Low-latency fraud detection with Cloud Bigtable
Ibrahim Kettaneh
Software Engineer: Cloud Bigtable
Billy Jacobson
Developer Advocate, Cloud Bigtable
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialEach time someone makes a purchase with a credit card, financial companies want to determine if that was a legitimate transaction or if it is using a stolen credit card, abusing a promotion or hacking into a user's account. Every year, billions of dollars are lost due to credit card fraud, so there are serious financial consequences. Companies dealing with these transactions need to balance predicting fraud accurately and predicting fraud quickly.
In this blog post, you will learn how to build a low-latency, real-time fraud detection system that scales seamlessly by using Bigtable for user attributes, transaction history and machine learning features. We will follow an existing code solution, examine the architecture, define the database schema for this use case, and see opportunities for customizations.
The code for this solution is on GitHub and includes a simplistic sample dataset and pre-trained fraud detection model plus a Terraform configuration. This blog and example's goal is to showcase the end-to-end solution rather than machine learning specifics since most fraud detection models in reality can involve hundreds of variables. If you want to spin up the solution and follow along, clone the repo and follow the instructions in the README to set up resources and run the code.
Fraud detection pipeline
When someone initiates a credit card purchase, the transaction is sent for processing before the purchase can be completed. The processing includes validating the credit card, checking for fraud, and adding the transaction to the user's transaction history. Once those steps are completed, and if there is no fraud identified, the point of sale system can be notified that the purchase can finish. Otherwise, the customer might receive a notification indicating there was fraud, and further transactions can be blocked until the user can secure their account.
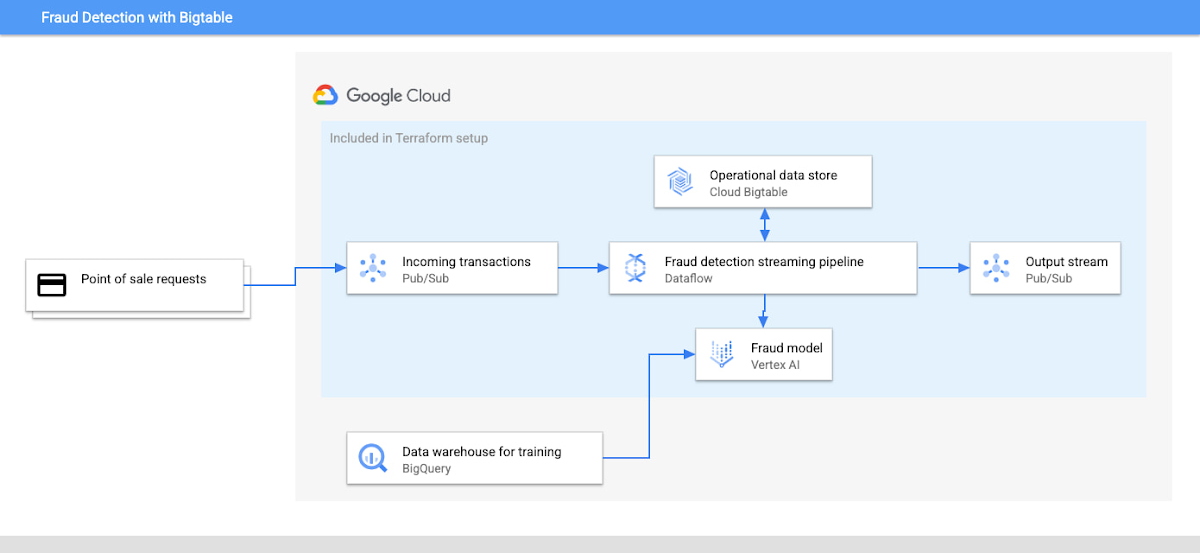
The architecture for this application includes:
Input stream of customer transactions
Fraud detection model
Operational data store with customer profiles and historical data
Data pipeline for processing transactions
Data warehouse for training the fraud detection model and querying table level analytics
Output stream of fraud query results
The architecture diagram below shows how the system is connected and which services are included in the Terraform setup.
Pre-deployment
Before creating a fraud detection pipeline, you will need a fraud detection model trained on an existing dataset. This solution provides a fraud model to try out, but it is tailored for the simplistic sample dataset. When you're ready to deploy this solution yourself based on your own data, you can follow our blog on how to train a fraud model with BigQuery ML.
Transaction input stream
The first step towards detecting fraud is managing the stream of customer transactions. We need an event-streaming service that can horizontally scale to meet the workload traffic, so Cloud Pub/Sub is a great choice. As our system grows, additional services can subscribe to the event-stream to add new functionality as part of a microservice architecture. Perhaps the analytics team will subscribe to this pipeline for real time dashboards and monitoring.
