From MySQL to NoSQL: Bitly’s big move to Bigtable
Zoe McCormick
Senior Software Engineer, Bitly
Editor’s note: Bitly, the link & QR Code management platform, migrated 80 billion rows of link data to Cloud Bigtable. Here’s how and why they moved this data from a MySQL database, all in just six days.
Our goal at Bitly is simple: Make your life easier with connections. Whether you're sharing links online, connecting the physical and digital worlds with custom QR Codes or creating a killer Link-in-bio, we're here to help make that happen.
Bitly customers run the gamut from your local middle school to most of the Fortune 500 with every use case you can think of in play. On a typical day, we process approximately 360 million link clicks and QR Code scans and support the creation of 6-7 million links or QR Codes for more than 350,000 unique users.
At the heart of our platform is link data consisting of three major datasets for the approximately 40 billion active links in our system (and counting). For years we stored this data in a self-managed, manually sharded MySQL database. While that setup served us well over time, it did present some challenges as we looked to expand and move into the future.
MySQL: Challenges and growing pains
First, performing operational actions like software and security upgrades or database host provisioning — all while keeping the databases 100% available for our customers — was challenging to say the least.
Additionally, the backup and restore process was both costly and time-consuming. Daily backups for the growing dataset took almost an entire day to complete. And if we ever had to restore the entire data set, it would have undoubtedly taken at least two people working for several days — not a fun prospect and thankfully something we never had to do.
While manual sharding for MySQL offers good key distribution across physical and logical shards, it’s pretty high-maintenance — we tried to avoid touching our sharding config because of how error-prone making changes was. And even with a forward-thinking shard allocation, we found this approach to have a limited lifespan.
And finally, when we turned our attention towards multi-region and global distribution, manually sharded MySQL proved to be a major hurdle, especially compared to the convenience of a managed service that handles geo-distribution for us.
As we thought about the future of our data and how to best meet our expansion goals, we determined that an update was necessary. We needed a system more set up for growth and increased reliability, preferably one with built-in functionality for replication and scaling. Investigation and research brought us to Cloud Bigtable, Google Cloud’s enterprise-grade NoSQL database service.
The Bitly link, in a nutshell
Before we dive into the Bigtable migration, it's useful to understand the basics of our link management system. When a user shortens a long URL with Bitly, information is saved to the backend data stores through our API layer. This information consists of a Bitly short link and the corresponding destination link for proper routing, as well as some additional metadata. When a user clicks the Bitly short link, our services query these same backend data stores for the redirect destination for the request. This basic flow, which also includes other Bitly link options like custom back-halves, is the backbone of the Bitly link management platform.
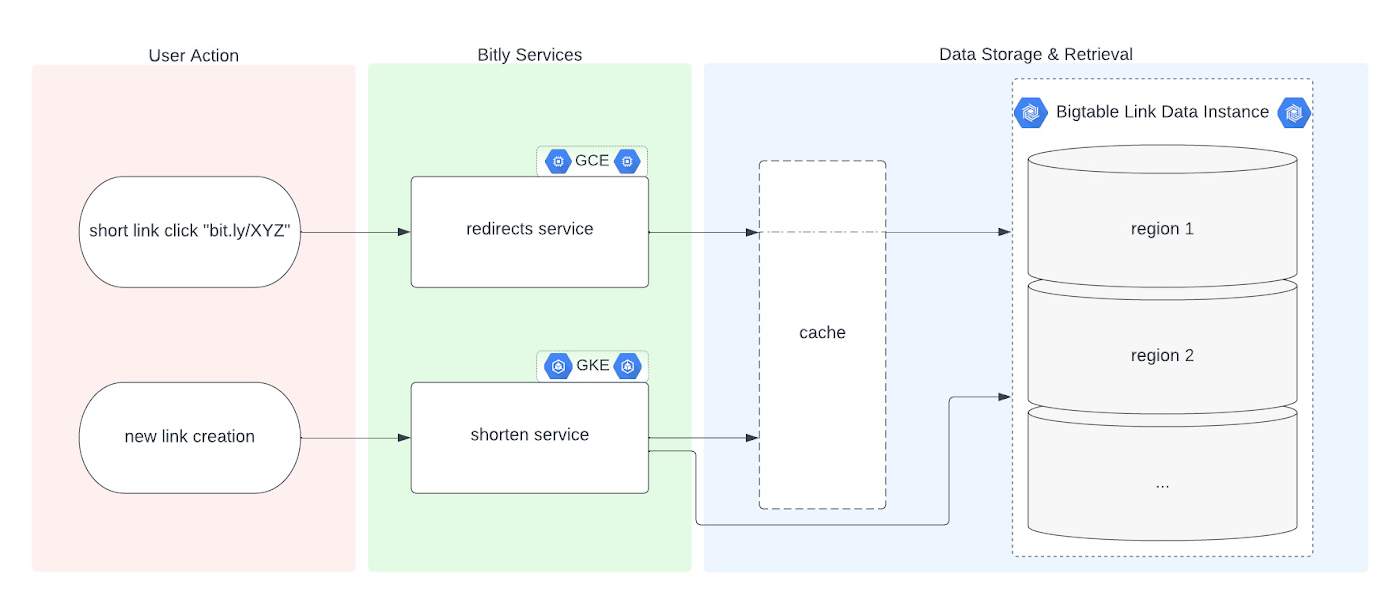
Where Bigtable comes in
As mentioned, after researching our options, the solution that best fit our needs was Bigtable. It offered the features we were looking for, including:
A 99.999% SLA
Limitless scale
Single-digit millisecond latency
A built-in monitoring system
Multi-region replication
Geo-distribution, which allows for seamless replication of data across regions and reduces latency
On-demand scaling of compute resources and storage, which adjusts to user traffic and allows our system to grow and scale as needed
Seamless integration with our general architecture; we use Google Cloud services for many other parts of our system, including the APIs that interact with these databases
A NoSQL database that doesn’t require relational semantics, as the datasets we’re migrating are indexed on a single primary key in our applications
Making the move
We targeted three of our major, self-managed datasets to migrate. The larger two were organized in a sharded database architecture. The first thing we did for migration was prepare the new Bigtable database. We iterated over a schema design process and conducted a thorough performance analysis of Bigtable to ensure an uninterrupted user experience during and after the migration. After that, we made minor adjustments to our application code so that it could seamlessly integrate and interact with Bigtable. Finally, we implemented a robust post-migration disaster recovery process to mitigate any potential risks.
