Run data science workloads without creating more data silos
Antonio Scaramuzzino
Senior Product Manager
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialFor organizations, it is important to build a data lake solution that offers flexible governance and the ability to break data silos while maintaining a simple and manageable data infrastructure that does not require multiple copies of the same data. This is particularly true for organizations trying to empower multiple data science teams to run workloads like demand forecasting or anomaly detection on the data lake.
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits. For example, many companies have matrix structures, with specific teams responsible for some geographic regions while other teams are responsible for global coverage but only for their limited functional areas. This leads to data duplication and the creation of new data silos.
Managing distributed data at scale is incredibly complex. Distributed teams need to be able to own their data without creating silos, duplication, and inconsistencies. Dataplex allows organizations to scale their governance and introduce access policies that enable teams to operate on the portion of the data that is relevant to them.
Google Cloud can support your data lake modernization journey no matter where you are with people, processes, and technology. BigLake allows Google customers to unify their data warehouses and data lakes. Dataproc empowers distributed data science teams in complex organizations to run workloads in Apache Spark and other engines directly on the data lake while respecting policies and access rules.
This blog will show how Dataproc, Dataplex, and BigLake can empower data teams in a complex organizational setting, following the example of a global consumer goods company that has finance teams organized geographically. At the same time, other functions, such as marketing, are global.
Organizations are complex, but your data architecture doesn’t need to be
Our global consumer goods company has centralized their data in a data lake, and access policies ensure that each of their regional finance team has access only to the data that pertains to the appropriate location. While having access to global data, the marketing team does not have access to sensitive financial information stored in specific columns.
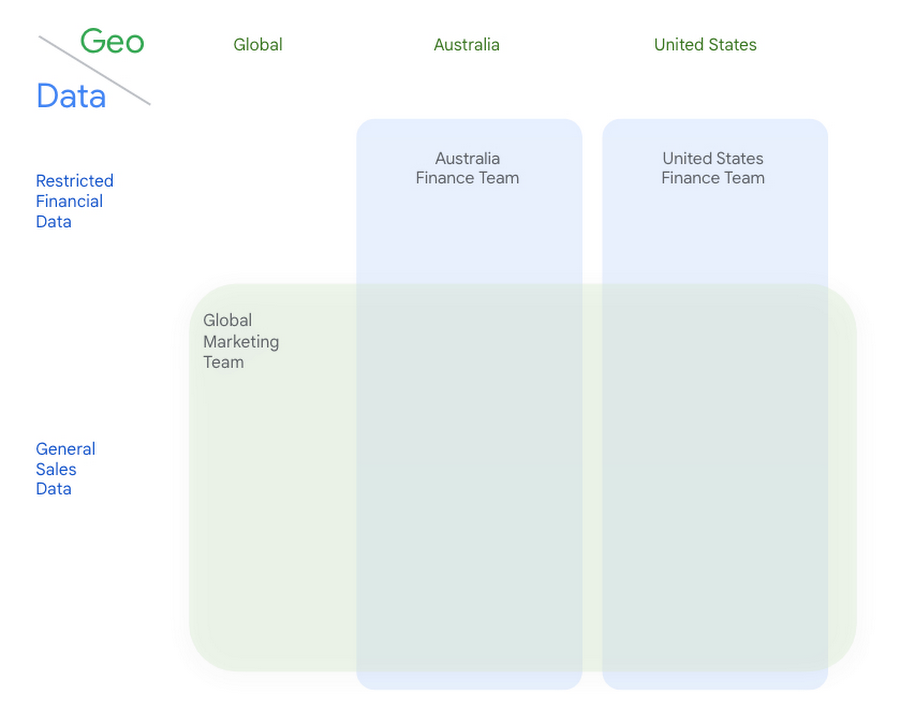
Dataproc with personal authentication enables these distributed teams to run data science and data engineering workloads on a centralized BigLake architecture with governance and policies defined in Dataplex.
