Ethereum in BigQuery: how we built this dataset

Evgeny Medvedev
Author of Blockchain ETL
Allen Day
Developer Advocate, Digital Assets at Google Cloud
In this blog post, we’ll share more on how we built the BigQuery Ethereum Public Dataset that contains the Ethereum blockchain data. This includes the primary data structures—blocks, transactions—as well as high-value data derivatives—token transfers, smart contract method descriptions.
Leveraging the power of BigQuery allows you to access the Ethereum blockchain via SQL and find meaningful insights rapidly. This data can also be easily exported to CSV, Avro, or JSON files and used for further analysis using graph databases, visualization tools, and machine learning frameworks.
We focused on simplicity, consistency, and reliability when working on this project. Some interesting challenges and important design decisions will be covered in the following sections. Below, we’ll also demonstrate some powerful BigQuery features that allow disassembling all Ethereum smart contracts in seconds.
Our architecture
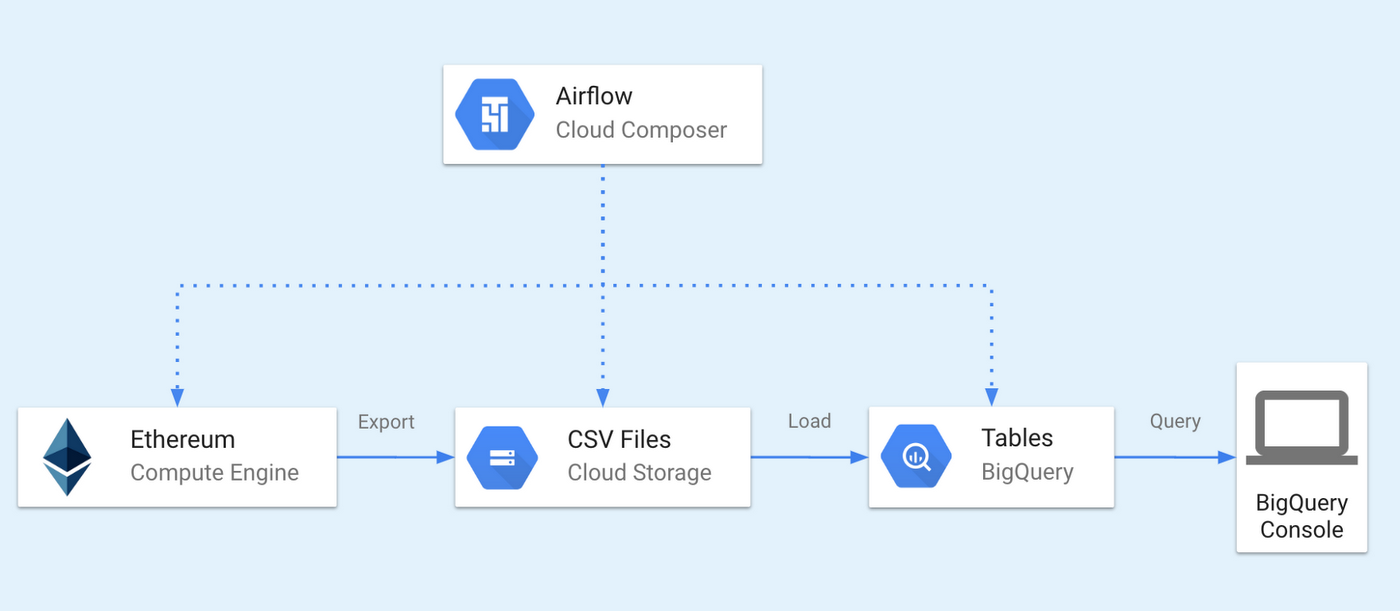
The ingestion pipeline is divided into two phases: export and load. They are coordinated by Google Cloud Composer—a fully managed workflow orchestration service built on Apache Airflow.
The first phase relies on Ethereum ETL—an open-source tool we developed for exporting the Ethereum blockchain into CSV or JSON files. It connects to an Ethereum node via its JSON RPC interface. The exported files are then moved to Google Cloud Storage.
In the second phase, the exported files are further processed, loaded into BigQuery, and finally verified. You can then query the data in the BigQuery console or via API.
