A flexible way to deploy Apache Hive on Cloud Dataproc
Julien Phalip
Solutions Architect, Google Cloud
If you’re a current user of Apache Hive or Cloud Dataproc, you might consider trying out a new tutorial that shows how to use Apache Hive on Cloud Dataproc in an efficient and flexible way by storing Hive data in Cloud Storage and hosting the Hive metastore in a MySQL database on Cloud SQL. This separation between compute and storage resources offers some advantages:
Flexibility and agility: You can tailor cluster configurations for specific Hive workloads and scale each cluster independently up and down as needed.
Cost savings: You can spin up an ephemeral cluster when you need to run a Hive job and then delete it when the job completes. The resources that your jobs require are active only when they're being used, so you pay only for what you use. You can also use preemptible VMS for noncritical data processing or to create very large clusters at a lower total cost.
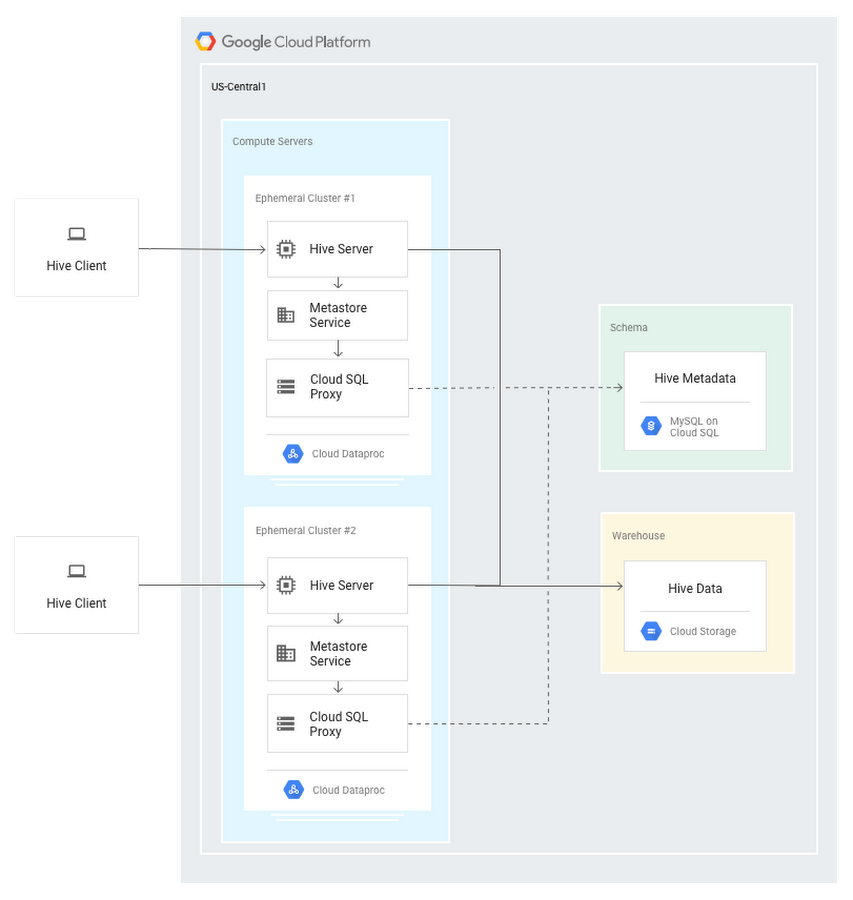
Hive is a popular open source data warehouse system built on Apache Hadoop. Hive offers a SQL-like query language called HiveQL, which is used to analyze large, structured datasets. The Hive metastore holds metadata about Hive tables, such as their schema and location. Where MySQL is commonly used as a backend for the Hive metastore, Cloud SQL makes it easy to set up, maintain, manage, and administer your relational databases on Google Cloud Platform (GCP).
Cloud Dataproc is a fast, easy-to-use, fully managed service on GCP for running Apache Spark and Apache Hadoop workloads in a simple, cost-efficient way. Even though Cloud Dataproc instances can remain stateless, we recommend persisting the Hive data in Cloud Storage and the Hive metastore in MySQL on Cloud SQL.
Check out the tutorial for all the details on deploying your Hive workloads to GCP!

