Accelerate BigLake performance to run large-scale analytics workloads
Anoop Johnson
Principal Engineer
Deepak Nettem
Software Engineer, Google Cloud
Data lakes have historically trailed data warehouses in key features, especially query performance that limited the ability to run large-scale analytics workloads. With BigLake, we lifted these restrictions. This blog post shares an under-the-hood view of how BigLake accelerates query performance through a scalable metadata system, efficient query plans and materialized views.
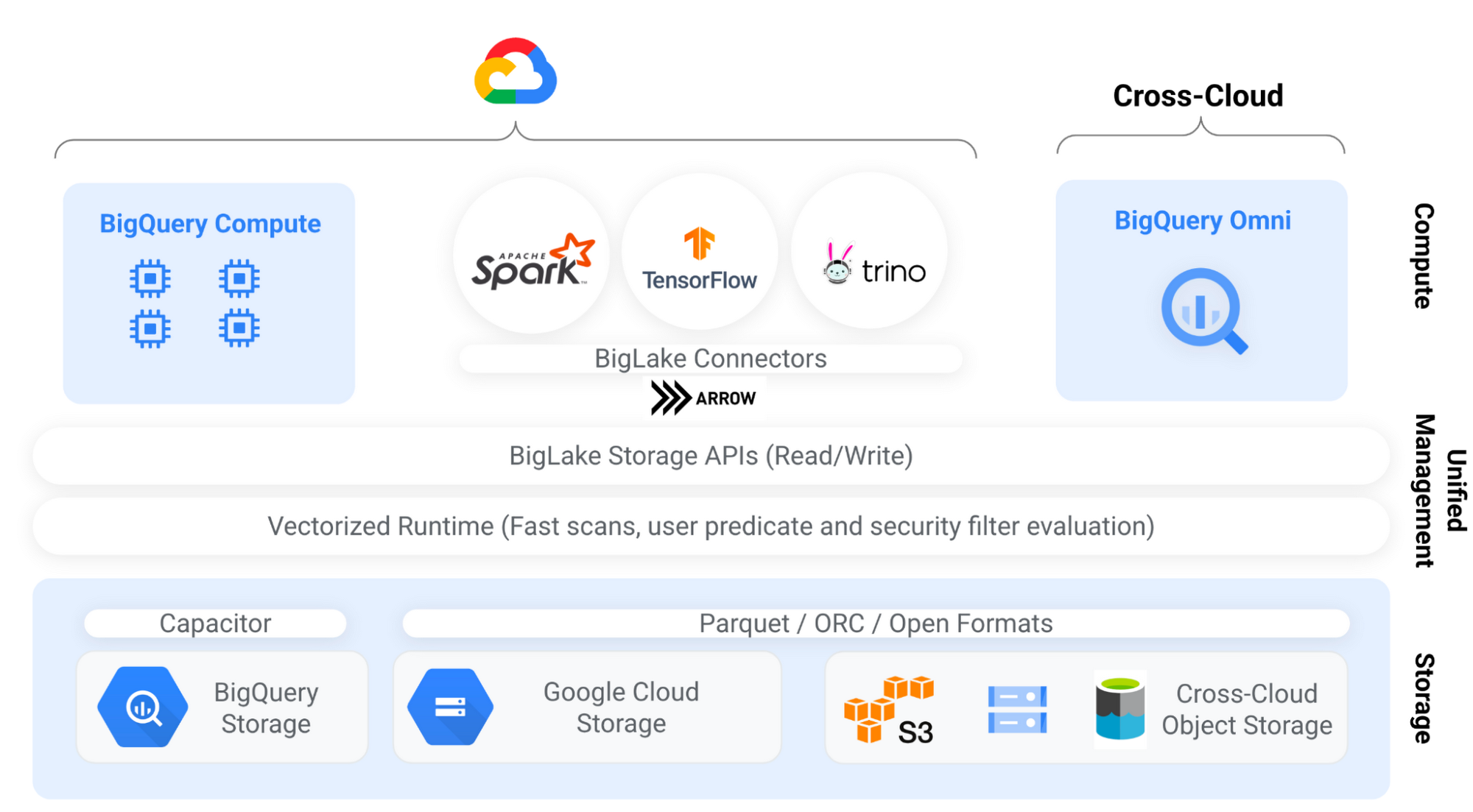
BigLake allows customers to store a single copy of the data on cloud object storage in open file formats such as Parquet, ORC, or open-source table formats such as Apache Iceberg. BigLake tables can be analyzed using BigQuery or an external query engine through high-performance BigLake storage APIs (not supported in BigQuery Omni currently). These APIs embed Superluminal, a vectorized processing engine that allows for efficient columnar scans of the data and enforcement of user predicates and security filters. There is zero expectation of trust from external query engines, which is especially significant for engines such as Apache Spark that run arbitrary procedural code. This architecture allows BigLake to offer one of the strongest security models in the industry.