BigLake creates a unified storage layer for all of the data and extends the BigQuery security model to file-based data in several different formats on Google Cloud and even on other clouds. Thanks to Dataproc, you can process this data in open-source engines such as Apache Spark and others.
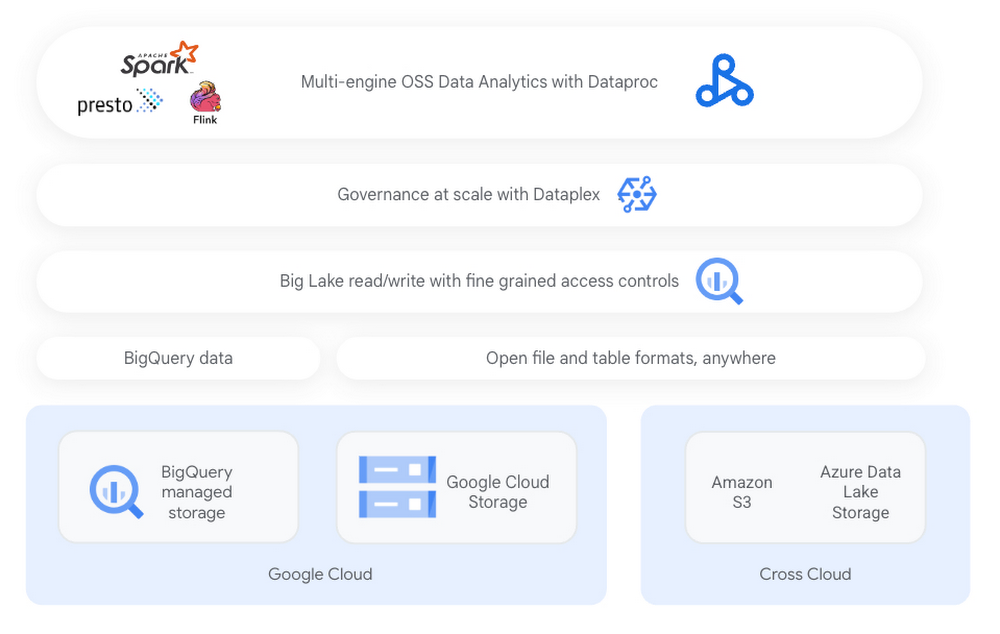
In this example, our global consumer goods company has a centralized file-based repository of sales data for each product. Thanks to BigLake, this company can map these files in their data lake to tables, apply row and column level security and, with Dataplex, manage data governance at scale. For the sake of simplicity, let’s create a BigLake table based on a file stored in Cloud Storage containing global ice cream sales data.
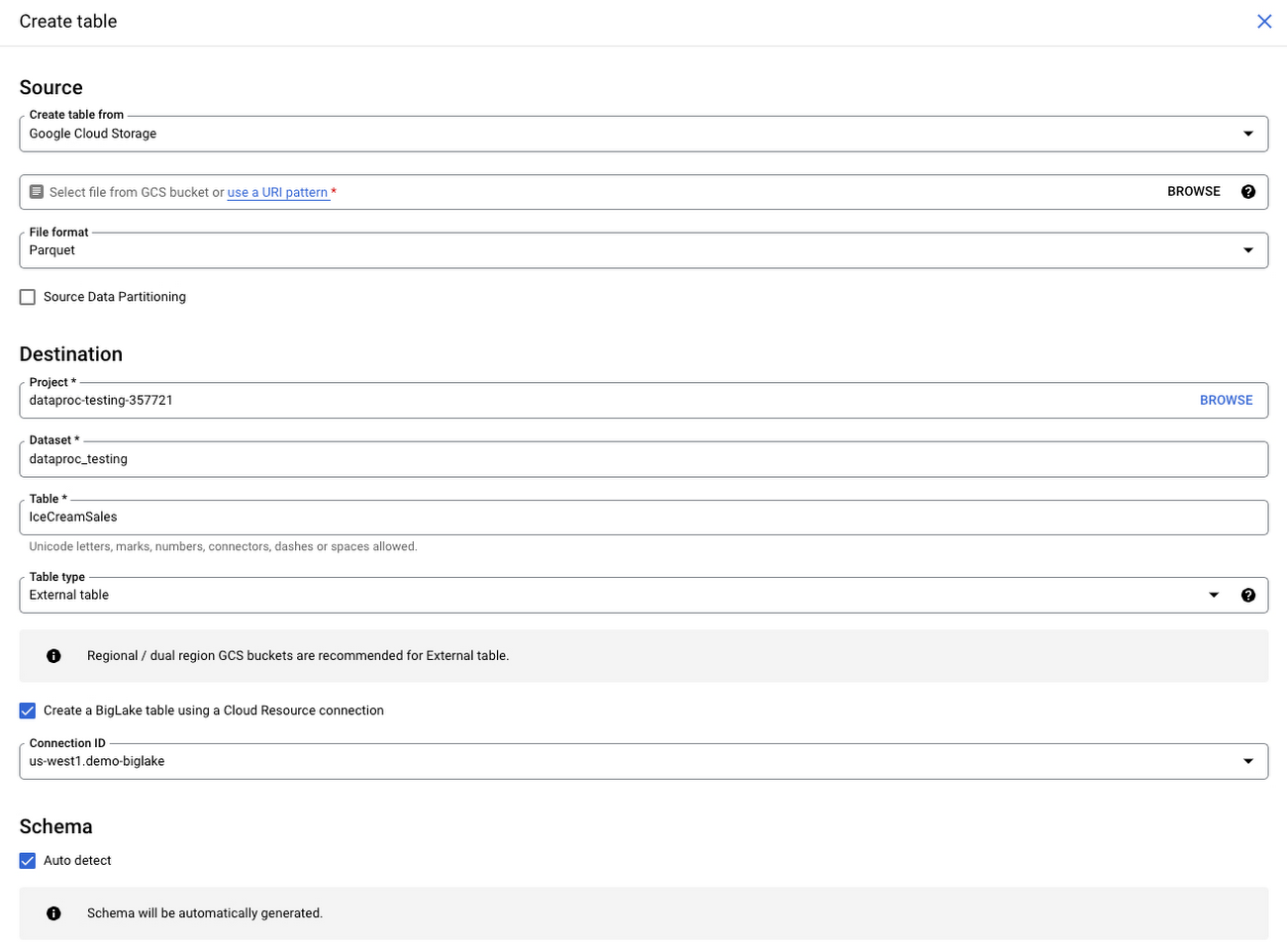