Here is how the DAGs (directed acyclic graphs) page for the Ethereum ETL project looks like in the Airflow console:
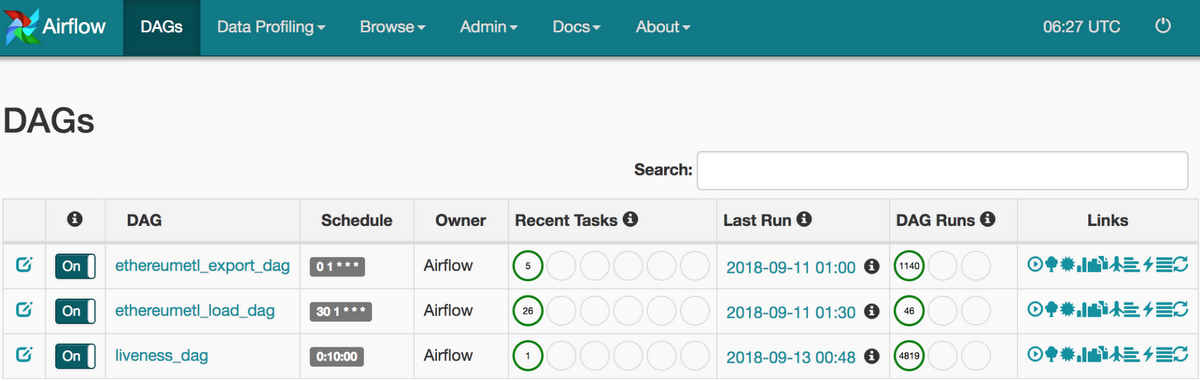
The following three sections, Export, Load, and Query, cover the stages of the workflow in more detail.
Export
Clicking on the Graph View link forethereumetl_export_dag shows this view: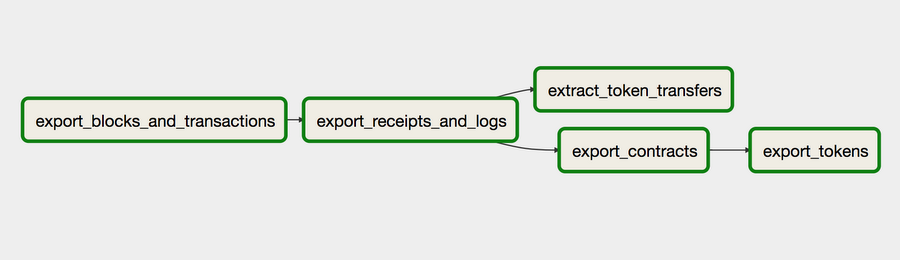
Stateless Workflow
The workflow starts with export_blocks_and_transactions task where a command from Ethereum ETL named get_block_range_for_date.py is invoked. Here is an example of usage:
$ python get_block_range_for_date.py --date 2018-01-01
> 4832686,4838611
It returns a block range given a date. This command uses Ethereum JSON RPC API to probe the first and the last blocks, then narrows the bounds recursively using linear interpolation until the required blocks are found. This algorithm is called Interpolation Search and takes O(log(log(n)) time (no typo there) on uniformly distributed data. We implemented an improved version, which handles the worst case by probing estimation points differently, depending on whether the graph is convex or concave.
This handy command eliminates the need to store the latest synchronised block, making the workflow stateless. You can simply schedule the export tasks daily or hourly and get the block range to export based on the execution timestamp.
Batching JSON RPC requests
Both go-ethereum and parity-ethereum support batch JSON RPC requests. They make the exporting process orders of magnitude faster by reducing the number of round trips to Ethereum nodes. Unfortunately, batch requests are not supported by most Ethereum API clients as this feature requires language-specific architecture and needs to be thought through in the early stages of code design.