When someone initiates a credit card purchase, a request from the point of sale system will come in as a Pub/Sub message. This message will have information about the transaction like location, transaction amount, merchant id and customer id. Collecting all the transaction information is critical for us to make an informed decision since we will update the fraud detection model based on purchase patterns over time as well as accumulate recent data to use for the model inputs. The more data points we have, the more opportunities we have to find anomalies and make an accurate decision.
Transaction pipeline
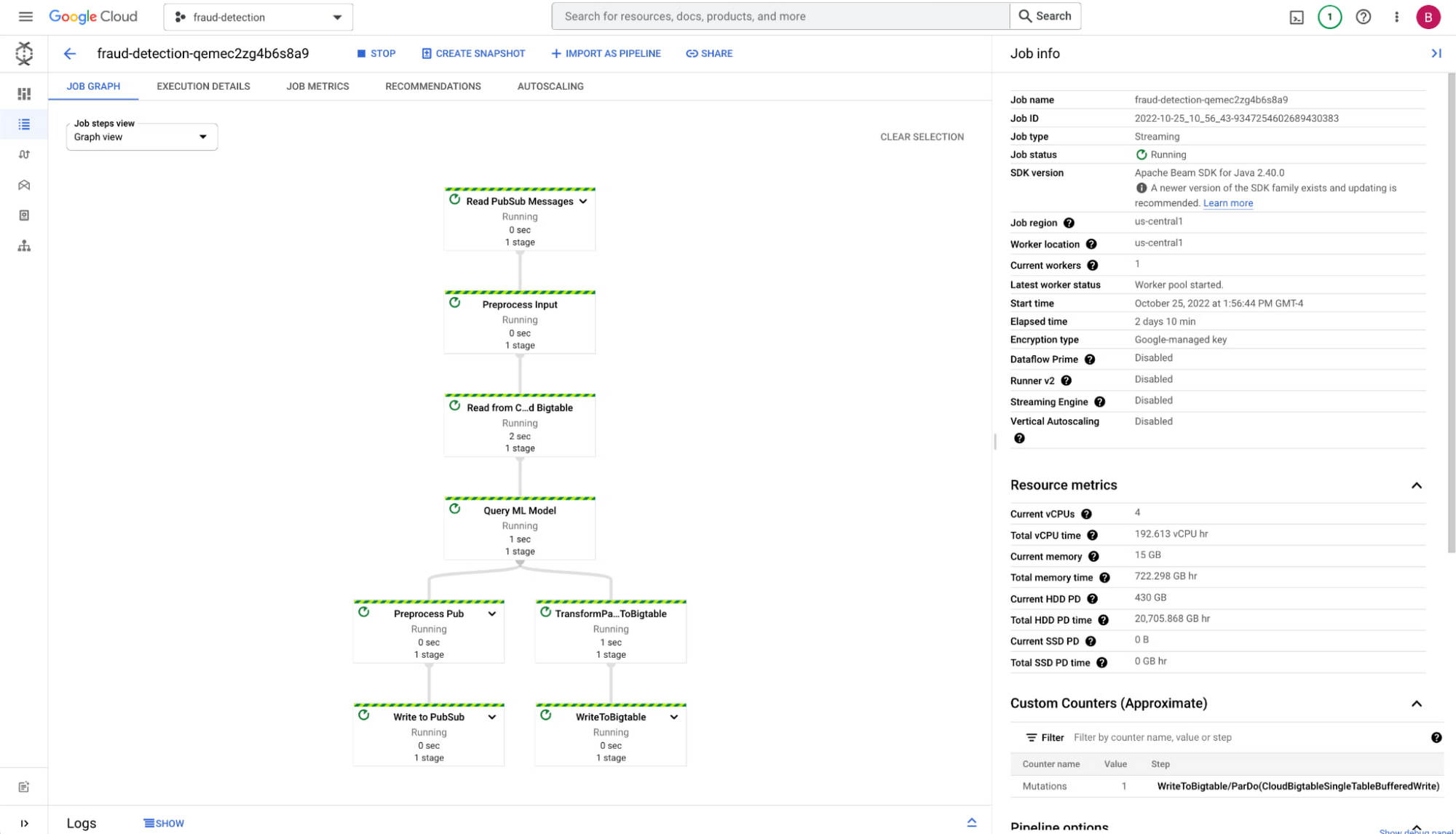
Pub/sub has built-in integration with Cloud Dataflow, Google Cloud's data pipeline tool, which we will use for processing the stream of transactions with horizontal scalability. It's common to design Dataflow jobs with multiple sources and sinks, so there is a lot of flexibility in pipeline design. Our pipeline design here only fetches data from Bigtable, but you could also add additional data sources or even 3rd party financial APIs to be part of the processing. Dataflow is also great for outputting results to multiple sinks, so we can write to databases, publish an event stream with the results, and even call APIs to send emails or texts to users about the fraud activity.
