How to use advance feature engineering to preprocess data in BigQuery ML
Mike Henderson
Customer Engineer
Ian Zhao
Software Engineer
The preprocessing and transformation of raw data into features constitutes a pivotal yet time-intensive phase within the machine learning (ML) process. This holds particularly true when data scientists or data engineers are required to transfer data across diverse platforms for the purpose of carrying out MLOps. In February 2023 we announced the preview of two new capabilities for BigQuery ML: more data preprocessing functions and the ability to export the BigQuery ML TRANSFORM clause as part of the model artifact. Today, these features are going GA and have even more capabilities for optimizing your ML workflow. In this blogpost, we describe how we streamline feature engineering by keeping it close to ML training and serving, with the following new functionalities:
More manual preprocessing functions that give the flexibility users need to prepare their data as features for ML while also enabling simplified serving by embedding the preprocessing steps directly in the model.
More seamless integration with Vertex AI amplifies this embedded preprocessing by making it fast to host BigQuery ML models on Vertex AI Prediction Endpoints for serverless online predictions that scale to meet your applications demand.
Ability to export the BigQuery ML TRANSFORM clause as part of the model artifact which makes the BigQuery ML models portable and can be used in other workflows where the same preprocessing steps are needed.
Feature Engineering
The manual preprocessing functions are big timesavers for setting up your data columns as features for ML. The list of available preprocessing functions now includes:
ML.MAX_ABS_SCALER Scale a numerical column to the range [-1, 1] without centering by dividing by the maximum absolute value.
ML.ROBUST_SCALER Scale a numerical column by centering with the median (optional) and dividing by the quantile range of choice ([25, 75] by default).
ML.NORMALIZER Turn a numerical array into a unit norm array for any p-norm: 0, 1, >1, +inf. The default is 2 resulting in a normalized array where the sum of squares is 1.
ML.IMPUTER Replace missing values in a numerical or categorical input with the mean, median or mode (most frequent).
ML.ONE_HOT_ENCODER One-hot encodes a categorical input. Also, it optionally does dummy encoding by dropping the most frequent value. It is also possible to limit the size of the encoding by specifying k for the k most frequent categories and/or a lower threshold for the frequency of categories.
ML.MULTI_HOT_ENCODER Encode an array of strings with integer values representing categories. It is possible to limit the size of the encoding by specifying k for the k most frequent categories and/or a lower threshold for the frequency of categories.
ML.LABEL_ENCODER Encode a categorical input to integer values [0, n categories] where 0 represents NULL and excluded categories. You can exclude categories by specifying k for k most frequent categories and/or a lower threshold for the frequency of categories.
Step-by-step examples of all preprocessing functions