That’s why we implemented custom providers that support batch requests, which gave us an almost 10-fold boost in performance. This is the command that exports blocks in batches of 100 by default:
$ python export_blocks_and_transactions.py --start-block $START_BLOCK --end-block $START_BLOCK --blocks-output blocks.csv --transactions-output transactions.csv
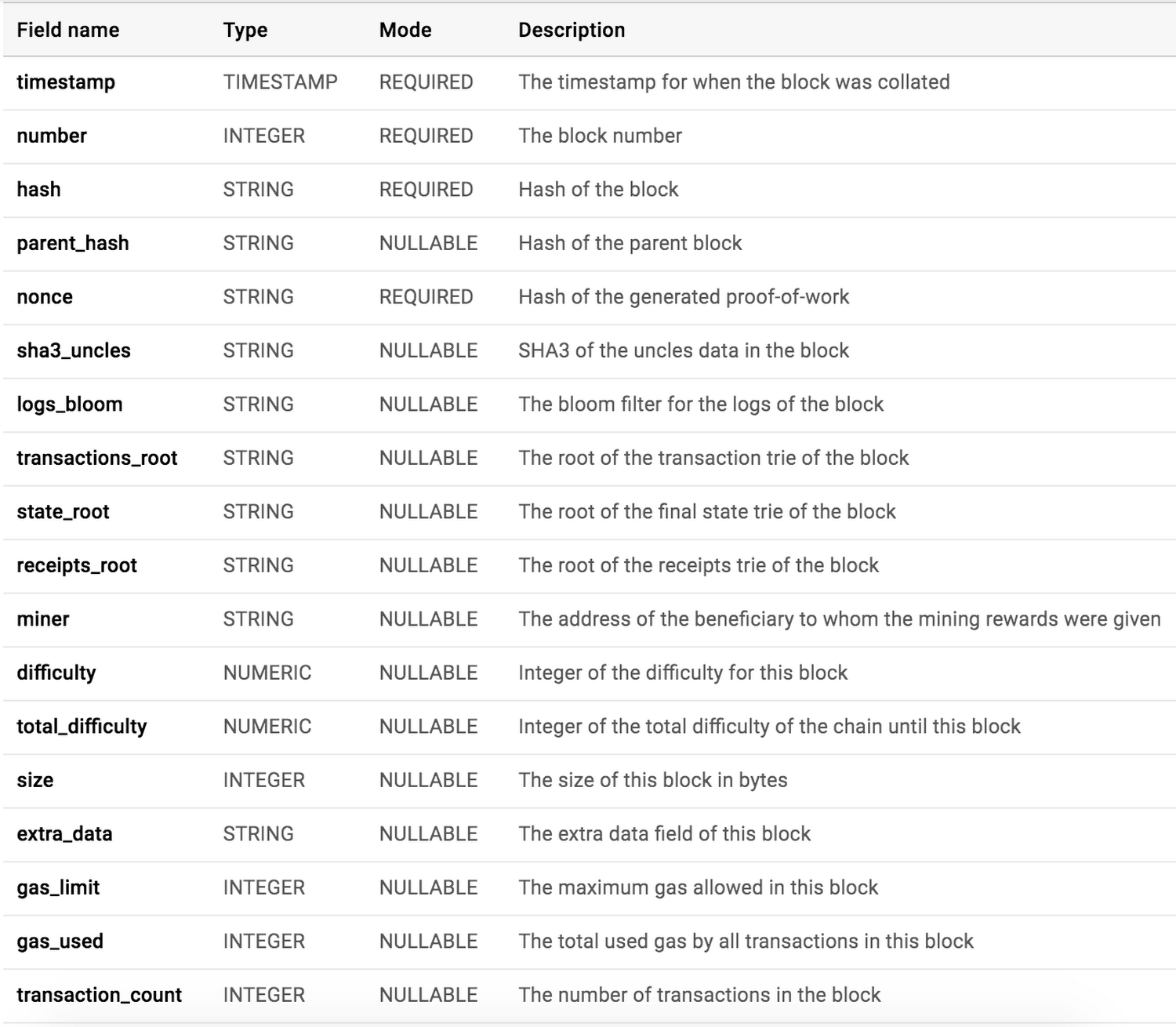
Below is the schema for the blocks table in BigQuery:
Transaction receipts are slowest
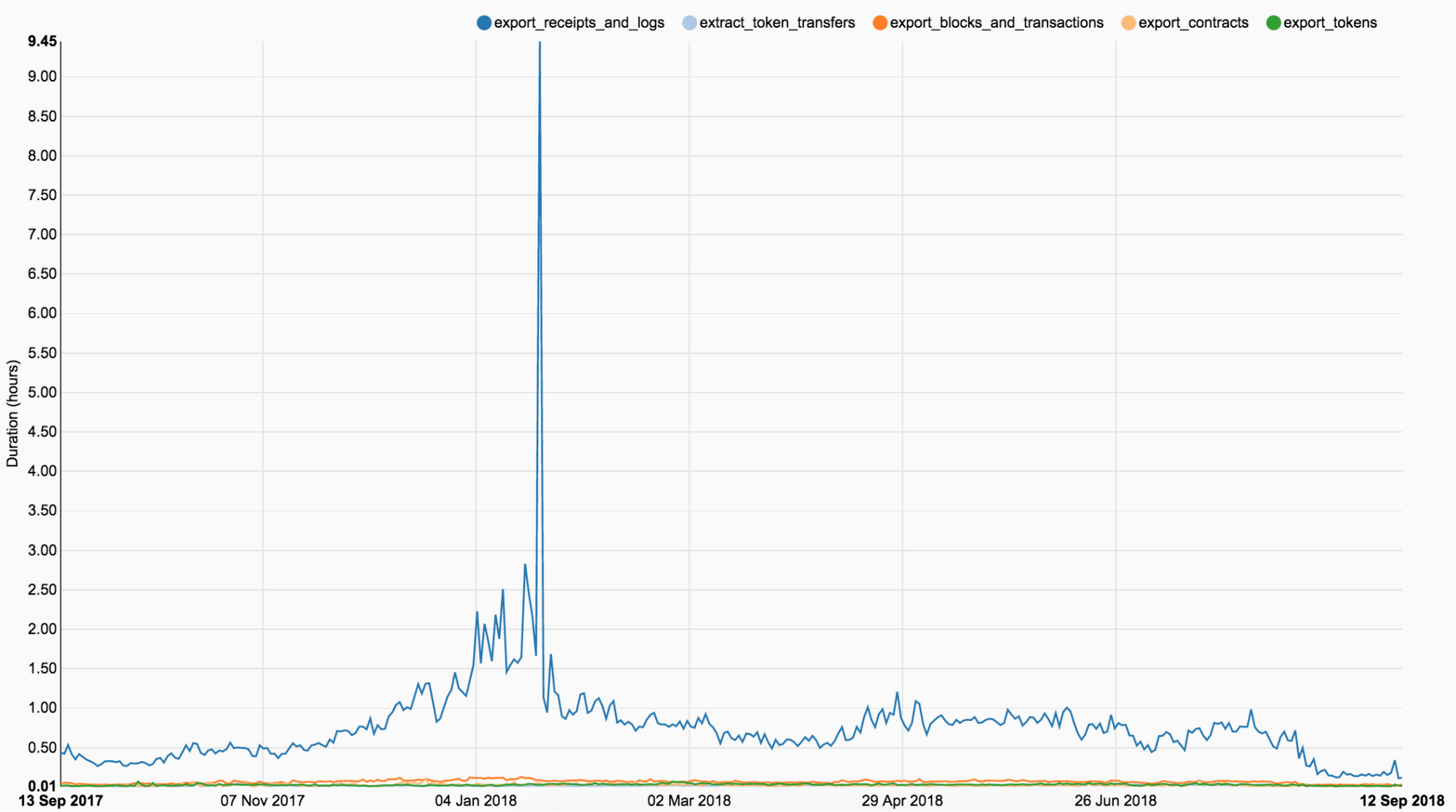

This graph shows how long it takes to export a particular piece of data. As you can see, the exporting of receipts and logs runs significantly longer than all the other tasks.
A receipt in Ethereum is an object containing information about the result of a transaction, such as its status, gas used, the set of logs created through execution of the transaction and the Bloom filter composed from information in those logs. The reason exporting receipts is so slow is that JSON RPC API only allows retrieving receipts one by one, unlike transactions, which can be retrieved per block. Even with request batching, this process is very slow.
With the introduction of an API method that allows retrieving all receipts in a block, this issue will be solved. Here are feature requests for geth and parity that you should upvote if you want to support the project: geth, parity.
Exporting ERC20 token transfers
As defined in the ERC20 standard, every token transfer must emit a Transfer event with the following signature:
Transfer(address indexed _from, address indexed _to, uint256 _value)
Solidity events correspond to logs in EVM (Ethereum Virtual Machine), which are stored in the transaction’s log — a special data structure in the blockchain. These logs are associated with the address of the contract and are incorporated into the blockchain.
Every log contains a list of topics associated with it, which are used for index and search functionality. The first topic is always the Keccak hash of the event signature; you can calculate it with a command from Ethereum ETL:
$ python get_keccak_hash.py -i "Transfer(address,address,uint256)"> 0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef
The task extract_token_transfers takes the file produced by export_receipts_and_logs, filters the logs by the above topic and writes the extracted token transfers to the output CSV file.
There is an alternative way of exporting token transfers that is more convenient if you don’t need receipts and logs and only care about ERC20 tokens. You can use export_token_transfers.py, which relies on eth_getFilterLogs API to retrieve the transfers directly from the Ethereum node, bypassing the logs extraction step.
