Best practices of orchestrating Notebooks on Serverless Spark
Kristin Kim
Cloud Technical Resident
Anu Venkataraman
Strategic Cloud Engineer
Data Scientists process data and run machine learning workflows via various distributed processing frameworks and interactive collaborative computing platforms, such as Project Jupyter and Apache Spark. Orchestrating all these workflows is usually done via Apache Airflow.
However, some challenges exist when running enterprise-grade Data Science and Machine Learning workloads in Public Cloud and at scale.
Performance: When it comes to an enterprise application, the size and scale of data and models are complex and tend to grow over time impacting the performance.
Scalability: The more complex an application gets, the more difficult it is to address capacity limits, bandwidth issues, and traffic spikes.
Infrastructure and Pricing: For typical enterprise ML deployment, planning and configuring appropriate cluster size, machine type, performance tuning, and maintenance costs are complex. There is a need for more flexible, cost-effective, and manageable solutions that let you focus on the core business logic of ML that matters the most to your business.
In Google Cloud, Data Engineers and Data Scientists can run Hadoop and Spark workloads on Dataproc and develop Jupyter-based Notebooks on Vertex AI Managed Notebooks.
With Serverless Spark, you can run any Spark batch workloads including Notebooks without provisioning and managing your own cluster. You can specify your workload parameters or rely on sensible defaults and autoscaling. The service will run the workload on managed compute infrastructure, autoscaling resources as needed.
With Vertex AI Managed notebook instances, you can develop interactive Notebooks. These instances are prepackaged with JupyterLab and have a preinstalled suite of deep learning packages, including support for the TensorFlow and PyTorch frameworks. Managed notebooks instances support GPU accelerators and the ability to sync with a source repository. Your managed notebooks instances are protected by Google Cloud authentication and authorization. Optionally, idle shutdown can be used to shut down your environment for cost savings while persisting all work and data to Cloud Storage.