During the actual migration, we enabled our applications to start a “dual writes” phase. This involved concurrently writing new link data to both our existing MySQL and the new Bigtable tables. Once data started writing to our Bigtable instance, we ran our migration scripts. We used a Go script to walk each of the existing MySQL datasets and insert each row into Bigtable. This enabled us to clean up outdated information and backfill older records with newer field data.
Cleaning up clutter along the way
In the process of migration, we were actually able to free up a huge amount of storage. Because of the elimination of an early feature of the Bitly platform, we were able to exclude from the migration to Bigtable a little less than half of the total data stored in MySQL. Since we were creating a completely clean dataset, we had the opportunity simply to skip those unneeded rows during the migration.
Altogether, the migration process walked through 80 billion MySQL rows, which resulted in just over 40 billion records finding their new home in Bigtable. In the end, our starting point with Bigtable is a 26 TB dataset, not including replication. A set of concurrent Go scripts running in parallel on a handful of machines allowed us to complete this migration project in six days. (Go rarely disappoints.)
Write twice, cut once – validation before migration
Next up was the data validation and cutover period when we started returning data from Bigtable, but continued to write to MySQL as a precaution in case we needed to roll back at any point.
As we dove into the validation process, we compared the data between MySQL and Bigtable and noted any discrepancies whenever a link was clicked or created. After verifying that all our responses were stable, we proceeded with a gradual cutover process, rolling out in percentages until we reached 100% Bigtable for all writes and reads. After a comfortable run period, we'll turn off the dual writes completely and finally decommission our workhorse MySQL hosts to live on a farm upstate.
Google’s got Bitly’s back(ups)
Our data is our lifeline, and we're doing everything we can to ensure it's always protected. We put together a redundancy plan using both Bigtable backups as well as a process for keeping a copy of the data outside Bigtable for true disaster recovery.
The first line of defense involves a switchover to the backup Bigtable dataset in case we need it. Beyond that, we've implemented two more layers of defense to protect against instance failure, corrupted data, and any other data failure that would require a restore of one or more tables from backup.
For this process, we start by creating daily Bigtable backups of our tables that we store for a fixed number of days. Second, we execute a Dataflow job to export our data from Bigtable into Cloud Storage approximately every week. And, if the need arises, we can use Dataflow to import our data back from Cloud Storage into a new Bigtable table.
While running the Dataflow jobs to export from Bigtable to Cloud Storage, we’ve seen an impressive export speed of 7-8 million rows read per second on average and up to 15 million per second at times. All the while, our production reads and writes continued without disruption. When we tested the Cloud-Storage-to-Bigtable restore job, the write speed, expectedly, increased with instance scale — at the maximum node quota for our regions, we observed an average of just under 2 million rows per second written to our new table.
Short links for the long haul
As mentioned above, not only did Bigtable meet our technical requirements and operational needs, but we also chose Bigtable because it sets us up for future growth. Its ability to scale seamlessly over time while improving our system availability SLA was a major factor in our decision.
As we increase our scale by 5x, 10x, or more, it's imperative that our data backbone scales accordingly and that the SLAs we provide to customers stay stable or even add another coveted "9". We have big plans in the coming years and Bigtable will help us achieve them.
Interested in learning more? We found the following resources to be useful in our journey to Bigtable evaluation and ultimate adoption:
Evaluate Bigtable schema design for your relational database and application workloads
Understand how to increase availability and distribute data globally with Bigtable replication in any region combination of your choice
Learn more about Bigtable backups and importing/exporting data with Bigtable Dataflow templates
Bonus: If you’re interested in learning more of the nuts and bolts of how we migrated the data, I’ll be talking all about that very topic at GopherCon 2023 this September in San Diego!


