Turn customer feedback into opportunities using generative AI in BigQuery DataFrames
Ashley Xu
Software Engineer, Google
Alicia Williams
Developer Advocate, Google Cloud
To operate a thriving business, it is important to have a deep understanding of your customers' needs and extract valuable insights from their feedback. However, the journey of extracting actionable information from customer feedback is a formidable task. Examining and categorizing feedback can help you discover your customers' core pain points with your products, but can become increasingly challenging and time-consuming as the volume of feedback multiplies.
Several new generative AI and ML capabilities in Google Cloud can help you build a scalable solution to this problem, enabling you to glean insights from your customer feedback and identify the product issues that are top-of-mind, even when that feedback is unstructured.
In this blog post, we'll walk through an example of building such a solution for transforming raw customer feedback into actionable intelligence.
Our solution will segment (or cluster) a large dataset of customer feedback and summarize the narratives associated with each logical segment. We'll demonstrate this solution using sample data from the CFPB Consumer Complaint Database, which is available as a BigQuery Public Dataset. This dataset is a collection of complaints about consumer financial products and services, and represents a varied collection of feedback in an unstructured form.
The core capabilities of Google Cloud that we will use to build this solution are:
- text-bison foundation model: a large language model that has been trained on a massive dataset of text and code. It can generate text, translate languages, write different kinds of creative content, and answer all kinds of questions. It is part of Generative AI on Vertex AI.
- textembedding-gecko model: a NLP technique that converts textual data into numerical vectors that can be processed by machine learning algorithms, especially large models. These vector representations are designed to capture the semantic meaning and context of the words they represent. It is also part of Generative AI on Vertex AI.
- BigQuery ML K-means model: a clustering model for data segmentation. K-means is an unsupervised learning technique, so model training doesn’t require labels or to split data for training or evaluation.
We'll be using BigQuery DataFrames to perform these ML and generative AI operations. BigQuery DataFrames is an open-source Python client that simplifies the interaction with BigQuery and Google Cloud by compiling popular Python APIs into scalable BigQuery SQL queries and API calls.
With BigQuery DataFrames, data scientists can move from data exploration to a production application by deploying their Python code as BigQuery programmable objects, while integrating with data engineering pipelines, BigQuery ML, Vertex AI, LLM models, and Google Cloud services. We’ll showcase the ML use cases here, and you can also check out more supported ML capabilities.
Building a feedback segmentation and summarization solution
If you want to follow along, you can make a copy of the notebook, Use BigQuery DataFrames to cluster and characterize complaints, which allows you to run this solution in Colab using your own Google Cloud project.
Load and prepare the data
In order to use BigQuery DataFrames, you'll need to import its pandas library and set the Google Cloud project and location for the BigQuery session that it will use.
Then you'll create a DataFrame that contains the full CFPB Consumer Complaint Database table using the read_gbq method.
To manipulate and transform the data, you can use bigframes.pandas on this DataFrame as you normally would, however calculations will happen in the BigQuery query engine instead of your local environment. There are 400+ pandas functions supported in BigQuery DataFrames. You can view the list in the documentation.
For the transformations in this solution, you will isolate the consumer_complaint_narrative column of the DataFrame, which includes the original complaint as unstructured text, while using the dropna() panda to drop any rows that contain NULL values for that field.
Let's take a look at snippets of the few rows of the resulting DataFrame.

Next, you will downsample your DataFrame (which currently contains more than 1M rows) to a size of 10,000 rows. Downsampling can be helpful for reducing training time and helping mitigate the impact of noisy or outlier data points.
Create text embeddings
When clustering unstructured text data, it's essential to convert the text into embeddings, or numerical vectors, before applying clustering models. Luckily, you can create these embeddings using the text-embedding-gecko model, available as the PaLM2TextEmbeddingGenerator, directly with BigQuery DataFrames.
The following code imports this model and uses it to create embeddings for each row of the DataFrame, resulting in a new DataFrame that contains both the embedding and the original unstructured text.
Train the k-means model
Now that you have the text embeddings representing the 10,000 complaints, you are ready to train the k-means model.
K-means clustering is a type of unsupervised machine learning algorithm that aims to partition a set of data points into a predefined number of clusters. This algorithm strives to organize data points into distinct clusters by minimizing the overall distance between data points and their respective cluster centers while maximizing the separation between clusters.