Lastly, Cloud Composer can be used to orchestrate, schedule, and monitor these workflows.
In this blog, we’ll focus on running any Jupyter-based Notebooks as batch jobs on Serverless Spark.
Scenario: Notebooks lift and shift to Google Cloud
Typically the customers migrate and run their existing Notebooks from on-prem or other cloud providers to Serverless Spark. A Fortune 10 retailer migrated all of their data science workloads from on-premises to Serverless Spark and Vertex AI Managed Notebooks to run retail assortment analysis of 500M+ items daily.
Notebook migration is a two-step process:
1. Migrating Notebooks from legacy data lake and staging in Google Cloud Storage (GCS) bucket.
2. Orchestrating and deploying the staged Notebooks on Serverless Spark. We will primarily focus on JupyterLab-based Notebooks utilizing Spark for ELT/ETL in this blog.
The following diagram depicts the flow of Notebook operations:
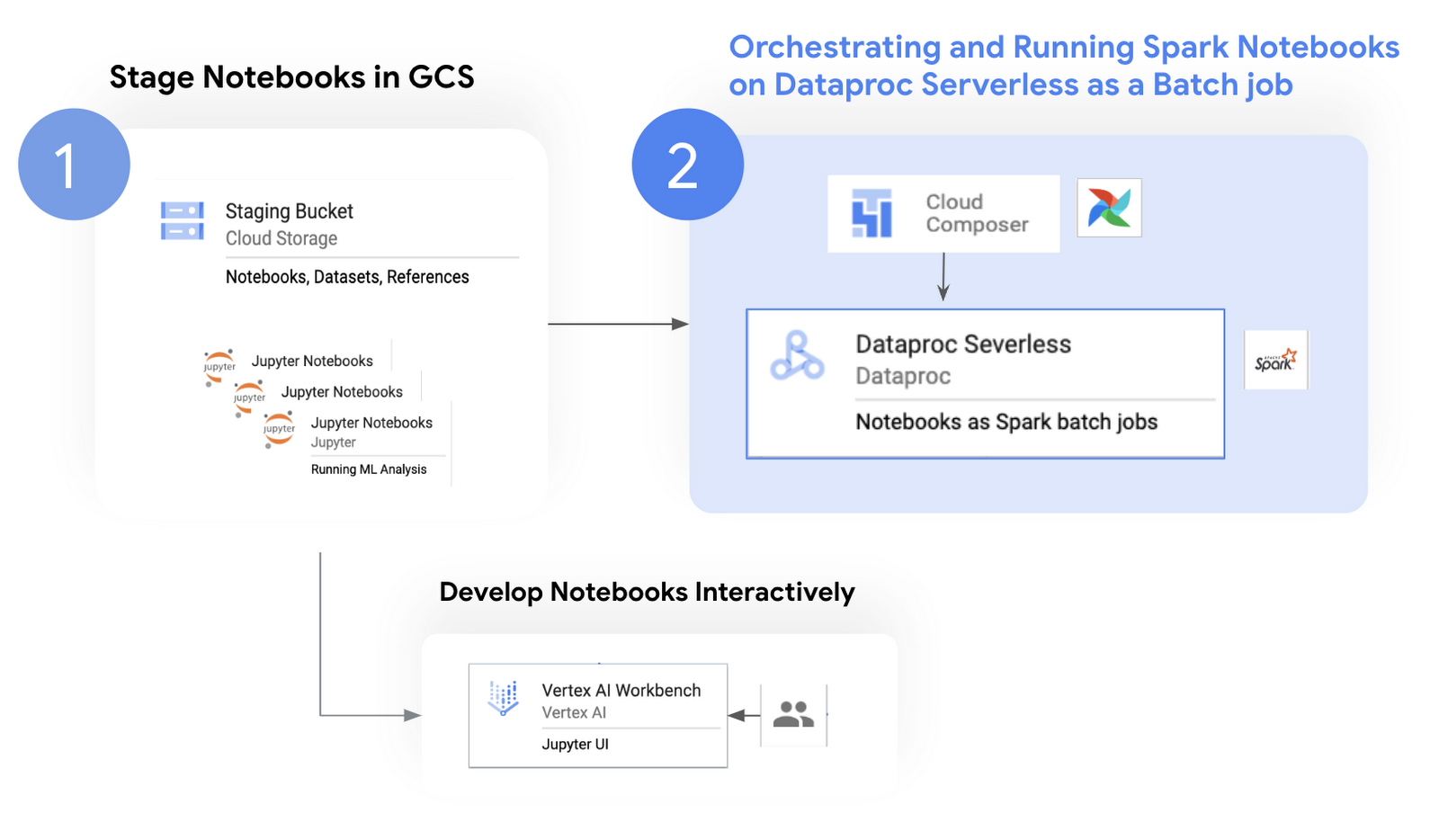
Cloud components
Here are some of the typical services used for Notebook development and orchestration:
Vertex AI Workbench comes with the Jupyter Notebook interface, enabling developers to analyze and visualize data interactively. It has integrated capabilities like BigQuery, GCS, and Git integration, all within the Notebook interface that lets users perform various tasks on the UI without leaving the Notebook. For example, when running unit tests, multiple developers can interactively and collaboratively invoke the entire testing workflows and share results and real-time feedback.
The following screenshot shows a sample Spark Notebook that we modified on Vertex AI workbench and orchestrated on Serverless Spark: (vehicle_analytics.ipynb)
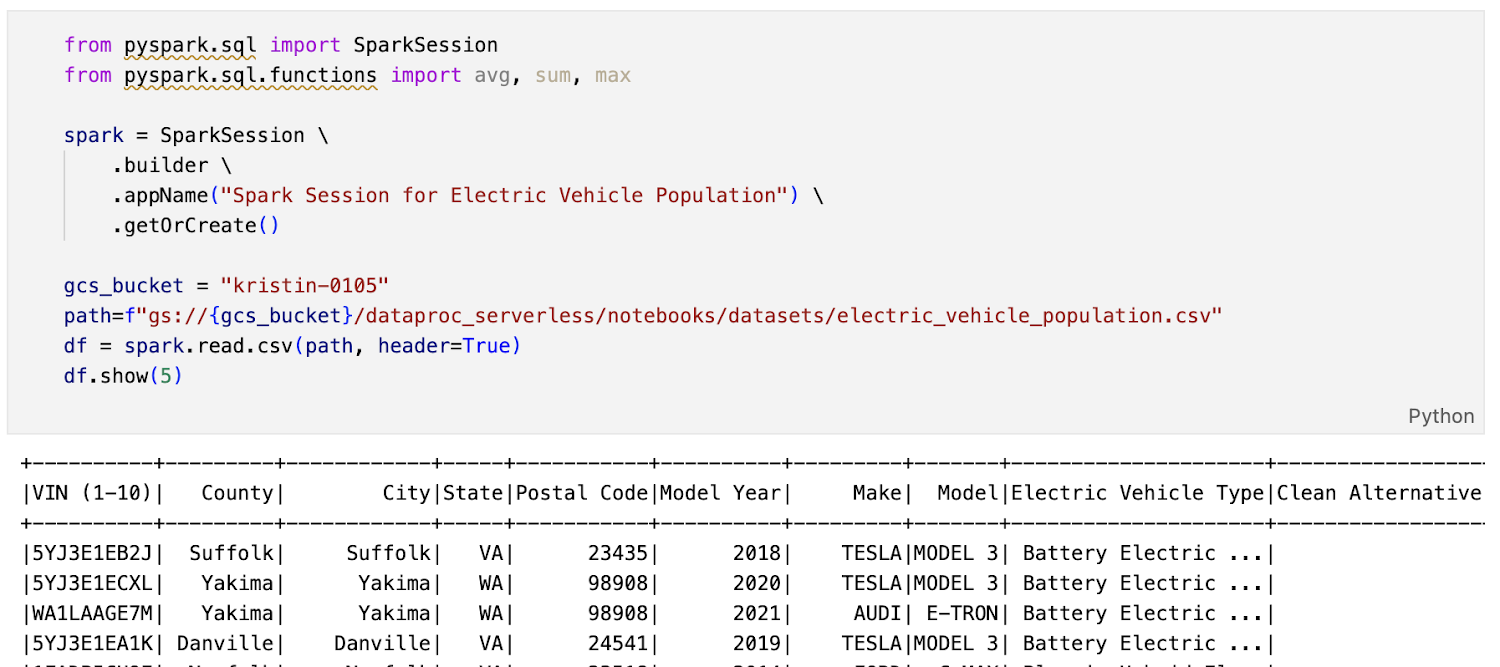
Serverless Spark uses its own Dynamic Resource Allocation to determine its resource requirements, including autoscaling.
