How to manage BigQuery flat-rate slots within a project
Navie Vurdien
Cloud Technical Resident
Debbie Chang
Cloud Technical Resident
If you’re part of a large enterprise using BigQuery, you’ll likely find yourself using BigQuery’s flat-rate pricing model, in which slots are purchased in monthly or yearly commitments as opposed to the default on-demand pricing. Enterprises favor flat-rate pricing because it gives your business predictable costs, and you’re not charged for the amount of data processed by each query.
In the flat-rate model, you pay for your own dedicated query processing resources, measured in slots, so you’ll likely want to manage how your business consumes these slots. You have the option to manage your BigQuery footprint by partitioning your purchased slots into reservations, and then assigning your Google Cloud Platform (GCP) projects to these reservations. Projects inside a reservation will have priority to use the reservation’s slots over other projects outside the reservation.
This flat-rate model presents a question we often hear from users: Can I allocate BigQuery slots at a more granular level than the GCP project level? These users generally have multiple applications inside the same GCP project, each with unique BigQuery resourcing needs, or just one application with varying resourcing needs (e.g. Apache Airflow running BigQuery jobs of varying priorities).
You should ideally separate your applications into their own projects, but what if you have multiple applications running on the same infrastructure (Hello, containers!)? We’ll describe here how to configure applications within the same project so their queries execute within separate projects with their own parent slot reservations.
Configuring applications for granular slot allocation
The diagram below describes a simple environment that accomplishes this. It uses three GCP projects. Two applications reside in Project_A: Application 1 to read from BigQuery and Application 2 to write to it. Project_B and Project_C exist solely to run queries executed by those applications.
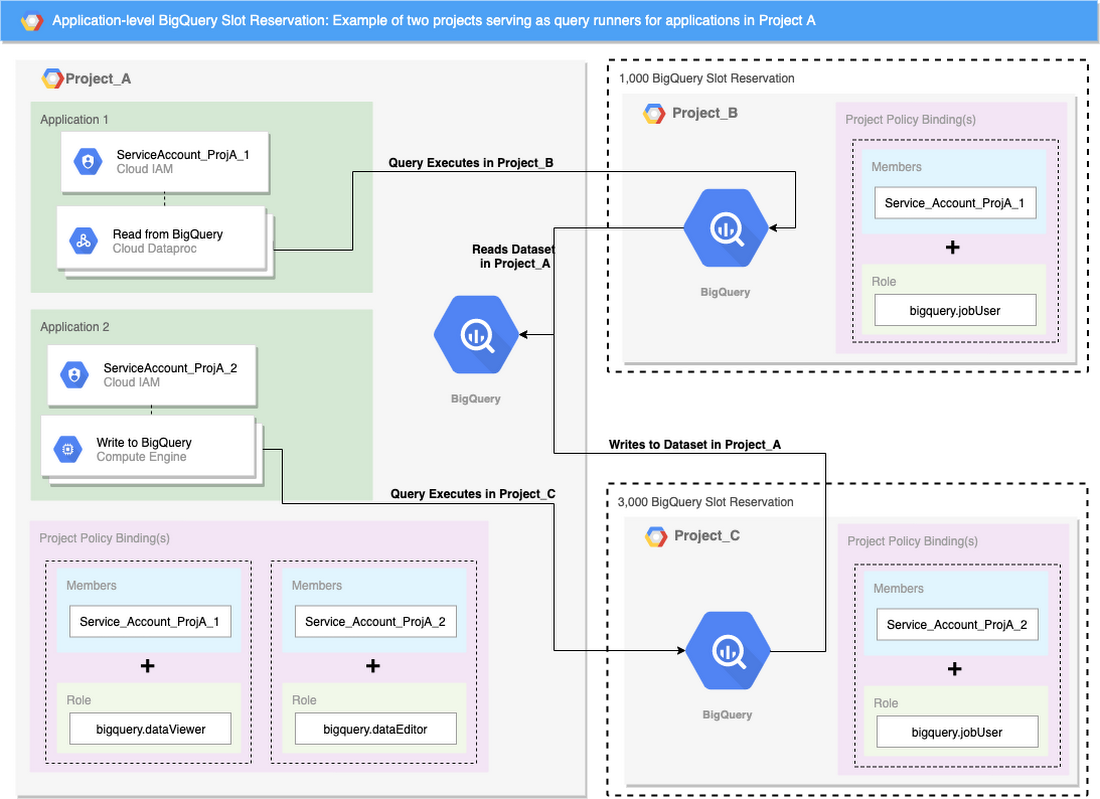
Example of two projects serving as query runners for applications in Project A
Here’s how this works in practice:
In Project A, create two service accounts (one for each application) and give minimal privileges to them, which can be seen in the bottom left of the diagram under “Project Policy Binding(s).” These two service accounts and their applications belong to Project A, but they are executing their queries in Projects B and C.
To enable this cross-project query execution:
Create Cloud Identity and Access Management (Cloud IAM) policy bindings in Projects B and C, which bind the service accounts to the bigquery.jobUser role.
