How LiveRamp scales identity data management in the cloud
Sagar Batchu
Director of Engineering, , LiveRamp
Editor’s note: Today we’re hearing from Sagar Batchu, Director of Engineering at LiveRamp. He shares how Google Cloud helped LiveRamp modernize its data analytics infrastructure to simplify its operations, lower support and infrastructure costs and enable its customers to connect, control, and activate customer data safely and securely.
LiveRamp is a data connectivity platform that provides best in class identity resolution, activation and measurement for customer data so businesses can create a true customer 360 degree view. We run data engineering workloads at scale, often processing petabytes of customer data every day via LiveRamp Connect platform APIs.
As we integrated more internal and external APIs and the sophistication of our product offering grew, the complexity of our data pipelines increased. The status quo for building data pipelines very quickly became painful and cumbersome as these processes take time and knowledge of an increasingly complex data engineering stack. Pipelines became harder to maintain as the dependencies grew and the codebase became increasingly unruly.
Beginning last year, we set out to improve these processes and re-envision how we reduce time to value for data teams by thinking of our canonical ETL/LT analytics pipelines as a set of reusable components. We wanted teams to spend their time adding new features which encapsulate business value rather than spending time figuring out how to run workloads at scale on cloud infrastructure. This was even more pertinent with data science, data analyst and services teams whose daily wheelhouse was not the nitty gritty of deploying pipelines.
With all this in mind, we decided to start a data operations initiative, a concept popularised in the last few years, which aims to accelerate the time to value for data-oriented teams by allowing different personas in the data engineering lifecycle to focus on the “what” rather than the “how.”
We chose Google Cloud to execute on this initiative to speed up our transformation. Our architectural optimizations, coupled with Google Cloud’s platform capabilities simplified our operational model, reduced time to value, and greatly improved the portability of our data ecosystem for easy collaboration. Today, we have ten teams across LiveRamp running hundreds of workloads a day, and in the next quarter, we plan to scale to thousands.
Why LiveRamp Chose Google Cloud
Google Cloud provides all the necessary services in a serverless fashion to build complex data applications and run massive infrastructure. Google Cloud offers data analytics capabilities that help organizations like LiveRamp to easily capture, manage, process and visualize data at scale. Many of the Google Cloud data processing platforms also have open source roots making them extremely collaborative. One such platform is CDAP (Cask Data Application Platform), which Cloud Data Fusion is built on. We were drawn to this for the following reasons:
CDAP is inherently multicloud. Pipeline building blocks known as Plugins define individual units of work. They can be run through different provisioners which implement managed cloud runtimes.
The control plane is a set of microservices hosted on Kubernetes, whereas the data plane leverages the best of breed big data cloud products such as Dataproc.
It is built as a framework and is inherently extensible, and decoupled from the underlying architecture. We can extend it both at the system and user-level through “extensions” and “plugins” respectively. For example, we were able to add a system extension for LiveRamp specific authorisation and build a plugin that encompasses common LiveRamp identity operations.
It is open sourced, and there is a dedicated team at Google Cloud building and maintaining the core codebase as well as a growing suite of source, transform and sink connectors.
It aligns with our remote execution and non-data movement strategy. CDAP executes pipelines remotely and manages through a stream of metadata via public cloud APIs.
CDAP supports an SRE mindset by providing out of the box monitoring and observability tooling.
It has a rich set of APIs backed by scalable microservices to provide ETL as a Service to other teams.
Cloud Data Fusion, Google Cloud’s fully managed, native data integration platform is based on CDAP. We benefit from the managed security features of Data Fusion like IAM integration, customer manager encryption keys, role based access controls and data residency to ensure stricter governance requirements around data isolation.
How are teams using the Data Operations Platform?
Through this initiative, we have encouraged data science and engineering teams to focus on business logic and leave data integrations and infrastructure as separate concerns. A centralised team runs CDAP as a service, and custom plugins are hosted in a democratized plugin marketplace where any team can contribute their canonical operations.