Exporting contracts
Contracts in Ethereum are created with a special kind of transaction in which the receiver is set to 0x0. The receipt for such a transaction contains a contractAddress field with the address of the created contract. This field is passed to eth_getCode API to retrieve contract bytecode.
Disassembling the bytecode with ethereum-dasm allows getting the initialization block of the contract and all PUSH4 opcodes in it. The operands to PUSH4 are the first 4 bytes of the Keccak hash of the ASCII form of the function signature, as explained in Solidity documentation. Below is an example output of ethereum-dasm:
These 4-byte hashes serve as function IDs in transactions that are calls to contracts. For example, the ID of the transfer(address,uint256) function is 0xa9059cbb, so transactions invoking this method will contain 0xa9059cbb as a prefix in the data field.
Given that we can get all function IDs in a contract, we can tell if it conforms to some interface, such as ERC20. If all of the methods, defined in the standard, are present in a contract, we mark it as matching or belonging to type ERC20. All function signature hashes of a contract are stored in the function_sighashes column in the contracts table; additionally, we provide the is_erc20 and is_erc721 columns for convenience.
The result of exporting contracts and the other export tasks in Airflow are the files in a Cloud Storage bucket, partitioned by day. These files are loaded to BigQuery in ethereumetl_load_dag.
Load
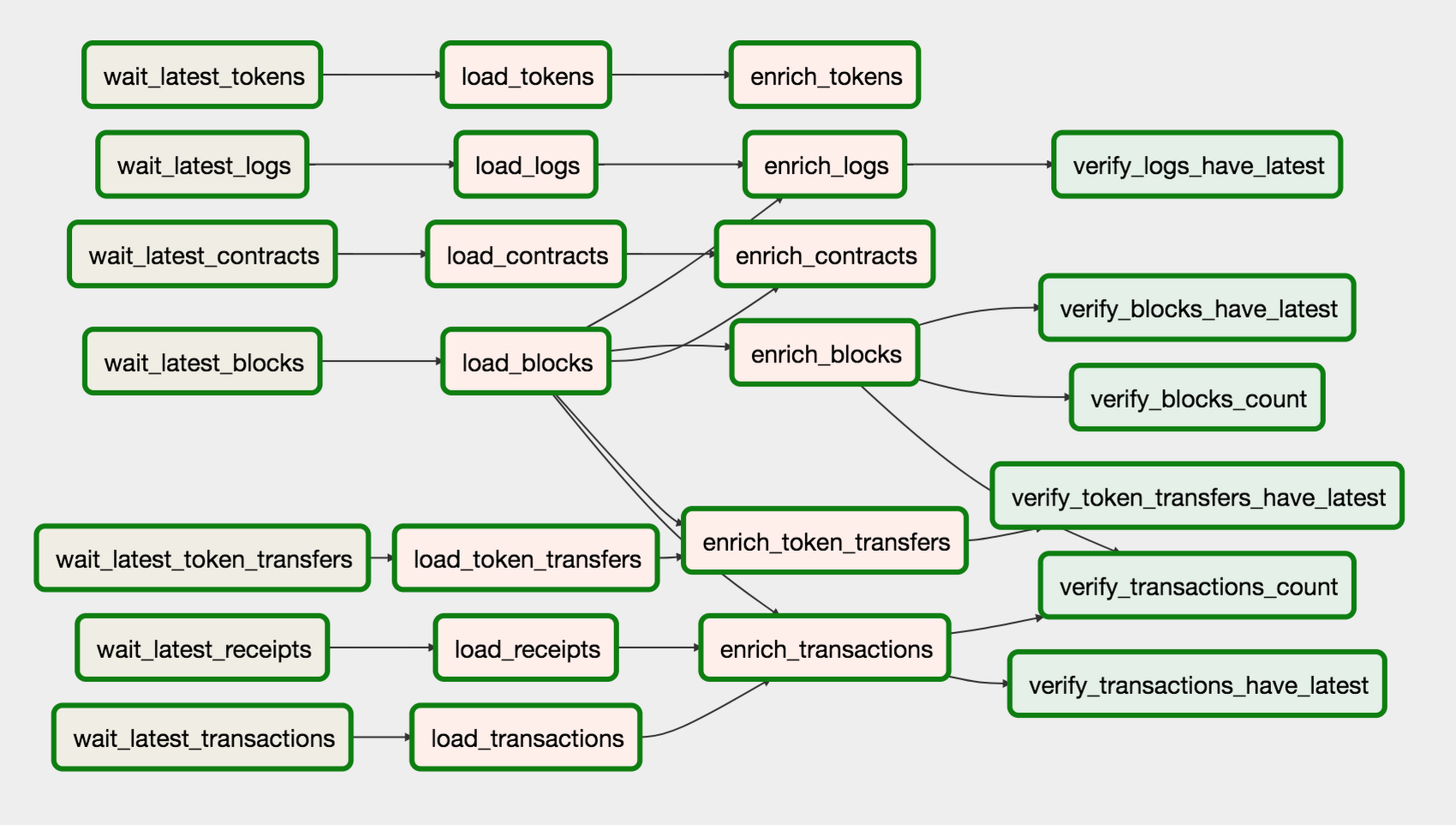
wait_*tasks wait for an export file on a particular day.load_*tasks load the data from a Cloud Storage bucket to BigQuery tables.enrich_*tasks join multiple tables and cast columns to different types.verify_*tasks run SQLs that verify the consistency of the data.
Atomicity and idempotence
We wanted to make sure all operations in the workflow are atomic and idempotent, as these properties are necessary to guarantee the consistency of the data. Idempotency means you can run an operation multiple times and the result will be as if you ran it just once. It allows Airflow to retry the tasks without keeping or checking any state.
All export tasks are idempotent because the output files will be overwritten in the Cloud Storage bucket, after multiple runs. BigQuery load and query operations are atomic and idempotent, which means there will be no case in which query results are incorrect, even during the process of loading new data.
The idempotence restriction is the reason we don’t append tables with new data, but instead reload all CSV files starting from the genesis block; otherwise we’d end up with duplicate records if a task is retried. Fortunately, load operations are free in BigQuery. A more efficient implementation would be to replace a single partition; we’ll implement this approach at a future date when we add streaming support.
Streaming
We don’t use BigQuery streaming because ensuring consistency in this case requires additional setup. Without it you can end up having duplicate or missing rows in your tables. Another obstacle to ensuring consistency is chain reorganizations in Ethereum. This is a situation when a temporary fork happens in the blockchain, which could make blocks previously streamed to BigQuery stale.
We plan to use streaming alongside daily tasks, which will load and replace past-day partitions (approach called Lambda Architecture). This will make the data eventually consistent — only the last day may have duplicates, missing rows, and stale blocks, while all the previous days will be strongly consistent. The feature in BigQuery that allows this is the ability to load and query a single partition. For example the following command loads only data for the date June 23, 2018:
$ bq load --destination_table ethereum_blockchain.blocks$20180623 gs://<bucket>/*.csv
The result of ethereumetl_load_dag is enriched tables in the BigQuery dataset, which you can query in the console or via API.
Query
You can access the dataset here. You’ll find all the tables, their schema, and you’ll be able to run queries. Below is the query to retrieve transaction volume in Ether: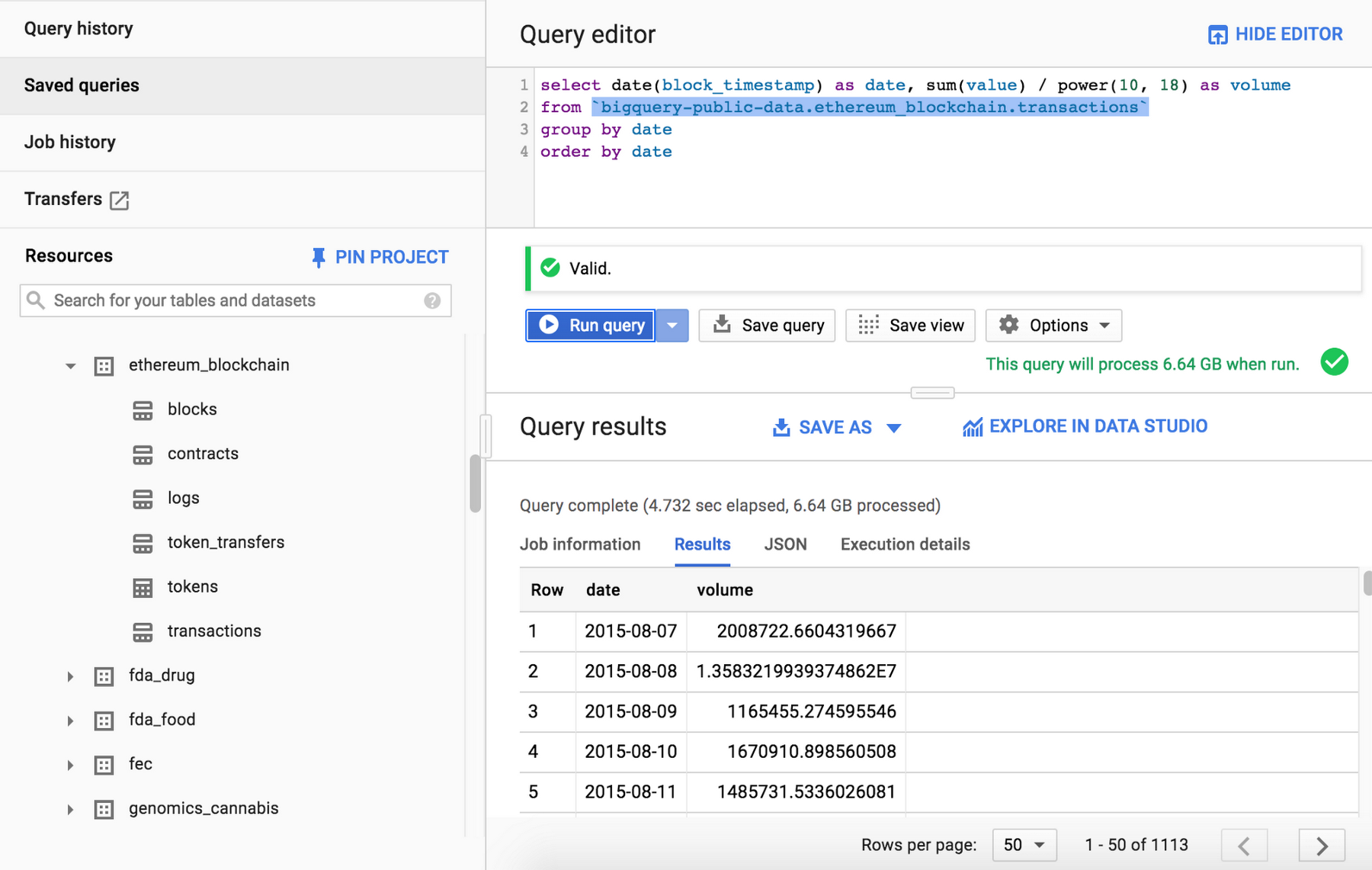
Right from the BigQuery console, you can launch Data Studio by clicking on “Explore in Data Studio,” where you can visualize the data:
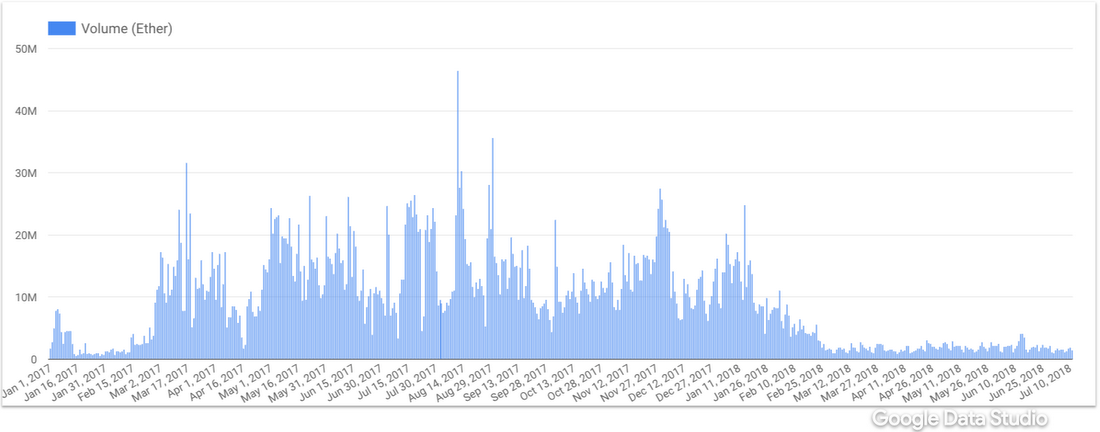
That’s a simple query just for the demonstration, but you can be a lot more creative when composing your queries. Check out this blog post for the examples.
We at CoinFi use this dataset to compute ERC20 token metrics: token velocity, number of unique wallets, token retention rate, token distribution, and more.
Using JavaScript UDFs for in-engine smart contract analytics
Another cool feature of BigQuery is the ability to write user defined functions (UDFs) in SQL or JavaScript. This JavaScript file contains a function for disassembling Ethereum contract bytecode: disassemble_bytecode.js. You can use it to disassemble the CoinFi smart contract:
Here is the result:
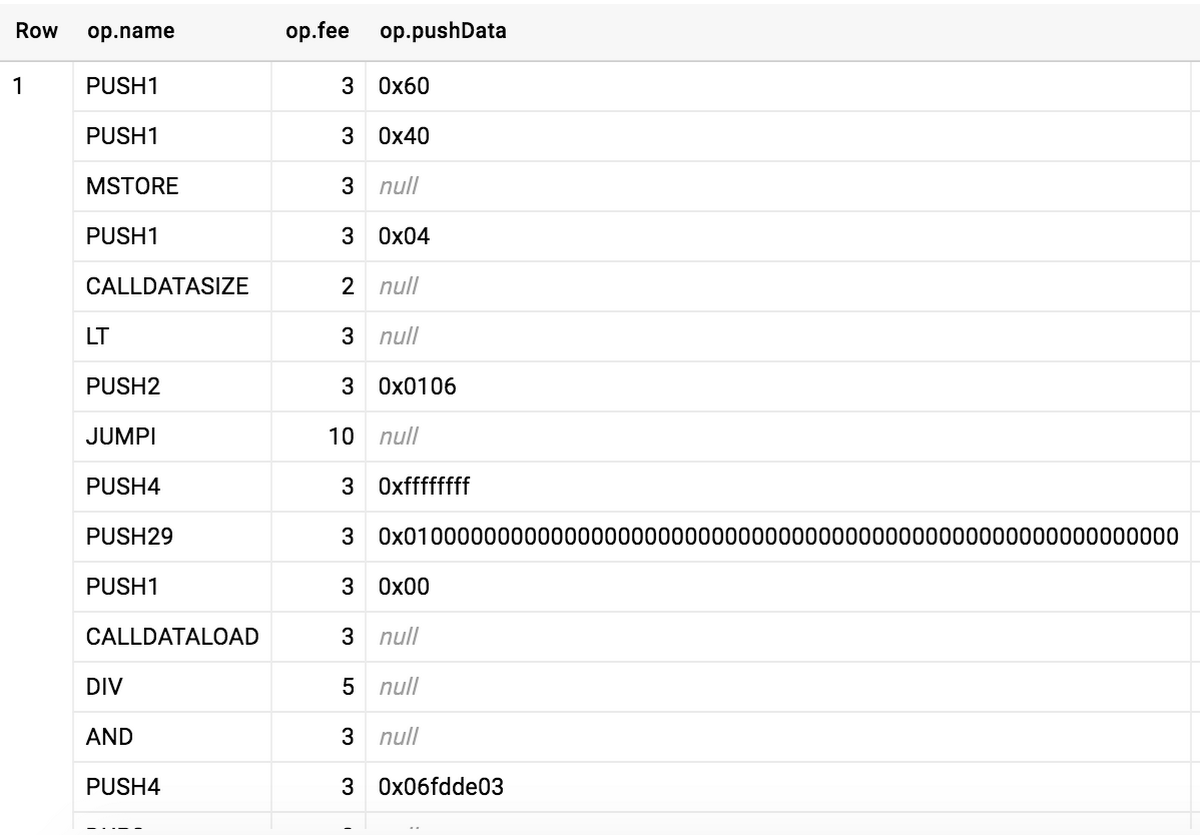
You can even disassemble all contracts in the dataset and see which opcodes are most frequent. The query that demonstrates this, as well as the ability to work with arrays and structs in BigQuery, can be found here.
You can try to do many other things with UDFs, for instance parse transaction inputs, parse event logs, or even run EVM! (Just kidding about that last one.) Check out other interesting queries and implementation details in my blog.
Future plans
The next big feature we are going to work on is support for message calls (a.k.a. internal transactions), which will uncover many interesting use cases such as querying all addresses that ever existed, along with their balances and querying all contracts. Another big feature is the streaming support, which will allow analysis of live Ethereum data.
You can find the list of open issues on Github: ethereum-etl, ethereum-etl-airflow. Also be sure to check out limitations before you start using the dataset.
Everyone reading this article is encouraged to contribute to the project — your contribution will be available in the public dataset. Feel free to contact us here if you would like to contribute or have any questions.
Disclaimer: Note that while we operate a full node that is in consensus with the Ethereum network, we are only peering existing data and are not contributing new data to the Ethereum blockchain. In other words, we are not mining Ethereum cryptocurrency as part of maintaining this BigQuery public dataset.