Several Google Cloud customers leverage BigLake to build their data lake houses at scale.
“Dun & Bradstreet aspires to build a Data Cloud with a centralized data lake and unified data process platform in Google Cloud. We had challenges in performance and data duplication. Google's Analytics Lakehouse architecture allows us to run Data Transformation, Business Analytics, and Machine Learning use cases over a single copy of data. BigLake is exactly the solution that we needed.'' - Hui-Wen Wang, Data Architect, Dun & Bradstreet
Accelerate query performance
Below, we describe recent performance improvements to BigLake tables by leveraging Google’s novel data management techniques across metadata, query planning and materialized views.
Improve metadata efficiency
Data lake tables typically require query engines to perform a listing operation on object storage buckets — and listing of large buckets with millions of files is inherently slow. On partitions that query engines cannot prune, the engine needs to peek at the file footers to determine if it can skip data blocks, requiring several additional IOs to the object store. Efficient partition and file pruning is crucial to speeding up query performance.
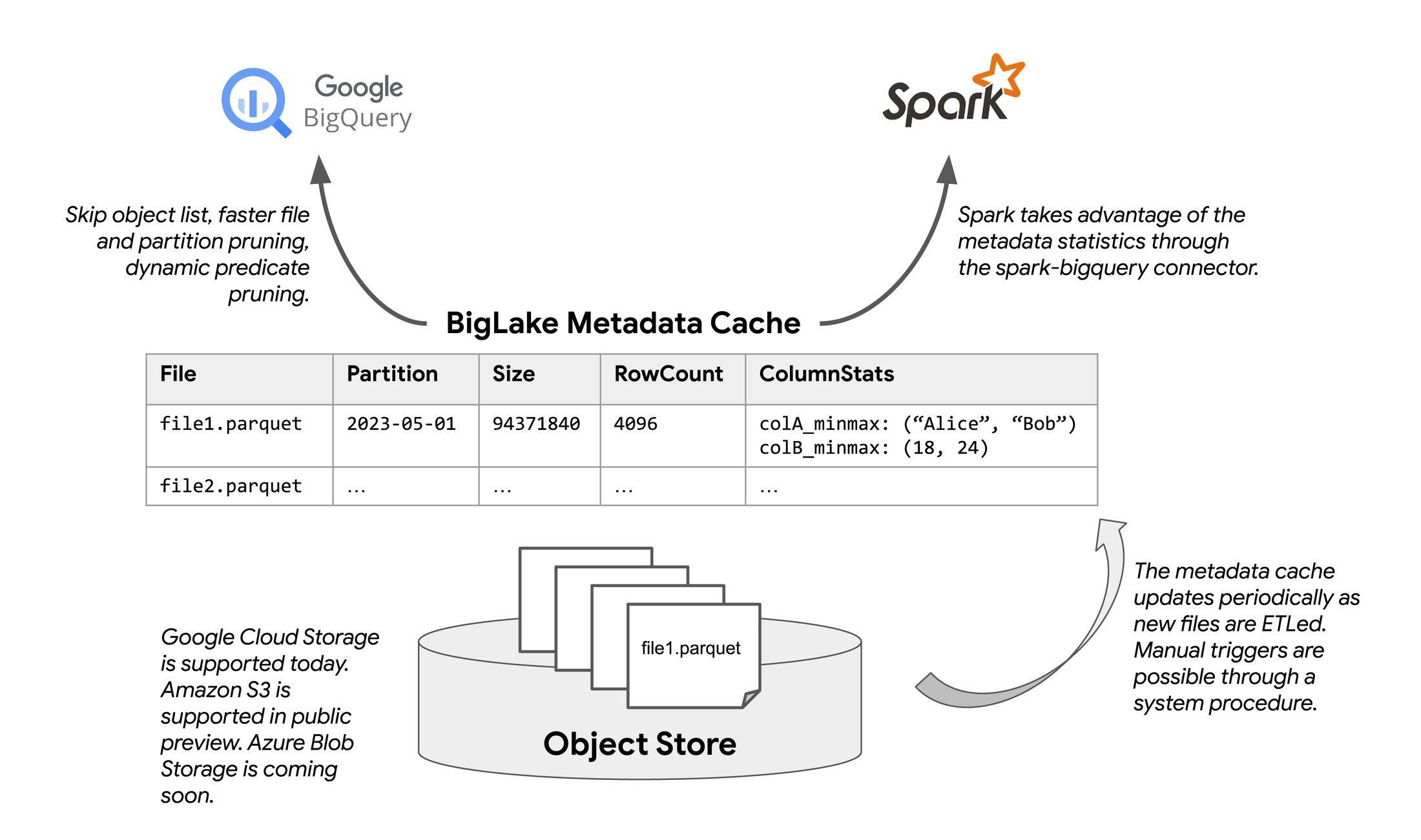
We are excited to announce the general availability of metadata caching for BigLake tables on GCS and the public preview launch on Amazon S3. This feature allows BigLake tables to automatically collect and maintain physical metadata about files in object storage. BigLake tables use the same scalable Google metadata management system employed for BigQuery native tables, known as Big Metadata.
Using Big Metadata infrastructure, BigLake caches file names, partitioning information, and physical metadata from data files, such as row counts and