Keeping your Cloud Dataflow pipelines safe with customer-managed encryption keys
Sergei Sokolenko
Cloud Dataflow Product Manager
At Google Cloud, we offer flexible, secure ways to stream, store and manage data. Cloud Dataflow is Google’s fully managed, serverless platform for streaming analytics. It optimizes resource usage and processing time by providing resource autoscaling and supporting batch processing. As your data travels inside Cloud Dataflow’s processing pipeline, it is protected in-flight and at rest with encryption technologies that use Google-managed encryption keys. We’re pleased to introduce a new option for specifying encryption keys, now available in beta, using the customer-managed encryption keys (CMEK) managed by Cloud Key Management Service (KMS).
Creating a pipeline protected with Cloud KMS keys
When you use Google Cloud, you get a secure environment to store data (in services such as BigQuery and Cloud Storage) and do batch and stream processing on that data, using Cloud Dataflow. If you just want to access data sources and sinks that are protected by Cloud KMS keys from within your Cloud Dataflow pipelines, this access is transparent to your Cloud Dataflow pipeline. You don't have to specify the Cloud KMS key of those sources and sinks, as long as you are not creating new objects in those data sinks (such as new tables in BigQuery).
However, if you want to protect your data end-to-end while it is being processed by your Cloud Dataflow pipeline, this new feature in Cloud Dataflow allows you to encrypt the state of the pipeline by specifying the following pipeline parameter:
What is the state of a pipeline? The pipeline state is the data that is stored by Cloud Dataflow in temporary storage, such as on Persistent Disks attached to your Cloud Dataflow workers or in Cloud Dataflow Shuffle. Cloud Dataflow is a highly parallel data processing service, and in order to optimize and speed up data processing, it will divide your data sets into small work items and process them in parallel. Some of these work items will have to be buffered on temporary storage before Cloud Dataflow processing workers can get to them. This is essentially what the pipeline state is.
In addition to using the command line and specifying the dataflowKmsKey parameter, you can also use the Cloud Console to create CMEK-protected Cloud Dataflow jobs. To create a Cloud Dataflow job protected with a Cloud KMS key, use one of the 25+ Google-provided Cloud Dataflow templates to create a sample job. Here’s how to do that:
1. Navigate to the “Create Job From Template” page
2. Next, select any Cloud Dataflow template that bridges a data source and a sink that already exist in your project. For example, you could use the Word Count template for this evaluation:
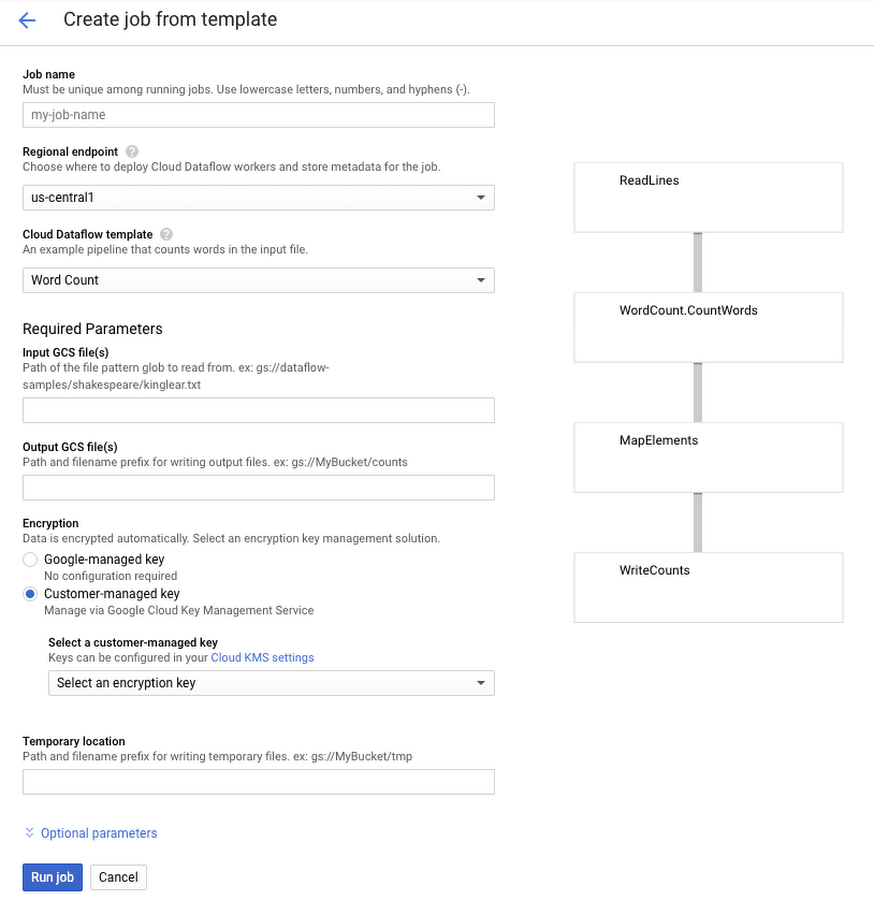
3. In the Input GCS file field, enter the URL of a sample file located at gs://dataflow-samples/shakespeare/kinglear.txt. In the Output GCS file field, enter the gs:// location of a temporary bucket that already exists in your project