Cloud Composer is a managed Airflow with Google Cloud Operators, sensors, and probes for orchestrating workloads. Its features ensure seamless orchestration of your Dataproc workloads as well:
Fully Managed: Cloud Composer can automate the entire process of creating, deleting, and managing Dataproc workflow which minimizes the chance of human error.
Integrability with other Google Cloud services: Cloud Composer offers built-in integration for a range of Google products, from BigQuery, Dataflow, Dataproc, Cloud Storage, Pub/Sub, and more.
Scalability: Cloud Composer autoscaling uses the Scaling Factor Target metric to adjust the number of workers, responding to the demands of the scheduled tasks.
Best Practices of Running Notebooks on Serverless Spark
1. Orchestrating Spark Notebooks on Serverless Spark
Instead of manually creating Dataproc jobs from GUI or CLI, you can configure and orchestrate the operations with Google Cloud Dataproc Operators from the open-source Apache Airflow.
When writing Airflow DAGs, follow these best practices to optimize Cloud Composer process for optimal performance and scalability.
To orchestrate using Cloud Composer, use Dataproc Batch Operator:
DataprocCreateBatchOperator(): This operator runs your workloads on Serverless Spark.
https://cloud.google.com/composer/docs/composer-2/run-dataproc-workloads#custom-container
This Python script can be submitted to Serverless Spark using the DataprocCreateBatchOperator():
Figure 3. Cloud Composer DAG to submit a batch job to Serverless Spark
We suggest you leverage Papermill utility wrapped in a Python script to pass parameters, execute Notebooks and return output to another Notebook like below:
Figure 4. Wrapper vehicle_analytics_executor.py leverages papermill to execute the Notebooks
2. Installing dependencies and uploading files
If your Notebook requires additional Python packages, you can pass the requirements.txt file path when submitting the batch job to Serverless Spark. For our testing, we added pendulum==2.1.2 in the requirements.txt.