Once the pipeline receives a message, our Dataflow job does the following:
Fetch user attributes and transaction history from Bigtable
Request a prediction from Vertex AI
Write the new transaction to Bigtable
Send the prediction to a Pub/Sub output stream
Operational data store
To detect fraud in most scenarios, you cannot just look at just one transaction in a silo – you need the additional context in real time in order to detect an anomaly. Information about the customer's transaction history and user profile are the features we will use for the prediction.
We'll have lots of customers making purchases, and since we want to validate the transaction quickly, we need a scalable and low-latency database that can act as part of our serving layer. Cloud Bigtable is a horizontally-scalable database service with consistent single-digit millisecond latency, so it aligns great with our requirements.
Schema design
Our database will store customer profiles and transaction history. The historical data provides context which allows us to know if a transaction follows its customer's typical purchase patterns. These patterns can be found by looking at hundreds of attributes. A NoSQL database like Bigtable allows us to add columns for new features seamlessly unlike less flexible relational databases which would require schema changes to augment.
Data scientists and engineers can work to evolve the model over time by mixing and matching features to see what creates the most accurate model. They can also use the data in other parts of the application: generating credit card statements for customers or creating reports for analysts. Bigtable as an operational data store here allows us to provide a clean current version of the truth shared by multiple access points within our system.
For the table design, we can use one column family for customer profiles and another for transaction history since they won't always be queried together. Most users are only going to make a few purchases a day, so we can use the user id for the row key. All transactions can go in the same row since Bigtable's cell versioning will let us store multiple values at different timestamps in row-column intersections.
Our table example data includes more columns, but the structure looks like this:
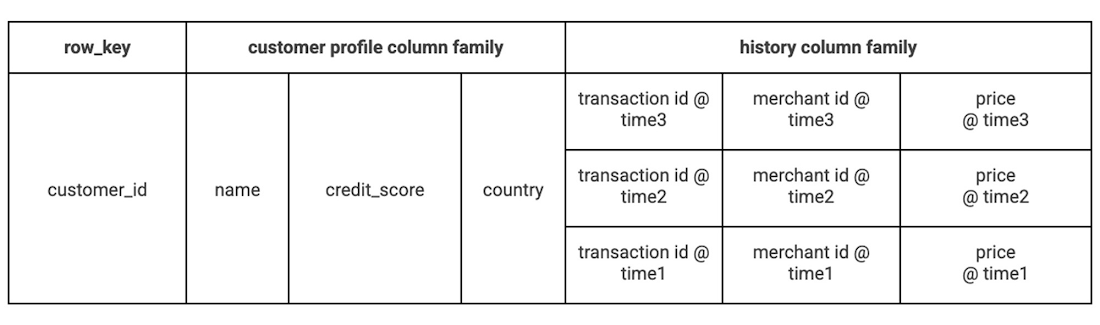
Since we are recording every transaction each customer is making, the data could grow very quickly, but garbage collection policies can simplify data management. For example, we might want to keep a minimum of 100 transactions then delete any transactions older than six months.
Garbage collection policies apply per column family which gives us flexibility. We want to retain all the information in the customer profile family, so we can use a default policy that won't delete any data. These policies can be managed easily via the Cloud Console and ensure there's enough data for decision making while trimming the database of extraneous data.
Bigtable stores timestamps for each cell by default, so if a transaction is incorrectly categorized as fraud/not fraud, we can look back at all of the information to debug what went wrong. There is also the opportunity to use cell versioning to support temporary features. For example, if a customer notifies us that they will be traveling during a certain time, we can update the location with a future timestamp, so they can go on their trip with ease.
Query
With our pending transaction, we can extract the customer id and fetch that information from the operational data store. Our schema allows us to do one row lookup to get an entire user's information.
