New This Month in Data Analytics: Simple, Sophisticated, and Secure

Sudhir Hasbe
Sr. Director, Product Management
June is the month that holds the summer solstice, and some of us in the northern hemisphere get to enjoy the longest days of sunshine out of the entire year. We used all the hours we could in June to deliver a flurry of new features across BigQuery, Dataflow, Data Fusion, and more. Let’s take a look!
Simple, Sophisticated, and Secure
Usability is a key tenant of our data analytics development efforts. Our new user-friendly BigQuery improvements this month include:
- Flexible data type casting
- Formatting to change column descriptions
- GRANT/REVOKE access control commands using SQL
We hope this will delight data analysts, data scientists, DBAs, and SQL-enthusiasts who can find out more details in our blog here.
Beyond simplifying commands, we also recognize that it’s equally important to have more sophistication when dealing with transactions. That’s why we introduced multi-statement transactions in BigQuery.
As you probably know, BigQuery has long supported single-statement transactions through DML statements, such as INSERT, UPDATE, DELETE, MERGE and TRUNCATE, applied to one table per transaction. With multi-statement transactions, you can now use multiple SQL statements, including DML, spanning multiple tables in a single transaction.
This means that any data changes across multiple tables associated with all statements in a given transaction are committed atomically (all at once) if successful—or all rolled back atomically in the event of a failure.

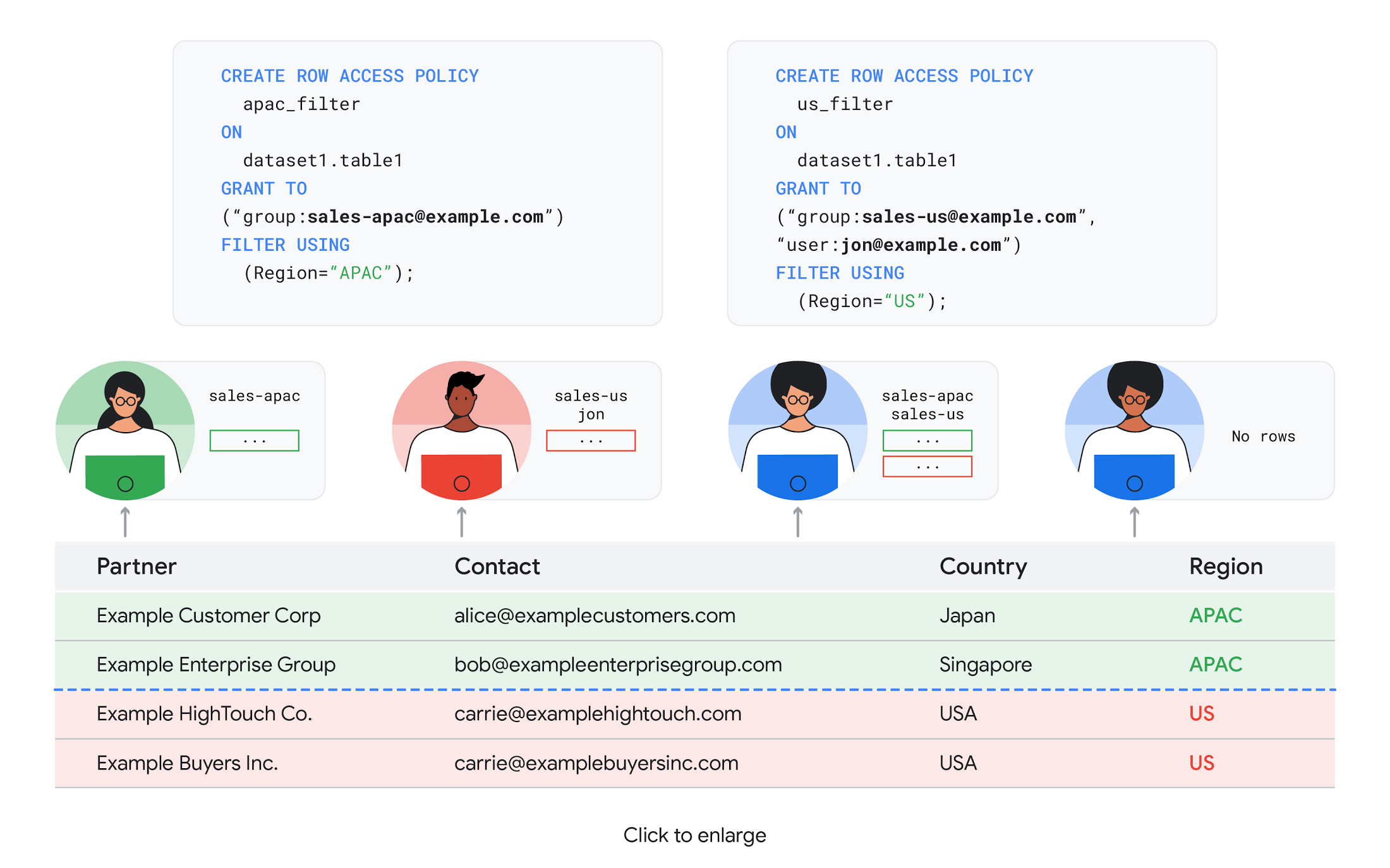
We also know that organizations need to control access to data, down to the granular level and that, with the complexity of data platforms increasing day by day, it's become even more critical to identify and monitor who has access to sensitive data.
To help address these needs, we announced the general availability of BigQuery row-level security. This capability gives customers a way to control access to subsets of data in the same table for different groups of users. Row-level security in BigQuery enables different user personas access to subsets of data in the same table and can easily be created, updated, and dropped using DDL statements. To learn more, check out the documentation and best practices.
Simple, Safe, and Smart
Beyond building a simpler, more sophisticated and more secure data platform for customers, our team has been focused on providing solutions powered by built-in intelligence. One of our core beliefs is that for machine learning to be adopted and useful at scale, it must be easy to use and deploy.