4. In the section on the Create Job page titled Encryption, select "Customer-managed key."
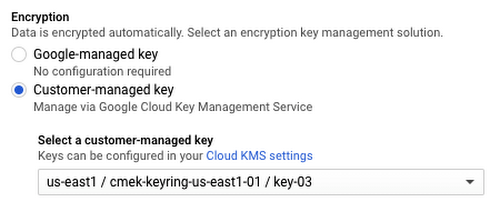
What is protected by the Cloud KMS key you specify?
As a general principle, Cloud Dataflow uses your Cloud KMS key to encrypt the data that you supply. The only exception to this rule are the data keys used in data-key-based operations such as windowing, grouping, and joining. The encryption of data keys is currently out of scope for CMEK encryption, so if these keys contain PII data, you should hash or otherwise transform the keys before they enter the Cloud Dataflow pipeline. In any case, the values of the key-value pairs are in scope for CMEK encryption.
Once you specify the Cloud KMS key, Cloud Dataflow will use it to protect the following pipeline state storage locations:
Persistent Disks attached to Cloud Dataflow workers and used for Persistent Disk-based shuffle and streaming state storage, and
Cloud Dataflow Shuffle state for batch pipelines.
What about the Cloud Storage buckets where Cloud Dataflow stores temporary BigQuery export/import data (specified by the --tempLocation parameter) or binary files containing pipeline code (--stagingLocation parameter)? While specifying the dataflowKmsKey parameter is not necessary to protect these locations, if you define a default Cloud KMS key for these buckets in the Cloud Storage UI, Cloud Dataflow will respect these settings.
Currently, the Cloud Dataflow streaming engine state cannot be protected by a Cloud KMS key and is encrypted by a Google-managed key. If you want all of your pipeline state to be protected by Cloud KMS keys, do not use the Cloud Dataflow streaming engine optional feature.
Tips and tricks for using Cloud KMS keys together with Cloud Dataflow
These details can be helpful to keep in mind as you’re using Cloud KMS keys with Cloud Dataflow.
Auditing: If you want to audit key usage by Cloud Dataflow, you can review the Cloud Audit Logs for log items related to key operations, such as encrypt and decrypt. These log items are tagged with the Cloud Dataflow Job ID, which allows you to track every time a specific Cloud KMS key is used for a Cloud Dataflow job.
Pricing: Each time the Cloud Dataflow service account uses your Cloud KMS key, that operation is billed at the rate of Cloud KMS key operations. Pricing information on Cloud KMS key operations is available at Cloud KMS pricing page.
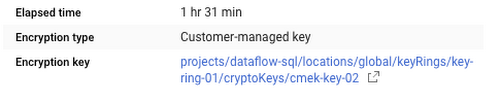
Verifying CMEK key usage: To verify which KMS key was used to protect the state of your pipeline, look at the Job Details page under the "Encryption key" section, or use the describe command in gcloud:
The Job Details page will show the location of the key.
To learn more about CMEK key usage in Cloud Dataflow, check out the documentation and try creating your first CMEK-protected job using the Cloud Dataflow templates.