Request a prediction
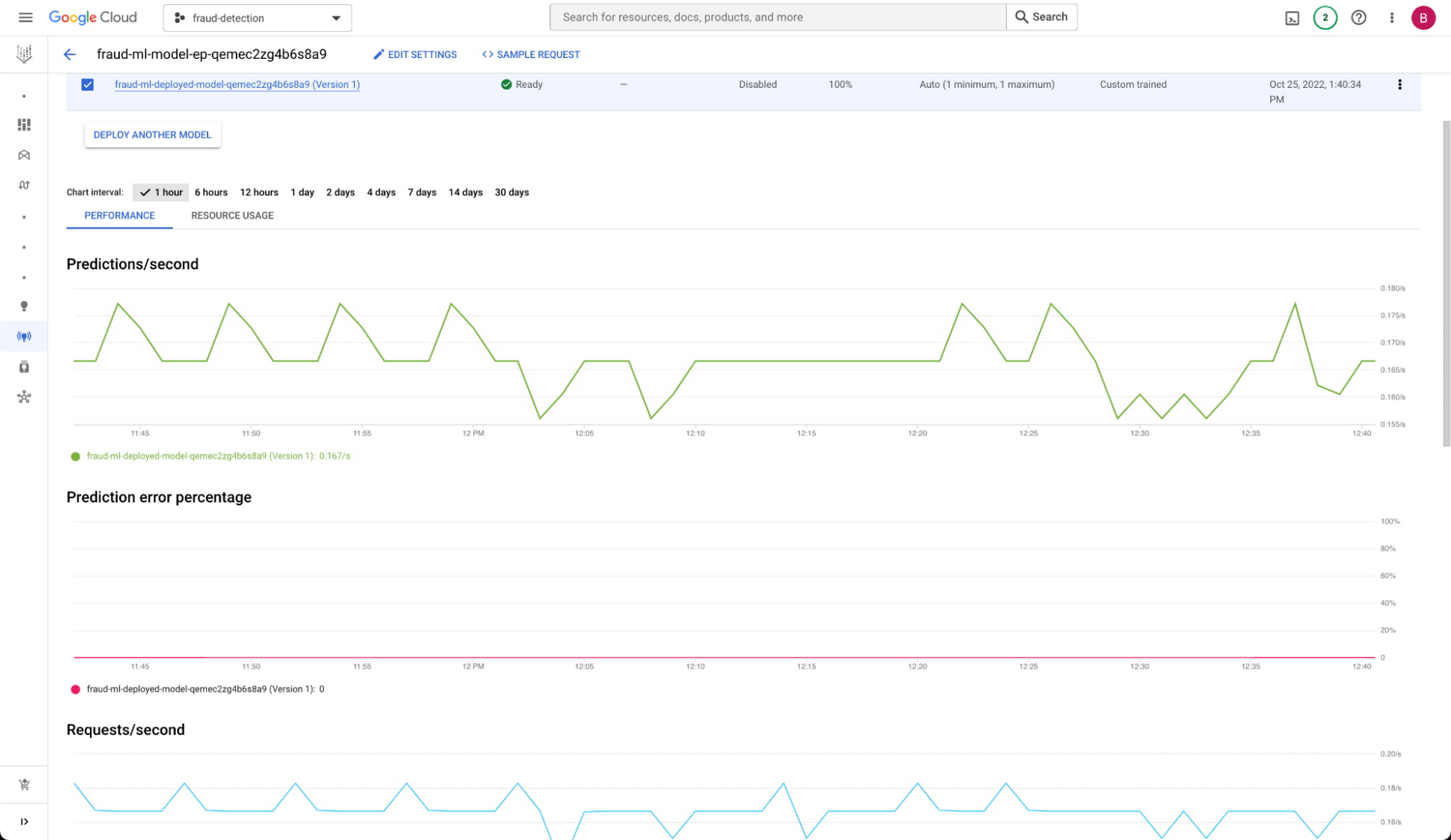
Now, we have our pending transaction and the additional features, so we can make a prediction. We took the fraud detection model that we trained previously and deployed it to Vertex AI Endpoints. This is a managed service with built-in tooling to track our model's performance.
Working with the result
We will receive the fraud probability back from the prediction service and then can use it in a variety of ways.
Stream the prediction
We will receive the fraud probability back from the prediction service and need to pass the result along. We can send the result and transaction as a Pub/Sub message in a result stream, so the point of sale service and other services can complete processing. Multiple services can react to the event stream, so there is a lot of customization you can add here. One example would be to use the event stream as a Cloud Function trigger for a custom function that notifies users of fraud via email or text.
Another customization you could add to the pipeline would be to include a mainframe or a relational database like Cloud Spanner or AlloyDB to commit the transaction and update the account balance. The payment will only go through if the balance can be removed from the remaining credit limit otherwise the customer's card will have to be declined.
Update operational data store
We also can write the new transaction and its fraud status to our operational data store in Bigtable. As our system processes more transactions, we can improve the accuracy of our model by updating the transaction history, so we will have more data points for future transactions. Bigtable scales horizontally for reading and writing data, so keeping our operational data store up to date requires minimal additional infrastructure setup.
Making test predictions
Now that you understand the entire pipeline and it's up and running, we can send a few transactions to the Pub/Sub stream from our dataset. If you've deployed the codebase, you can generate transactions with gcloud and look through each tool in the Cloud Console to monitor the fraud detection ecosystem in real time.
Run this bash script from the terraform directory to publish transactions from the testing data:
Summary
In this piece, we've looked at each part of a fraud detection pipeline and how to ensure each has scale and low-latency using the power of Google Cloud. This example is available on GitHub, so explore the code, launch it yourself, and try making modifications to match your needs and data. The Terraform setup included uses dynamically scalable resources like Dataflow, Pub/sub, and Vertex AI with an initial one node Cloud Bigtable instance that you can scale up to match your traffic and system load.