You can create a k-means model using the bigframes.ml package. The following code imports the k-means model, trains the model using the embeddings with a parameter of 10 clusters, and then uses the model to predict the cluster for each of the complaints in the DataFrame.
Let's take a look at the results. The DataFrame, clustered_result, now has an additional column that includes an ID from 1-10 (inclusive) indicating to which semantically similar group they belong.
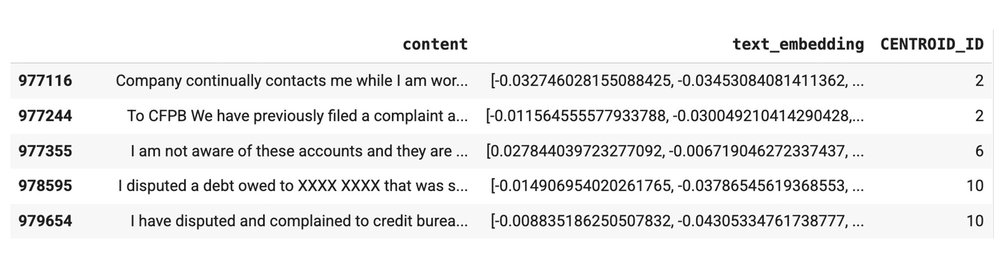
We decided to use 10 clusters in this solution, but there may be an opportunity to fine-tune this number. You can learn more about how to find the optimal number of clusters for a particular k-means model in this tutorial.
Prompt the LLM model
You now have the complaints clustered into ten different groupings. But what are the differences between the complaints in each cluster? You can ask a large language model, or LLM, to help describe these differences. Let's step through an example that uses the LLM to compare the complaints between two particular clusters.
The first step is to prepare the question, or prompt, for the LLM. In this case you'll collect five complaints each from cluster #1 and #2 as a list, and join them with a string of text asking the LLM to highlight the most obvious difference between the two lists.
The structure of the resulting prompt will look like the following:

Now that the prompt is ready, you will send that prompt to the text-bison foundation model using the PaLM2TextGenerator available in the bigframes.ml package.
Let's take a look at the response provided by the LLM model when we ran this solution.
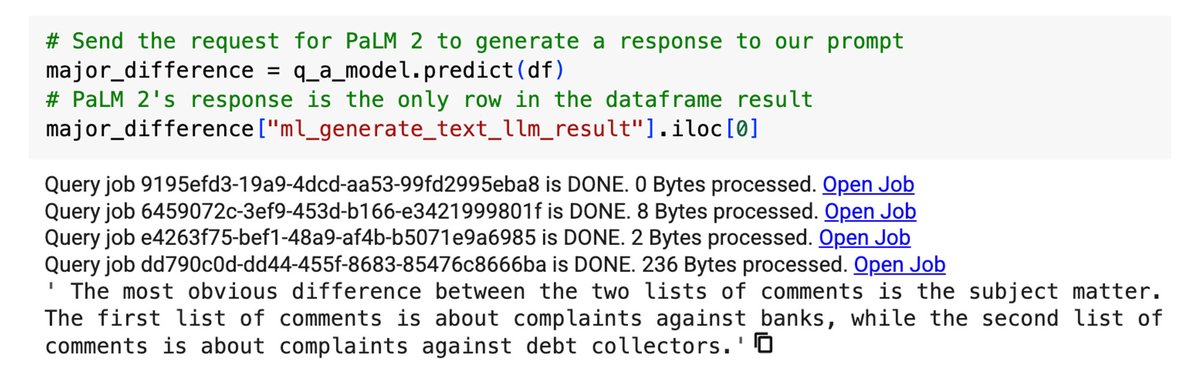
The LLM model was able to provide an insightful and concise evaluation of how the two clusters relate and differ to each other. You could extend this solution to provide insights and summaries for complaints in all clusters.
Next steps
And there you have it! By using BigQuery DataFrames, we were able to leverage the power of NLP (natural language processing) and machine learning to build a solution for understanding customer feedback.
We began by embedding the text into numerical vectors to capture the semantic meaning of the complaints. Then, we employed a k-means clustering algorithm to group similar complaints together based on their embedded representations. Finally, we utilized LLMs (large language models) to analyze each cluster and provide a summary of the complaints within each group. This approach enabled us to effectively identify common themes and patterns among the complaints, gaining valuable insights into the nature of the issues being raised.
For more details and to get started with BigQuery DataFrames, head to our quickstart documentation.

