Building a Cloud Data Fusion pipeline to upload audit records generated by Cloud SQL for SQL Server to BigQuery
Alexander Kolomeets
Software Engineer
Introduction
Cloud SQL for SQL Server offers configurable auditing, capturing events like login attempts, DDLs, and DMLs. These events are stored locally on the instance for up to 7 days and can be preserved longer in GCS buckets.
Some customers want to access and analyze their Cloud SQL for SQL Server audit data in other systems, like BigQuery or Tableau. While a custom-built pipeline can achieve this, it introduces complexity and maintenance burdens. Constant investment is needed for support, monitoring, and ensuring no audit records are lost.
In this blog, we walk through the steps to build a flexible pipeline to output audit records to internal or external sinks with minimal coding.
Prerequisites
Cloud Data Fusion doesn't directly support private IP Cloud SQL for SQL Server instances. To connect to these, you'll need to set up a Cloud SQL Auth Proxy as a bridge between Cloud Data Fusion and your Cloud SQL for SQL Server instances. However, if your Cloud SQL for SQL Server instances have public IPs, you can connect directly without any extra configuration.
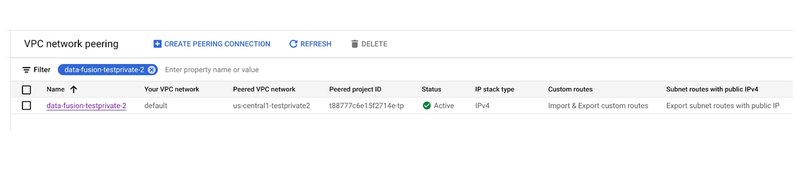
You would also need a private IP Cloud Data Fusion instance. To ensure connectivity between your Cloud SQL Auth Proxy and the Cloud Data Fusion instance, establish a network peering between their respective networks. The peered project ID can be found on the Cloud Data Fusion instance page:
Building the workflow
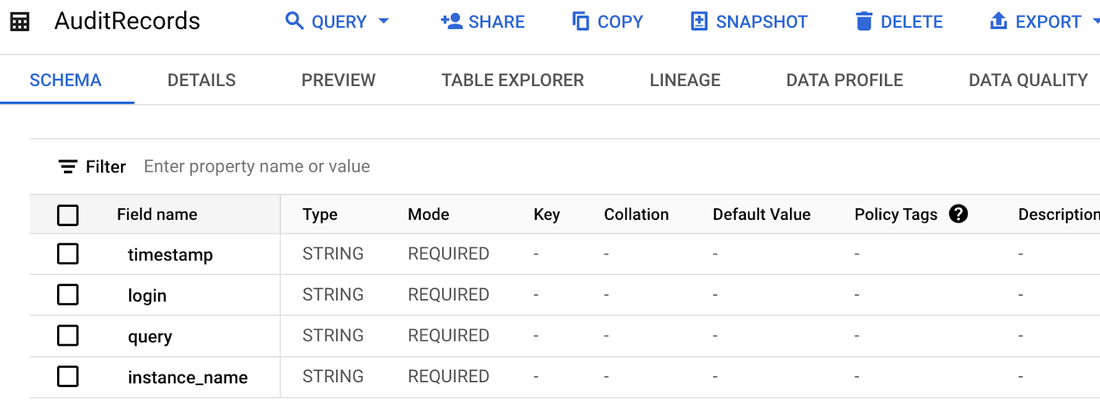
To begin, let's create the destination BigQuery table (we will store only a few fields, however, it’s possible to create a BigQuery table that stores all the available fields for a more comprehensive analysis):
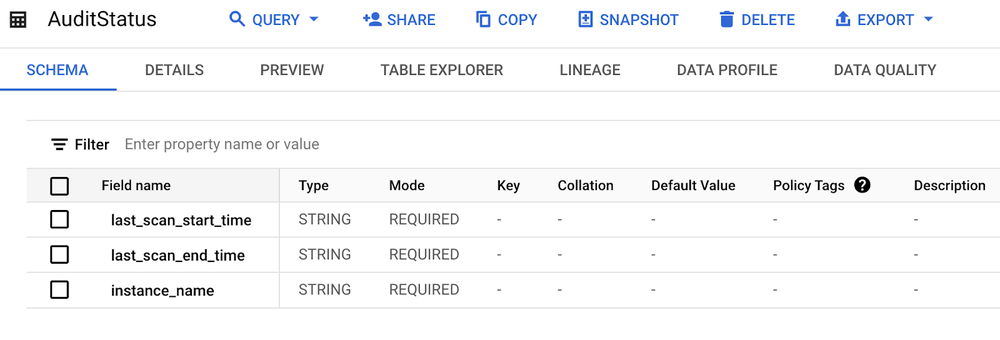
Additionally, we'll need a table to track the last processed audit records for each instance. This table can reside in Cloud SQL, BigQuery, or even as a file in a Google Cloud Storage bucket. For simplicity, we'll create this table in BigQuery. This is necessary because if audit record fetching fails (e.g., due to the Cloud SQL instance being unavailable), we need a way to prevent missed records and ensure retries on the next attempt. We'll use the string type for last_scan_start_time and last_scan_end_time fields, as the BigQuery argument captor doesn't support the datetime type.
Now let's create a Data Fusion pipeline:

Let's review all the added blocks in the Data Fusion pipeline.
1. Initialize audit status
This block queries BigQuery for the latest timestamp when audit records for this instance were uploaded. If no entry exists, it adds a default entry to retrieve all existing audit records.
MERGE dataset.AuditStatus AS target
USING (SELECT '${instance_name}' as instance_name) AS source
ON target.instance_name = source.instance_name
WHEN NOT MATCHED THEN
INSERT (last_scan_start_time, last_scan_end_time, instance_name)
VALUES ('2000-01-01 01:01:01', '2000-01-01 01:01:01', '${instance_name}')
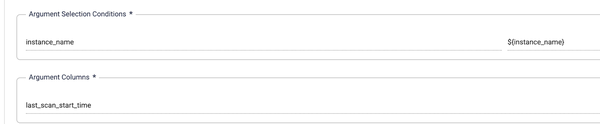
2. Set last scan time
This block sets the last_scan_start_time variable, with the value chosen conditionally based on the instance name.
3. Read audit records
We'll pass in the parameters ${ip} and ${port}. How these are determined will be explained in the next section.

We'll use this query to fetch new audit records from the instance, starting from the last processing time. Note that the query includes three additional parameters:
-
${last_scan_start_time} is set by the previous step.
-
${logicalStartTime} is automatically provided by Data Fusion.
-
${instance_name} will be explained in the next section.
SELECT event_time, server_principal_name, statement,' ${instance_name}' AS instance_name FROM msdb.dbo.gcloudsql_fn_get_audit_file('/var/opt/mssql/audit/*', NULL, NULL)
WHERE CONVERT(datetime2, '${logicalStartTime(yyyy-MM-dd HH:mm:ss)}', 20) >= event_time AND CONVERT(datetime2, '${last_scan_start_time}', 20) < event_time
4. Convert audit records
This optional block converts field names and types between the source and sink. This step can be skipped if the names and types already match.

5. Write audit records
This block writes the audit records to the destination BigQuery table. Since the fields were converted in the previous step, no additional configuration besides the destination table is needed.
6. Update last scan time
This final block updates the last scan time to prevent reprocessing audit records from the previous run. It also records the end time, primarily for tracking performance.
MERGE dataset.AuditStatus AS target
USING (SELECT '${instance_name}' as instance_name) AS source
ON target.instance_name = source.instance_name
WHEN MATCHED THEN
UPDATE SET last_scan_start_time = '${logicalStartTime(yyyy-MM-dd HH:mm:ss)}', last_scan_end_time = CAST(CURRENT_DATETIME() AS STRING)
Scheduling the workflow
Now you can start this workflow using gcloud, for example, from a cron job.:
WORKFLOW_NAME="AuditPipeline"
CDAP_ENDPOINT=`gcloud beta data-fusion instances describe --location <<DATA_FUSION_INSTANCE_LOCATION>> --format="value(apiEndpoint)" <<DATA_FUSTION_INSTANCE_NAME>>`
PIPELINE_URL="${CDAP_ENDPOINT}/v3/namespaces/default/apps/${WORKFLOW_NAME}/workflows/DataPipelineWorkflow/start"
AUTH_TOKEN=$(gcloud auth print-access-token)
curl -X POST \
-H "Authorization: Bearer ${AUTH_TOKEN}" \
-H "Content-Type: application/json" \
"${PIPELINE_URL}"
However, we will demonstrate a different approach using Cloud Scheduler, a fully managed, enterprise-grade cron job scheduler.
First, we'll create a Cloud Function to do the following:
-
Enumerate Cloud SQL instances within a project
-
Identify SQL Server instances with auditing enabled
-
Trigger the previously created Data Fusion pipeline for each eligible instance, passing the instance name and IP address as parameters
Please ensure the service account used to trigger the Cloud Function has permissions to access both Cloud SQL and Cloud Data Fusion instances.
import functions_framework
import requests
import json
# This function retrieves the access token needed to list Cloud SQL for SQL Server instances and trigger the created pipeline.
def get_access_token():
METADATA_URL = 'http://metadata.google.internal/computeMetadata/v1/'
METADATA_HEADERS = {'Metadata-Flavor':'Google'}
SERVICE_ACCOUNT = 'default'
url = '{}instance/service-accounts/{}/token'.format(METADATA_URL, SERVICE_ACCOUNT)
r = requests.get(url, headers=METADATA_HEADERS)
access_token = r.json()['access_token']
return access_token
# This function retrieves the Cloud SQL Proxy Auth address and IP. For simplicity, it assumes there's only one Proxy Auth instance. The port is calculated as 1433 plus the last octet of the target Cloud SQL for SQL Server instance's IP address.
def get_proxy_address_and_port(ip):
PROXY_ADDRESS = '10.128.0.5'
PROXY_BASE_PORT = 1433
port = int(ip.split('.')[-1]) + PROXY_BASE_PORT
return (PROXY_ADDRESS, port)
# This is the cloud function's entry point.
@functions_framework.http
def process_audit_http(request):
token = get_access_token()
WORKFLOW_NAME = "AuditPipeline"
# See the beginning of the section to learn how to determine this value.
CDAP_ENDPOINT = "<<YOUR_CDAP_ENDPOINT>>"
PIPELINE_URL = "{}/v3/namespaces/default/apps/{}/workflows/DataPipelineWorkflow/start".format(CDAP_ENDPOINT, WORKFLOW_NAME)
# List private IP Cloud SQL for SQL Server instances with auditing enabled.
r = requests.get("https://sqladmin.googleapis.com/v1/projects/<<PROJECT_NAME>>/instances?filter=settings.sqlServerAuditConfig.bucket:\"gs://<<BUCKET_NAME>>\"%20settings.ipConfiguration.privateNetwork:projects/<<PROJECT_NAME>>/global/networks/default", headers={"Authorization":"Bearer {}".format(token)})
json_object = json.loads(r.text)
# Find the Cloud SQL Auth Proxy IP and address, then start the Data Fusion pipeline..
for item in json_object["items"]:
for ip in item["ipAddresses"]:
if ip["type"] == "PRIVATE":
proxy_and_port = get_proxy_address_and_port(ip["ipAddress"])
param = {"ip" : proxy_and_port[0], "port": proxy_and_port[1], "instance_name" : item["connectionName"]}
r = requests.post(PIPELINE_URL, json=param, headers={"Authorization":"Bearer {}".format(token)})
return "done"
Second, we create a Cloud Scheduler job that targets the previously created cloud function. Set the execution interval as needed — for example, the example below schedules it to run every 15 minutes.

The pipeline can be easily modified to process multiple instances simultaneously. This can be done within the Cloud Function or the pipeline itself, potentially improving processing speed.
Running the workflow
Now let's create a Cloud SQL for SQL Server instance, enable auditing, and set up a simple audit rule:
CREATE SERVER AUDIT ServerAudit1 TO FILE (FILEPATH ='/var/opt/mssql/audit', MAXSIZE=2MB)
CREATE SERVER AUDIT SPECIFICATION ServerAuditSpec1 FOR SERVER AUDIT ServerAudit1 ADD (DATABASE_CHANGE_GROUP) WITH (STATE = ON)
ALTER SERVER AUDIT ServerAudit1 WITH (STATE = ON)
Then create two databases, like these:
CREATE DATABASE db1
CREATE DATABASE db2
Now, either wait for the next scheduled Cloud Scheduler run or trigger it manually. Once it runs, check the two BigQuery tables created earlier. The AuditRecords table should contain two 'create database' event:
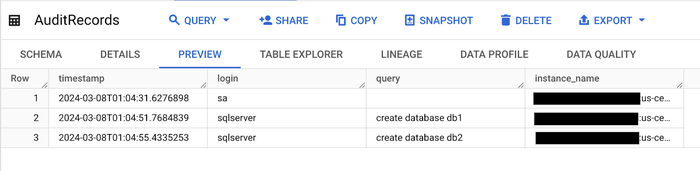
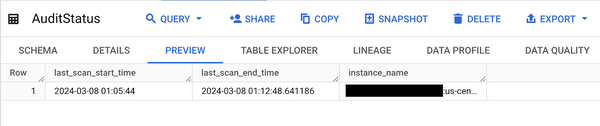
The AuditStatus table should show the last execution time as follows:
Now, let's drop one of the databases we created earlier. For example:
DROP DATABASE db1
Now, either wait for the next scheduled Cloud Scheduler run or trigger it manually. Afterward, check the AuditRecords table should now contain one additional event:
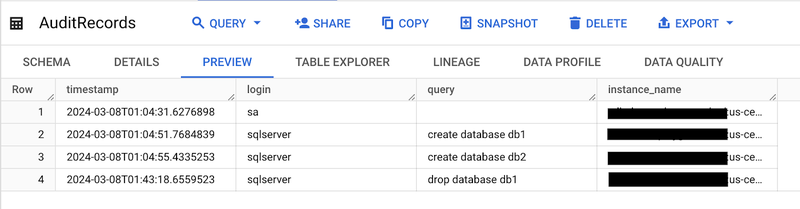
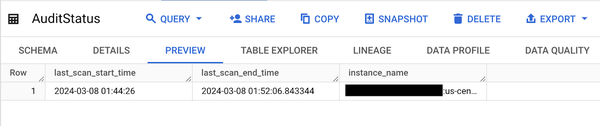
The AuditStatus table should also reflect the updated last execution time.
What’s next
Cloud Data Fusion offers robust notification features. You can configure these to send emails when pipelines fail, among other options. For detailed instructions on setting this up, refer to the guide here: https://cloud.google.com/data-fusion/docs/how-to/create-alerts.
You can also set up alerts in BigQuery to monitor specific conditions. See the following guide for instructions: https://cloud.google.com/bigquery/docs/scheduling-queries.