Specify the project in which queries will execute by setting the projectId path parameter in the BigQuery jobs.query request. The following example demonstrates this by setting the project_id flag with the bq command-line tool:
Idle slots are seamlessly shared across BigQuery reservations and across GCP projects in the same reservation. This flexibility allows your projects to maintain high performance while preventing bottlenecking that may occur if slots run dry within a single project.
If Project B requires more slots than the 1,000 it is allocated, it can borrow any idle slots from the 3,000 slots allocated to Project C. This is useful when Project B needs to run several high-computation queries concurrently.
However, if at any moment Project C needs its allocated slots, it will take back any slots borrowed by Project B.
You can reconfigure applications in the same way as business needs change. For example, suppose you have a data engineering team that wants control over data storage and permissions for your data. You can produce this additional separation by creating a fourth project that houses BigQuery datasets. Application 1 uses Project B to execute read queries, Application 2 uses Project C to execute write queries, and Project D stores BigQuery datasets.
The architecture diagram below demonstrates this clear separation of storage and resource utilization, since the cost for data storage will be listed under Project D, and the cost for query execution will be listed under Project B and Project C.
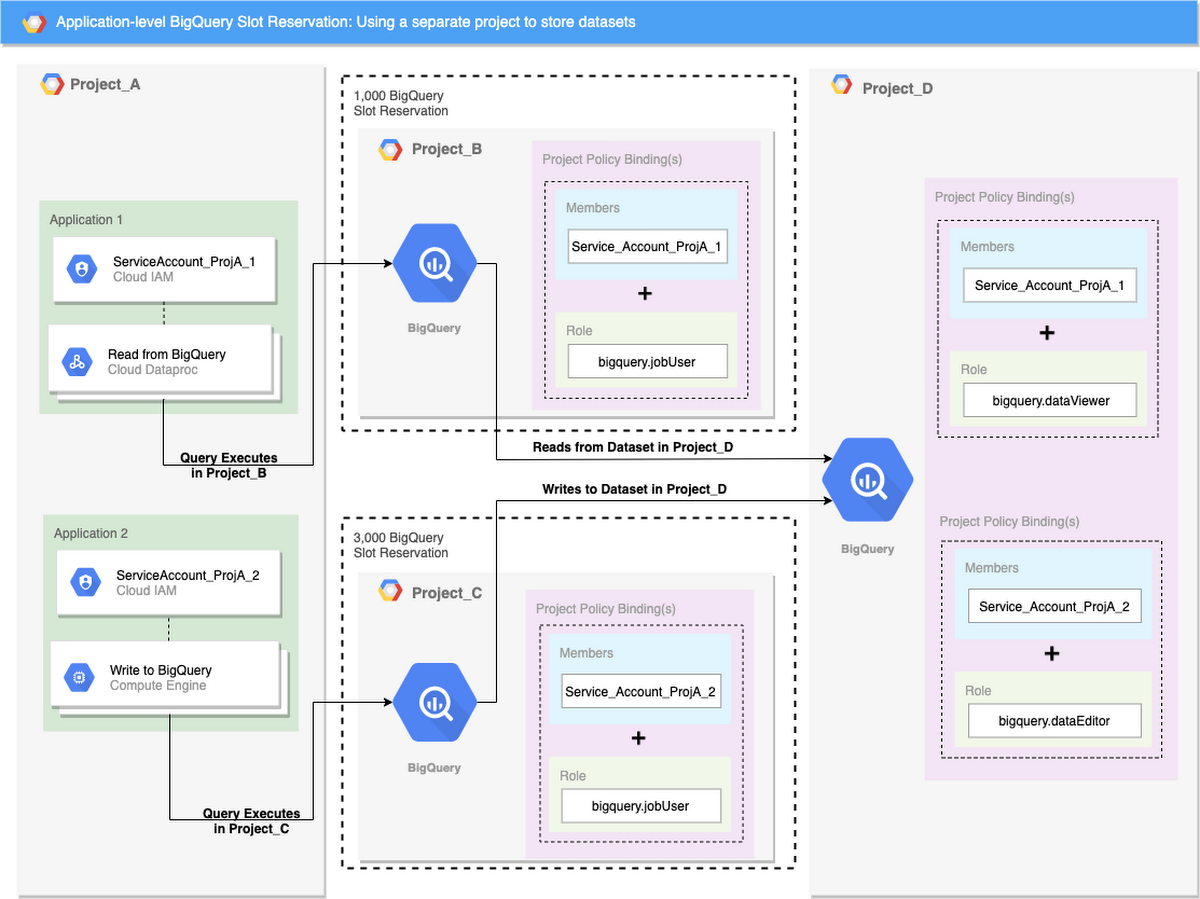
Example: using a separate project to store datasets
You may need some time to experiment and find the proper allocation of BigQuery slots for your applications as you transition from on-demand to flat-rate pricing model. The concepts and examples presented in this post intend to help you accelerate this process. Refer to our online documentation to learn more about optimizing BigQuery.