As seen in the architecture diagram above, BigLake is not creating a copy of the data in the BigQuery storage layer. Data remains in Cloud Storage, but BigLake allows us to map it to the BigQuery security model and apply governance through Dataplex.
To satisfy our business requirement to control access to the data on a geographical basis, we can leverage row-level access policies. Members of the US Finance team will only have access to US data, while members of the Australia Finance team will only have access to Australian data.
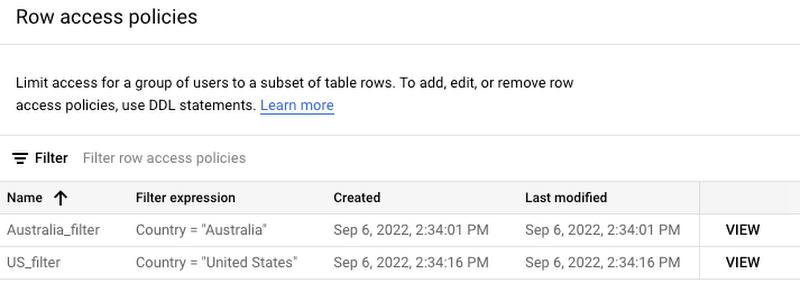
Dataplex allows us to create policy tags to prevent access to specific columns. In this case, a policy tag called “Business Critical: Financial Data” is associated with discount and net revenue so that only finance teams can access this information.