Adoption of the platform was driven by one of our most common patterns of data pipelining: The need to resolve customer data using our Identity APIs. LiveRamp Identity APIs connect fragmented and inaccurate customer identity by providing a way to resolve PII to pseudonymous identifiers. This enables client brands to connect, control, and activate customer data safely and securely.
The reality of customer data is that it lives in a variety of formats, storage locations, and often needs bespoke cleanup. Before, technical services teams at LiveRamp had to develop expensive processes to manage these hygiene and validation processes even before the data was resolved to an identity. Over time, a combination of bash and python scripts and custom ETL pipelines became untenable.
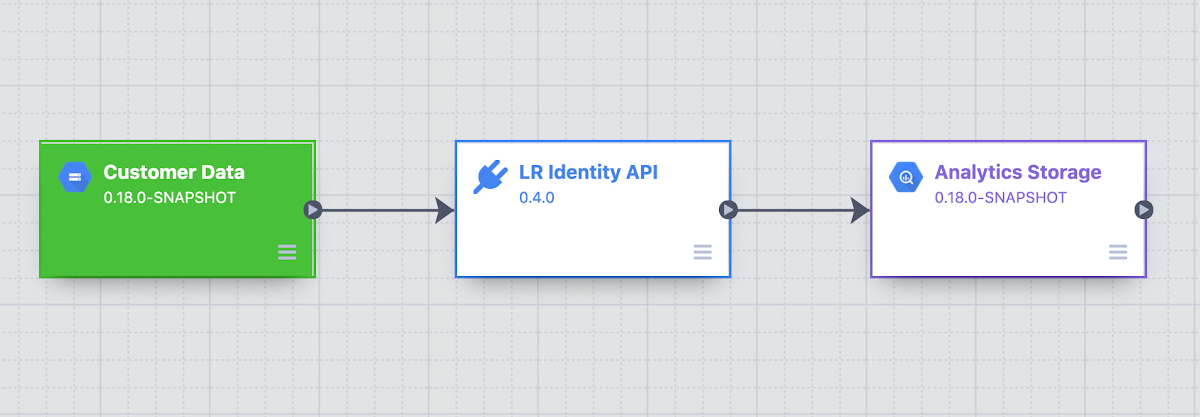
By implementing our most used Identity APIs, a series of CDAP plugins, our customers were able to operationalise their processes by logging into a Low Code user interface, select a source of data, run standard validation and hygiene steps, visually inspect using CDAP’s Wrangler interface for especially noisy cases, and channel data into our Identity API. As these workflows became validated, they have been established as standard CDAP pipelines that can now be parameterized and distributed on the internal marketplace. These technical services teams have not only reduced their time to value but have also enabled future teams to leverage their customer pipelines without worrying about the portability to other team’s infrastructures.
What’s Next ?
With critical customer use cases now powered by CDAP, we plan on scaling out usage of the platform to the next batch of teams. We plan on taking on more complex pipelines, cross-team workloads, and adding support for the ever growing LiveRamp platform API suite.
In addition to the Google Cloud community and the external community, we have a growing base of LiveRamp developers building out plugins on CDAP to support routine transforms and APIs. These are used by other teams who push the limits and provide feedback -- spinning a flywheel of collaboration between those who build and those who operate. Furthermore, teams internally can continue to use their other favorite data tools like BigQuery and Airflow as we continue to deeply integrate CDAP into our internal data engineering ecosystem.
Our data operations platform powered by CDAP is quickly becoming a center point for data teams - a place to ingest, hygiene, transform, and sink their data consistently.
We are excited by Google Cloud’s roadmap for CDAP and Data Fusion. Support for new execution engines, data sources and sinks, and new features like Datastream and Replication will mean LiveRamp teams can continue to trust that their applications will be able to interoperate with the ever evolving cloud data engineering ecosystem.