BigQuery ML, our embedded machine learning capabilities, have been adopted by 80% of our top customers around the globe and it has become a cornerstone of their data to value journey.
As part of our efforts, we announced the general availability of AutoML tables in BigQuery ML. This no-code solution lets customers automatically build and deploy state-of-the-art machine learning models on structured data. With easy integration with Vertex AI, AutoML in BQML makes it simple to achieve machine learning magic in the background. From preprocessing data to feature engineering and model tuning all the way to cross validation, AutoML will “automagically” select and ensemble models so everyone—even non-data scientists—can use it.
Want to take this feature for a test drive? Try it today on BigQuery’s NYC Taxi public dataset following the instructions in this blog!
Speaking of public datasets, we also introduced the availability of Google Trends data in BigQuery to enable customers to measure interest in a topic or search term across Google Search. This new dataset will soon be available in Analytics Hub and will be anonymized, indexed, normalized, and aggregated prior to publication.
Want to ensure your end-cap displays are relevant to your local audience? You can take signals from what people are looking for in your market area to inform what items to place. Want to understand what new features could be incorporated into an existing product based on what people are searching for? Terms that appear in these datasets could be an indicator of what you should be paying attention to.
All this data and technology can be put to use to deploy critical solutions to grow and protect your business. For example, it can be difficult to know how to define anomalies during detection. If you have labeled data with known anomalies, then you can choose from a variety of supervised machine learning model types that are already supported in BigQuery ML.
But what if you don't know what kind of anomaly to expect, and you don't have labeled data? Unlike typical predictive techniques that leverage supervised learning, organizations may need to be able to detect anomalies in the absence of labeled data.
That’s why, we were particularly excited to announce the public preview of new anomaly detection capabilities in BigQuery ML that leverage unsupervised machine learning to help you detect anomalies without needing labeled data.