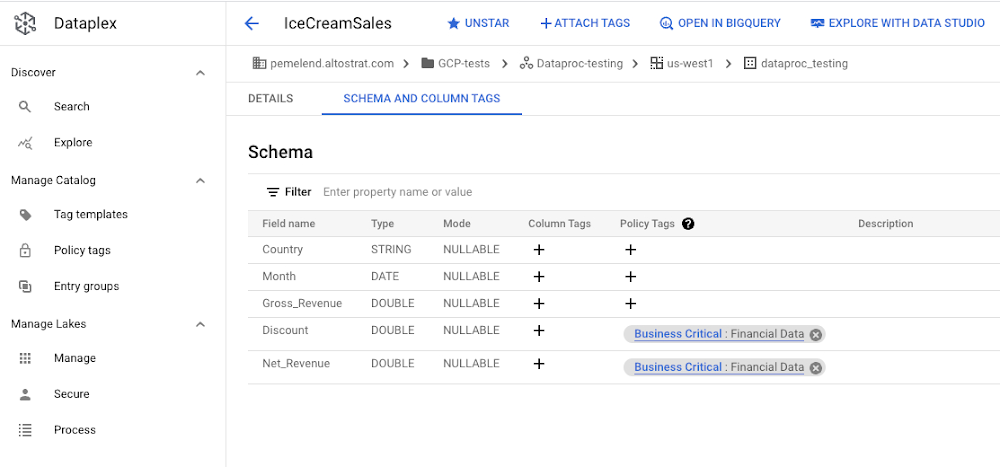
Data Science with Dataproc on BigLake data
Dataproc allows customers to run workloads in several open-source engines, including Apache Spark. We will see in the rest of this blog how users can leverage Dataproc personal authentication to run data science workloads on Jupyter notebooks directly on the data lake, leveraging the governance and security features provided by BigLake and Dataplex.
For example, a member of the Australia finance team can only access data in their geographical area based on the row-level access policies