You can also add additional Python files, JARs or any other reference files that are in GCS when submitting to Serverless Spark as shown below:
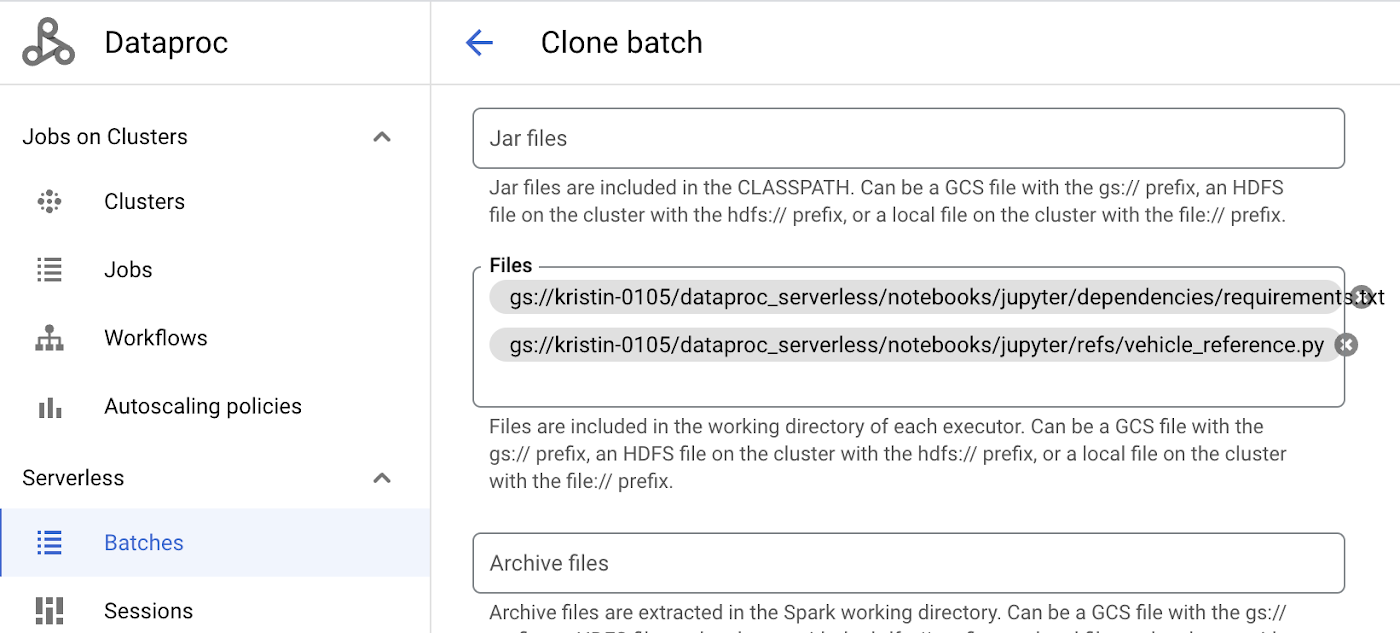
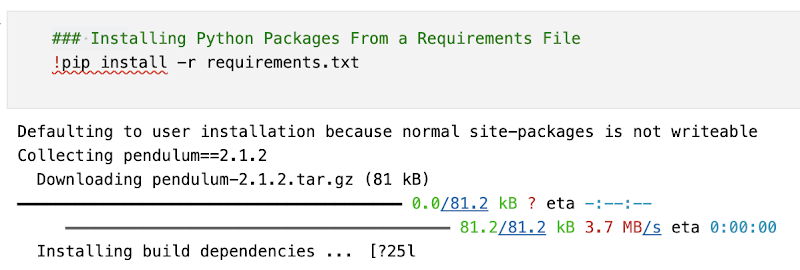
Figure 6. Installing the Python packages in requirement.txt on Notebook (vehicle_analytics.ipynb)

Figure 7. Successful installation of the listed Python packages on Notebook (vehicle_analytics.ipynb)

Figure 8. Successful %run command to execute the vehicel_reference.py on Notebook (vehicle_analytics.ipynb)
3. Spark logging and monitoring using a Persistent History Server
Serverless Spark Batch sessions are ephemeral so any application logs will be lost when the application completes.
Persistent History Server (PHS) enables access to completed Spark application details for the jobs executed on different ephemeral clusters or Serverless Spark. It can list running and completed applications. The application event logs and the YARN container logs of the ephemeral clusters and Serverless Spark are collected in a GCS bucket. These log files are essential for monitoring and troubleshooting.
Here are the best practices for setting up a PHS:
https://cloud.google.com/blog/products/data-analytics/running-persistent-history-servers
4. Performance tuning
When you submit a Batch job to Serverless Spark, sensible Spark defaults and autoscaling is provided or enabled by default resulting in optimal performance by scaling executors as needed.
If you decide to tune the Spark config and scope based on the job, you can benchmark by customizing the number of executors, executor memory, executor cores and tweak spark.dynamicAllocation to control autoscaling. Please refer to the spark tuning tips.
5. Run multiple Notebooks concurrently
You can submit multiple Notebooks to Serverless Spark concurrently. You can run up to 200 concurrent batch jobs per minute per Google Cloud project per region. For every batch job, you can run with job-scoped Spark configurations for optimal performance.