Our team has been working with a large number of enterprises who leverage machine learning for better anomaly detection. In financial services for example, customers have used our technology to detect machine-learned anomalies in real-time foreign exchange data.
To make it easier for you to take advantage of their best practices, we teamed up with Kasna to develop sample code, architecture guidance, and a data synthesizer that generates data so you can test these innovations right away.
Simple, Scalable, and Speedy
Capturing, processing and analyzing data in motion has become an important component of our customer architecture choices. Along with batch processing, many of you need the flexibility to stream records into BigQuery so they can become available for query as they are written.
Our new BigQuery Storage Write API combines the functionality of streaming ingestion and batch loading into a single API. You can use it to stream records into BigQuery or even batch process an arbitrarily large number of records and commit them in a single atomic operation.
Flexible systems that can do batch and real-time in the same environment is in our DNA: Dataflow, our serverless, data processing service for streaming and batch data was built with flexibility in mind.
This principle applies not just to what Dataflow does but also how you can leverage it—whether you prefer using Dataflow SQL right from the BigQuery web UI, Vertex AI notebooks from the Dataflow interface, or the vast collection of pre-built templates to develop streaming pipelines.
Dataflow has been in the news quite a bit recently. You might have noted the recent introduction of Dataflow Prime, a new no-ops, auto-tuning functionality that optimizes resource utilization and further simplifies big data processing. You might have also read that Google Dataflow is a Leader in The 2021 Forrester Wave™: Streaming Analytics, giving Dataflow a score of 5 out of 5 across 12 different criteria.
We couldn’t be more excited about the support the community has provided to this platform. The scalability of Dataflow is unparalleled and as you set your company up for more scale, more speed, and “streaming that screams”, we suggest you take a look at what leaders at Sky, RVU or Palo Alto Networks have already accomplished.
If you’re new to Dataflow, you’re in for a treat: this past month, Priyanka Vergadia (AKA CloudGirl) released a great set of resources to get you started. Read her blog here and watch her introduction video below!

What is Google Cloud Dataflow?
Simple structure that sticks together
We thrive to be the partner of choice for your transformation journey, regardless where your data comes from and how you choose to unify your data stack.
Our partners at Tata Consultancy Services (TCS) recently released research that highlights the importance of a unifying digital fabric and how data integration services like Google Cloud Data Fusion can enable their clients to achieve this vision.
We also announced SAP Integration with Cloud Data Fusion, Google Cloud’s native data integration platform, to seamlessly move data out of SAP Business Suite, SAP ERP and S4/HANA. To date, we provide more than 50 pipelines in Cloud Data Fusion to rapidly onboard SAP data.
This past month, we introduced our SAP Accelerator for Order to Cash. This accelerator is a sample implementation of the SAP Table Batch Source feature in Cloud Data Fusion and will help you get started with your end-to-end order to cash process and analytics.
It includes sample Cloud Data Fusion pipelines that you can configure to connect to your SAP data source, perform transformations, store data in BigQuery, and set up analytics in Looker. It also comes with LookML dashboards which you can access on Github.
Countless great organizations have chosen to work with Google for their SAP data. In June, we wrote about ATB Financial’s journey and how the company uses data to better serve over 800,000 customers, save over CA$2.24 million in productivity, and realize more than CA$4 million in operating revenue through “D.E.E.P”, a data exposure enablement platform built around BigQuery.
Finally, if you are an application developer looking for a unified platform that brings together data from Firebase Crashlytics, Google Analytics, Cloud Firestore, and third party datasets, we have good news!
This past month, we released a unified analytics platform that combines Firebase, BigQuery, Google Looker and FiveTran to easily integrate disparate data sources, and infuse data into operational workflows for greater product development insights and increased customer experience. This resource comes with sample code, a reference guide and a great blog! We hope you enjoy it. See you all next month!

Creating a unified app analytics platform