defined on the BigLake table. Below, you can see the output of a simple operation reading the data from a Jupyter notebook running Spark on a Dataproc cluster with personal authentication:
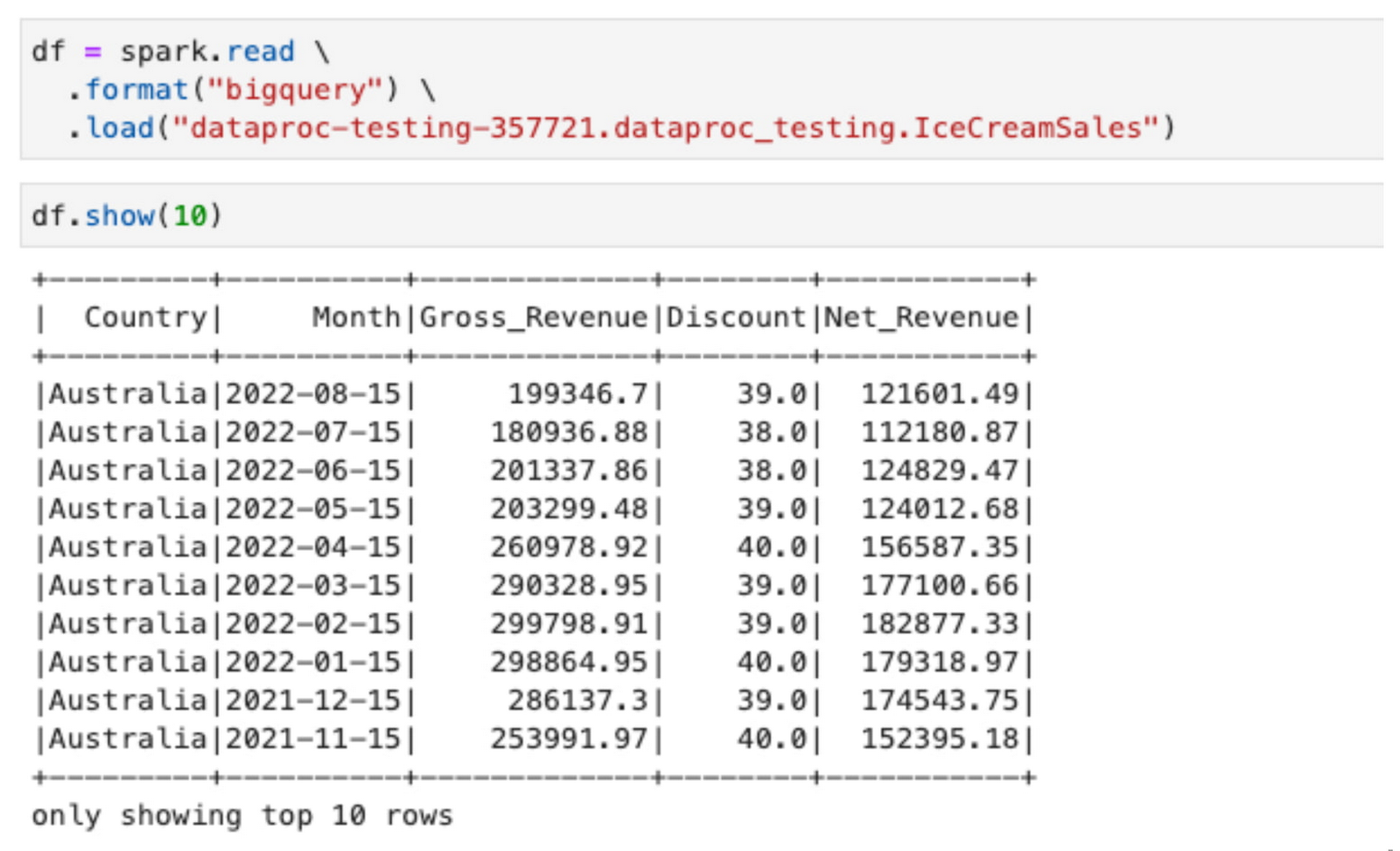
As a reminder, even if we use the BigQuery connector to access the data via Spark, the data itself is still in the original file format on Cloud Storage. BigLake is creating a layer of abstraction that allows Dataproc to access the data while respecting all the governance rules defined on the data lake.
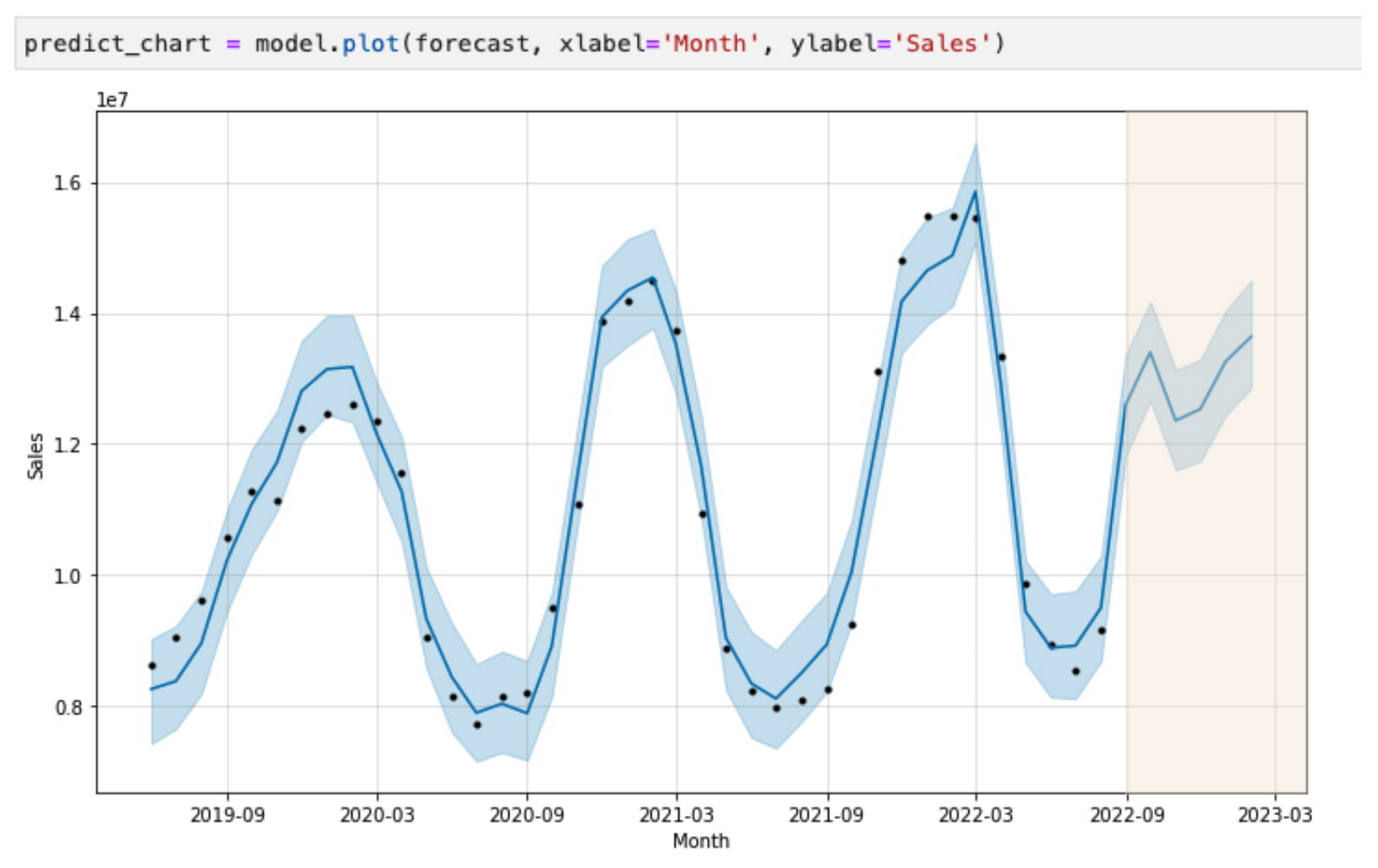