Since each Notebook gets separate ephemeral clusters, the performance of one Notebook job does not impact the other Notebook jobs. Configure the PHS cluster when you submit a Spark batch workload to monitor the Spark event logs of all the jobs.
6. Source control & CI/CD
Notebooks are code, so be sure to maintain them in source control and manage their lifecycle via robust CI/CD processes. Google Cloud Source for version control and Cloud Build can be used for CI/CD (Continuous Integration/Continuous Delivery).
For source control, it’s common to have a prod (master), dev, and feature branch.
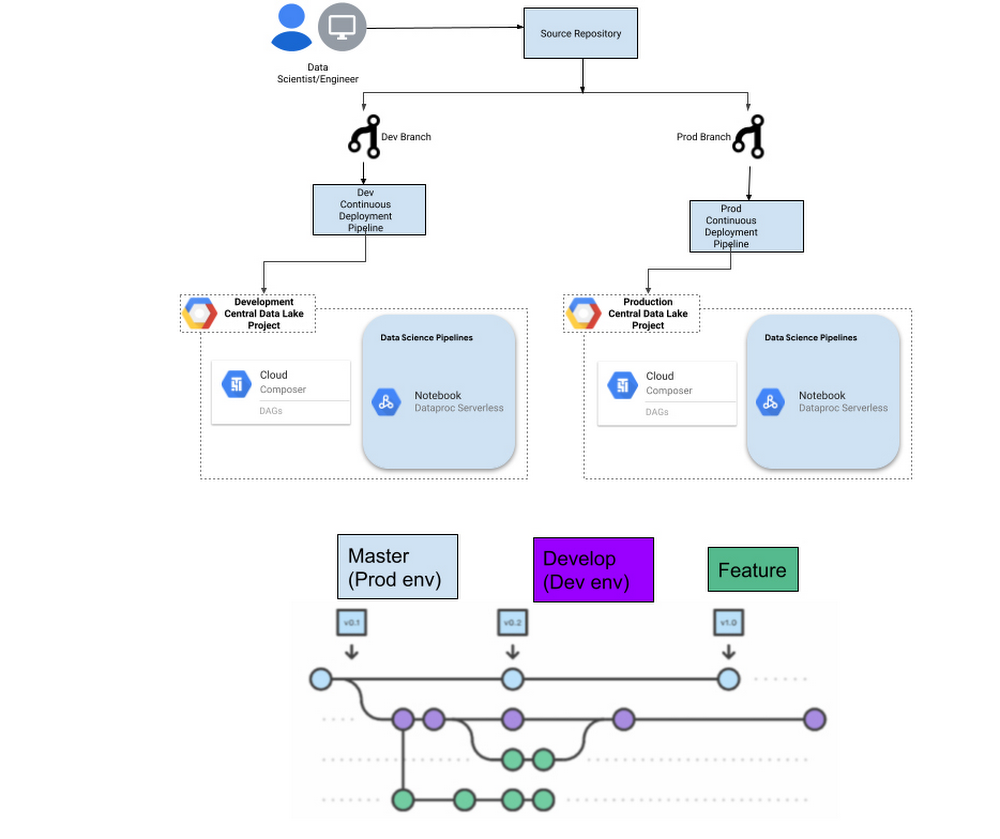
Follow CI best practices, include the build process as the first step in the CI/CD cycle to package the software in a clean environment.
Stage the artifacts required for the workflow like Notebooks, Python scripts, Cloud Composer DAGs, and the dependencies in a GCS bucket. Code repository branches could be attached to Google Cloud environments, it means for example when commits are made to the master branch, a CI/CD pipeline will trigger a set of pre configured tasks like read the latest code from repo, compile, run the automated unit test validations and deploy the code.
This helps maintain consistency between code repositories and what is deployed in Google Cloud projects.
We suggest keeping a dedicated bucket to stage the artifacts using CI/CD pipelines and a separate bucket for services like Cloud Composer and Dataproc to access the files so that it doesn’t impact the running Data Science workflows.
Next steps
If you are interested in running data science batch workloads on Serverless Spark, please see the following labs and resources to get started:
If you are interested in orchestrating Notebooks on Ephemeral Dataproc Cluster using Cloud Composer, check out this example.
Further resources
Explore pricing information on the services mentioned in this solution tutorial:
Be sure to stay up-to-date with the latest feature news by following product release notes:
Credits: Blake DuBois, Kate Ting, Oscar Pulido, Narasimha Sadineni