This first tutorial shows how to use each of the preprocessing functions. In the interactive notebook a data sample and multiple uses of each function are used to highlight the operation and options available to adapt these functions to any feature engineering tasks. For example, the task of imputing missing values has different options depending on the data type of the column (string or numeric). The example below (from the interactive notebook) shows each possible way to impute missing value for each data type:
The table that follows shows the inputs with missing values highlighted in red and the outputs with imputed values for the different strategies highlighted in green.
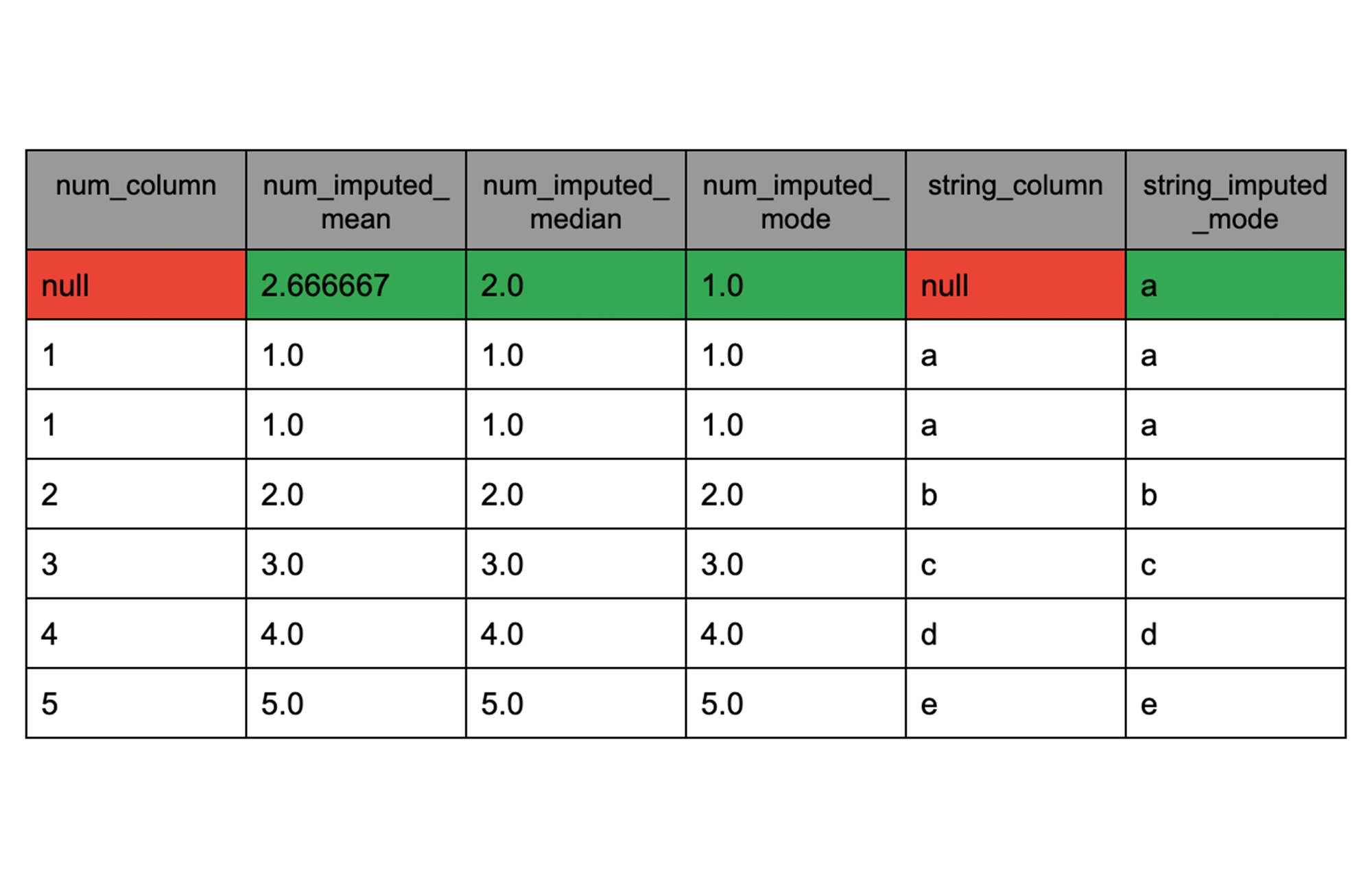
Visit the notebook linked above for this and more examples of all the preprocessing functions.
Training with the TRANSFORM clause
Now, when exporting models with a TRANSFORM clause even more SQL functions are supported for the accompanying exported preprocessing model. Supported SQL functions include:
Manual preprocessing functions
Operators
Conditional expressions
Mathematical functions
Conversion functions
String functions
Date, Datetime, Time, and Timestamp functions
To host a BigQuery ML trained model on Vertex AI you can bypass the export steps and automatically register the model to the Vertex AI Model Registry during training. Then, when you deploy the model to a Vertex AI Prediction Endpoint for online prediction the TRANSFORM clauses preprocessing is also included in the endpoint for seamless training-serving workflows. This means there is no need to apply preprocessing functions again before getting predictions from the online endpoint! Serving models is also as simple as always within BigQuery ML using the PREDICT function.
Step-by-step guide to incorporating manual preprocessing inside the model with the inline TRANSFORM clause:
In this tutorial, we will use the bread recipe competition dataset to predict judges rating using linear regression and boosted tree models.
Objective: To demonstrate how to preprocess data using the new functions, register the model with Vertex AI Model Registry, and deploy the model for online prediction with Vertex AI Prediction endpoints.
Dataset: Each row represents a bread recipe with columns for each ingredient (flour, salt, water, yeast) and procedure (mixing time, mixing speed, cooking temperature, resting time). There are also columns that include judges ratings of the final product from each recipe.
Overview of the tutorial: Step 1 shows how to use the TRANSFORM statement while training the model. Step 2 demonstrates how to deploy the model for online prediction using Vertex AI Prediction Endpoints. A final example is given to show how to export the model and access the transform model directly.
For the best learning experience, follow this blog post alongside the tutorial notebook.
Step 1: Create models using an inline TRANSFORM clause
Using the BigQuery ML manual preprocessing function highlighted above and additional BigQuery functions to prepare input columns into features within a TRANSFORM clause is very similar to writing SQL. The added benefit of having the preprocessing logic embedded within the trained model is that the preprocessing is incorporated in the prediction routine both within BigQuery with ML.PREDICT and outside of BigQuery, like the Vertex AI Model Registry for deployment to Vertex AI Prediction Endpoints.