This member of the Australia finance team can leverage Spark to build a sales forecasting model, predicting sales of ice cream in the next six months:
Now, suppose a different user who is a member of the US Finance team tries to run a similar forecasting of ice cream sales based on the data she has access to, given the policies defined in BigLake and Dataplex. In that case, she will get very different results:
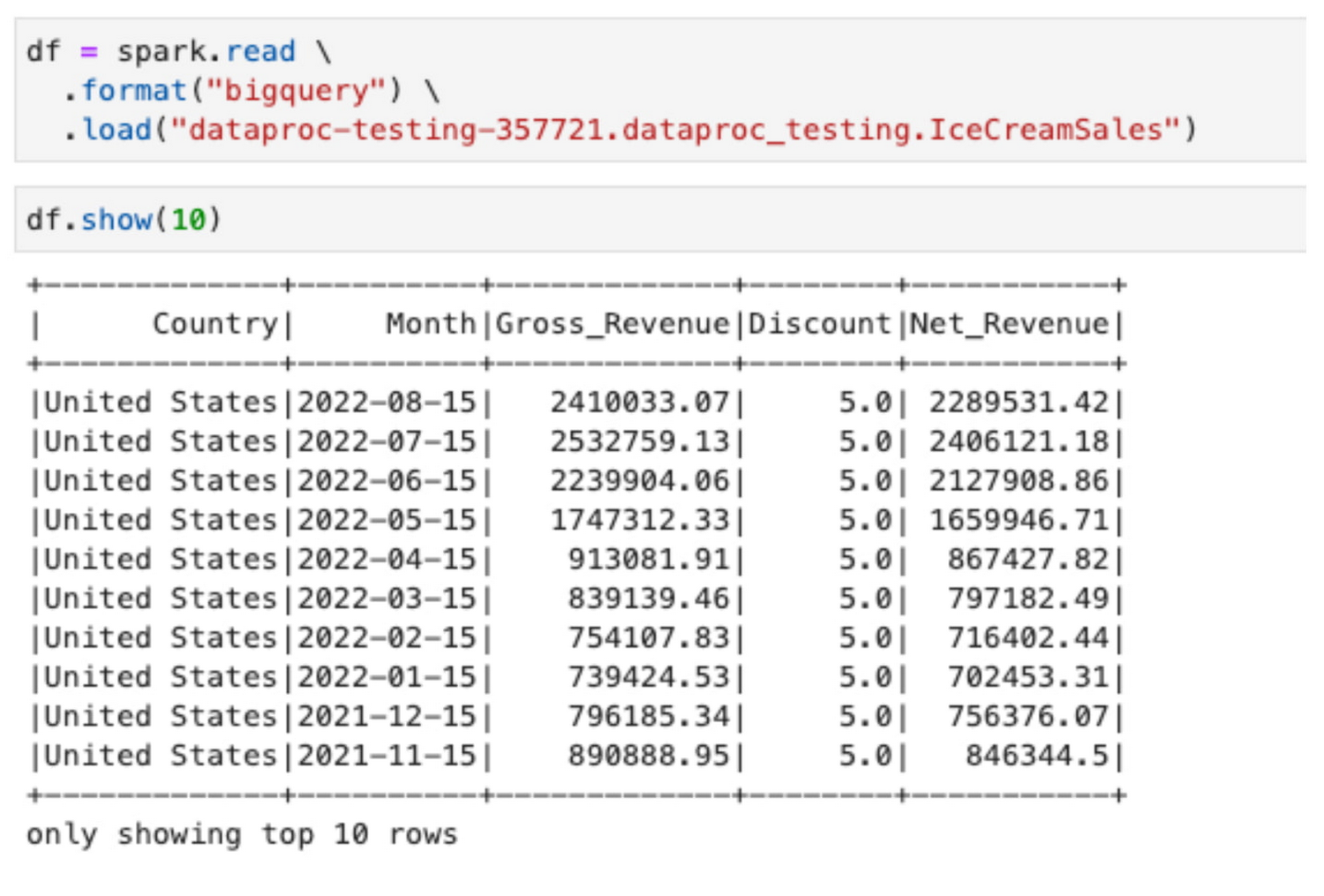
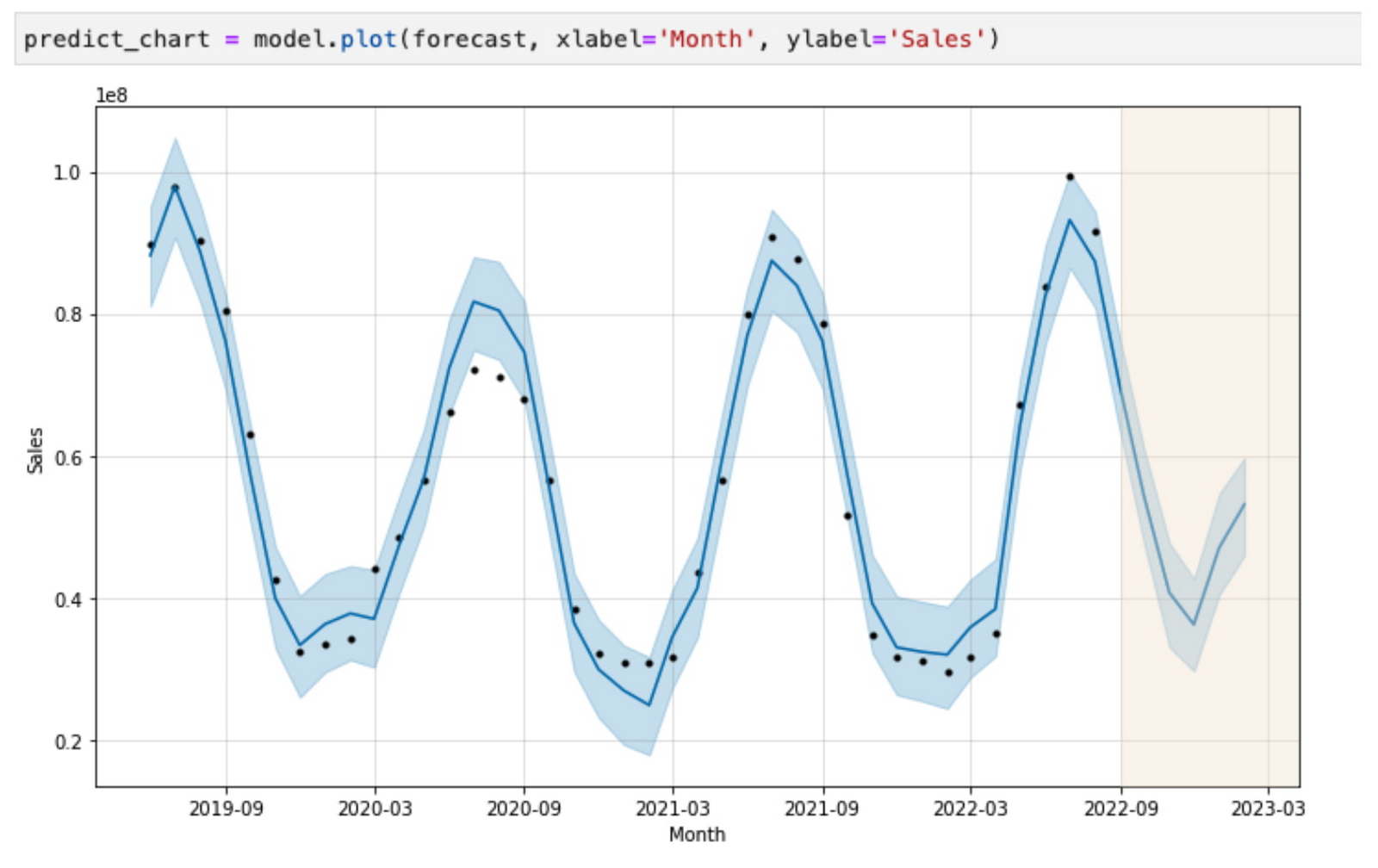
Sales of ice cream in the United States are expected to decline, while sales of ice cream in Australia will increase, all due to the different seasonal patterns in the Northern and Southern hemispheres. More importantly, each local team can independently operate on their regional data stored in a unified data lake, thanks to Dataplex on BigLake tables’ policies and Dataproc’s ability to run workloads with personal authentication.
Finally, users in the Marketing department will also be able to run Spark on Jupyter notebooks on Dataproc. Thanks to policy tags protecting financial data, they can only leverage the columns they have the right to access. For example, despite not having access to discount and revenue data, a marketing team member could leverage unit sales information to build a segmentation model using k-means clustering in Apache Spark on Dataproc.
Learn More
In this blog, we saw how Dataproc, BigLake, and Dataplex empower distributed data science teams with fine-grained access policies, governance, and the power of open-source data processing frameworks such as Apache Spark. To learn more about open-source data workloads on Google Cloud and governance at scale, please visit:


