AI and ML into our databases, we’ve been focused on providing integration with Vertex AI, Google Cloud’s machine learning platform, to enable model inferencing directly within the database transaction. We’re excited to announce, in preview, the integration of Vertex AI with Spanner. You can now use a simple SQL statement in Spanner to call a machine learning model in Vertex AI.
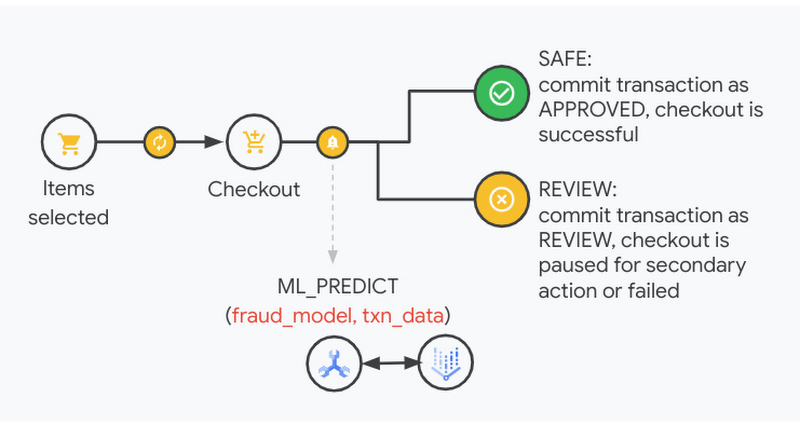
With this integration, AlloyDB and now Spanner can allow data scientists to build models easily in Vertex AI and developers to access these models using the SQL query language. For example, retailers need to detect fraudulent transactions during the checkout process and take appropriate action. With the Vertex AI integration, you can simply call the fraud detection ML model in the Spanner query using a function like ML_PREDICT.
Empowering builders to be more productive
Building, testing and deploying apps is cumbersome. Plus, even after an app is built, maintaining it requires regular monitoring, performance tuning, scaling, and security patching — all of which distract developers from strategic initiatives. As a result, organizations can be slow to innovate and may fall behind their competition. That’s why we prioritize the developer experience and are excited to share the latest advancements we’re making in Firestore, Cloud SQL, and Spanner.
Developers love Firestore because of how fast they can build an app end to end. More than 4 million databases have been created in Firestore, and Firestore applications power more than 1 billion monthly active end users using Firebase Auth. But what happens when the application grows? We want to ensure developers can focus on productivity, even when their apps are experiencing hyper-growth. To achieve this, we’ve made three updates to Firestore all aimed at supporting growth and reducing costs.
For applications using Firestore as a backend-as-a-service, we've removed the limits for write throughput and concurrent active connections. Now, if your app becomes an overnight success, you can be confident that Firestore will scale smoothly. Additionally, we’re rolling out the COUNT() function in preview next week, which gives you the ability to perform cost-efficient, scalable, count aggregations. This capability supports use cases like counting the number of friends a user has, or determining the number of documents in a collection. Finally, to help you efficiently manage storage costs, we’ve introduced time-to-live (TTL) which enables you to pre-specify when documents should expire, and can rely on Firestore to automatically delete expired documents.
We’re also making advancements to security and performance in Cloud SQL and Spanner. Now it can be easier to detect, diagnose, and prevent database performance problems with Cloud SQL Query Insights for MySQL (also available for PostgreSQL). We recently introduced PostgreSQL System Insights in preview, and are excited to announce two additional types of Cloud SQL recommenders. Security recommenders continuously detect security vulnerabilities and check for risky security configurations such as a public IP address with broad access or unencrypted connections. Performance recommenders, meanwhile, help identify and resolve common misconfigurations that increase the risk of performance degradation or downtime.
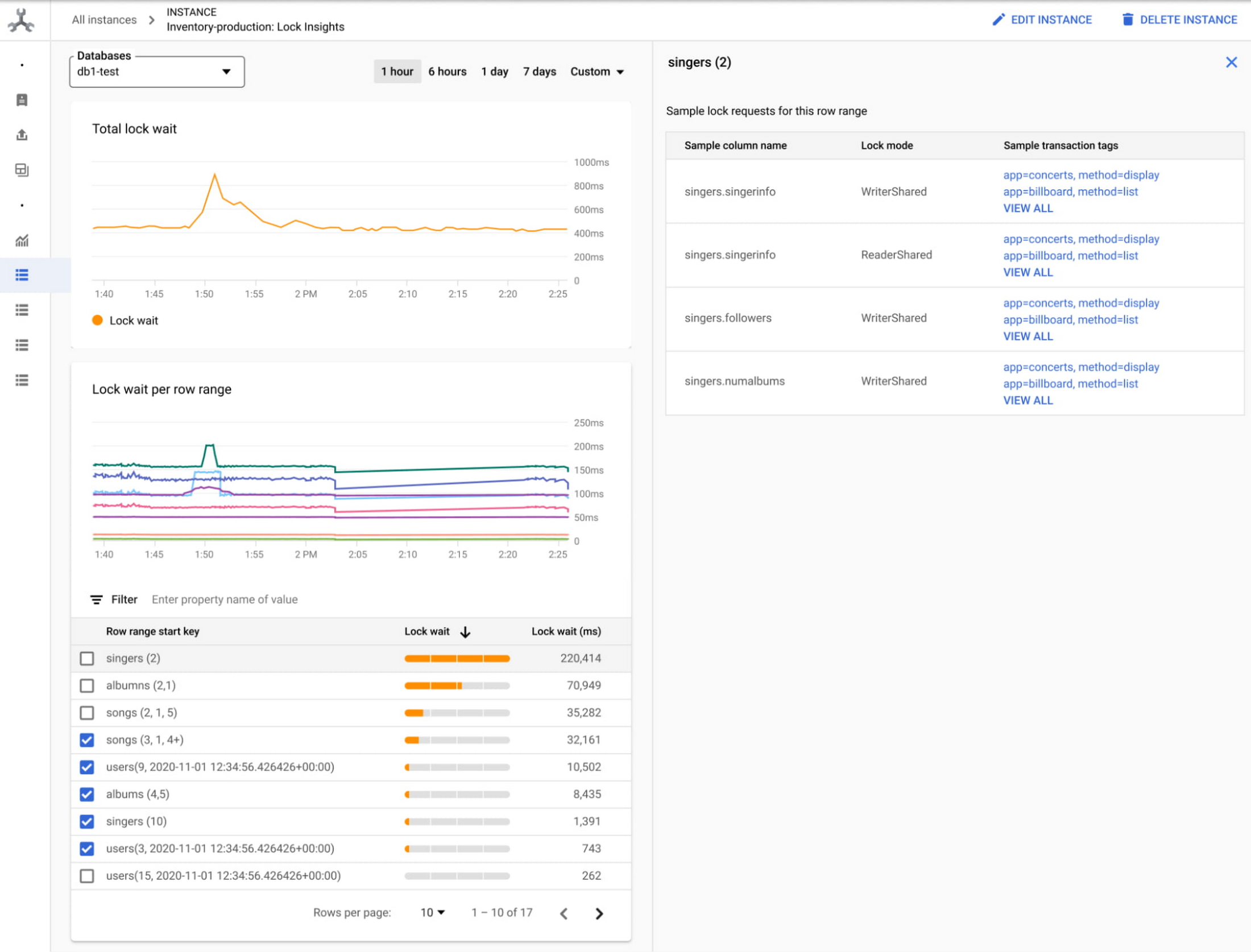
We recently launched Query insights for Spanner which provides pre-built dashboards for quickly diagnosing query performance issues. In addition, lock and transaction insights for Spanner (coming Q4, 2022) will help troubleshoot lock contention issues on Spanner that can slow down applications. You can easily correlate row-ranges, columns, and sample transactions contending for locks and debug high latency transactions using granular metrics.
Tap into new possibilities
The future of data has endless possibilities, and we’re excited to partner with you to help accelerate your data-driven business transformation.
Tune into Next ‘22 for more details on the announcements, and get inspired by learning how companies like MLB, PLAID, Forbes, DaVita, Credit Karma, and Box are innovating with Google Cloud databases.