The query below creates a model to predict judge A’s rating for bread recipes. The TRANSFORM statement uses multiple numerical preprocessing functions to scale columns into features. The values needed for scaling are stored and used at prediction to scale prediction instances as well.
The contestant_id column is not particularly helpful for prediction as new seasons will have new contestants but the order of contestants could be helpful if, perhaps, contestants are getting generally better at bread baking. To transform contestants into ordered labels the ML.LABEL_ENCODER function is used.
Using columns like season and round as features might not be helpful for predicting future values. A more general indicator of time would be the year and week within the year. Turning the airdate (date on which the episode aired) into features with the EXTRACT function is done directly in the TRANSFORM clause as well.
Note that the model training used options to directly register the model in Vertex AI Model Registry. This bypasses the need to export and subsequently register the model artifacts in the Vertex AI Model Registry while also keeping the two locations connected so that if the model is removed from BigQuery it is also removed from Vertex AI. It also enables a very simple path to online predictions as shown in Step 2 below.
In the interactive notebook the resulting model is also used with the many other functions to enable an end-to-end MLOps journey directly in BigQuery:
ML.FEATURE_INFO to review summary information for each input feature used to train the model
ML.TRAINING_INFO to see details from each training iteration of the model
ML.EVALUATE to review model metrics
ML.FEATURE_IMPORTANCE to review the feature importance scores from the construction of the boosted tree
ML.GLOBAL_EXPLAIN to get aggregated feature attribution for features across the evaluation data
ML.EXPLAIN_PREDICT to get prediction and feature attributions for each instance of the input
ML.PREDICT to get predictions for input instances
Step 2: Serve online predictions with Vertex AI Prediction Endpoints
By using options to register the resulting model in the Vertex AI Model Registry during step 1 the path to online predictions is made very simple. Models in the Vertex AI Model Registry can be deployed to Vertex AI Prediction Endpoints where they can serve predictions from Vertex AI API using any of the client libraries (Python, Java, Node.js), gcloud ai, REST or gRPC.
The process can be done directly from the Vertex AI console as shown here and is demonstrated below with the popular Python client for Vertex AI, named google-cloud-aiplatform.
Setting up the Python environment to work with the Vertex AI client requires just an import and setting the project and region for resources:
Connecting to the model in the Vertex AI Model Registry is done using the model name which was specified in the CREATE MODEL statement with the option VERTEX_AI_MODEL_ID:
Creating a Vertex AI Prediction Endpoints requires just a display_name:
The action of deploying the model to the endpoint requires specifying the compute environment with:
traffic_percentage: percentage of requests routed to the model
machine_type: the compute specification
min_replica_count and max_replica_count: the compute environment's minimum and maximum number of machines used in scaling to meet the demand for predictions.
Request a prediction by sending an input instance with key:value pairs for each feature. Note that the features are the raw features rather than needing to preprocess them into the model features like contestant, year, week and other scaled features:
The response returned is the predicted score from Judge A of a 73.5267944335937 which is also confirmed in the tutorial notebook using the model in BigQuery with ML.PREDICT. Not the best bread, but a great prediction since the actual answer is 75.0!
(Optional) Exporting Models With Inline TRANSFORM clause
While there is no longer a need to export the model for use in Vertex AI thanks to the direct registration options available during model creation, it can still be very helpful to make BigQuery ML models portable for use elsewhere or in more complex workflows like model co-hosting with deployment resource pools or workflows with multiple models using NVIDIA Triton on Vertex AI Prediction. When exporting BigQuery ML models to GCS the TRANSFORM clause is also exported as a separate model in a subfolder named /transform. This means even the transform model is portable and can be used in other workflows where the same preprocessing steps are needed.
If you used BigQuery time or date functions (Date functions, Datetime functions, Time functions and Timestamp functions) then you might wonder how the exported TensorFlow model that represents the TRANSFORM clause handles those data types. We implemented a TensorFlow Custom op that can be easily added to your custom serving environment via the bigquery-ml-utils Python package.
To initiate the export to GCS use the BigQuery EXPORT MODEL statement:
The tutorial notebooks show the folder structure and contents and how to use the TensorFlow SavedModel CLI to review the transform models input and output signature.
Conclusion
BigQuery ML preprocessing functions give the flexibility users need to prepare their data as features for ML while also enabling simplified serving by embedding the preprocessing steps directly in the model. Creating a seamless integration with Vertex AI amplifies this embedded preprocessing by making it fast to host BigQuery ML models on Vertex AI Prediction Endpoints for serverless online predictions that scale to meet your applications demand. Ultimately making building models easy while making the models useful through simple serving options. In the future you can expect to see even more ways to simplify ML workflows with BigQuery ML while seamlessly integrating with Vertex AI.