per-file column-level statistics. The cache tracks metadata at a finer granularity than systems like the Hive Metastore, allowing BigQuery and storage APIs to avoid listing files from object stores and achieve high-performance partition and file pruning.
Optimize query plans
Query engines need to transform an SQL query into an executable query plan. For a given SQL query, there are usually several possible query plans. The goal of a query optimizer is to choose the most optimal plan. A common query optimization is dynamic constraint propagation where the query optimizer dynamically infers predicates on the larger fact tables in a join from the smaller dimension tables. While this optimization can speed up queries using normalized table schemas, most implementations require reasonably accurate table statistics.
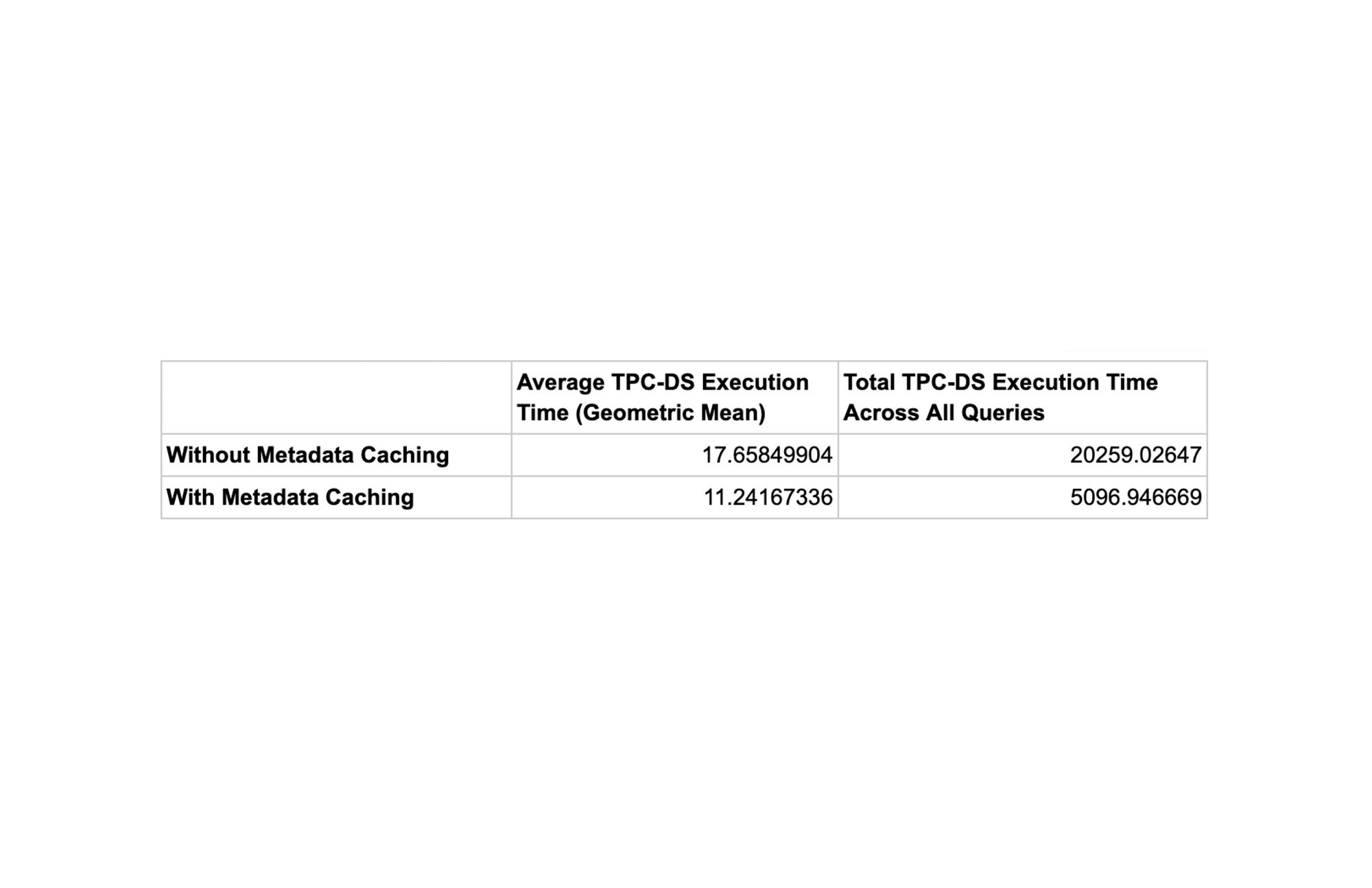
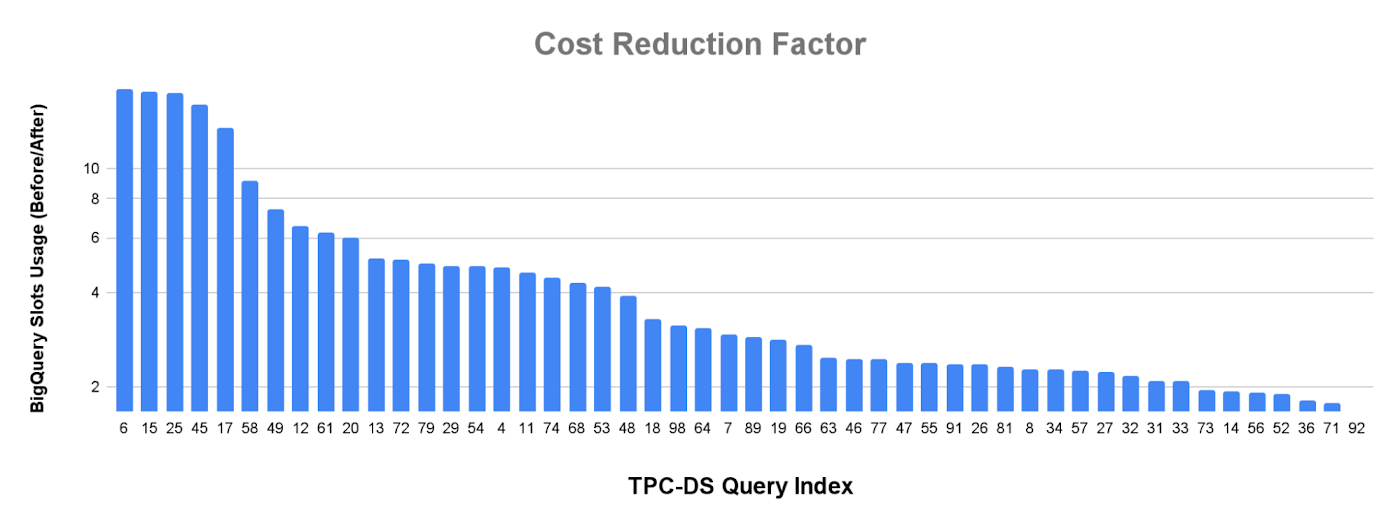
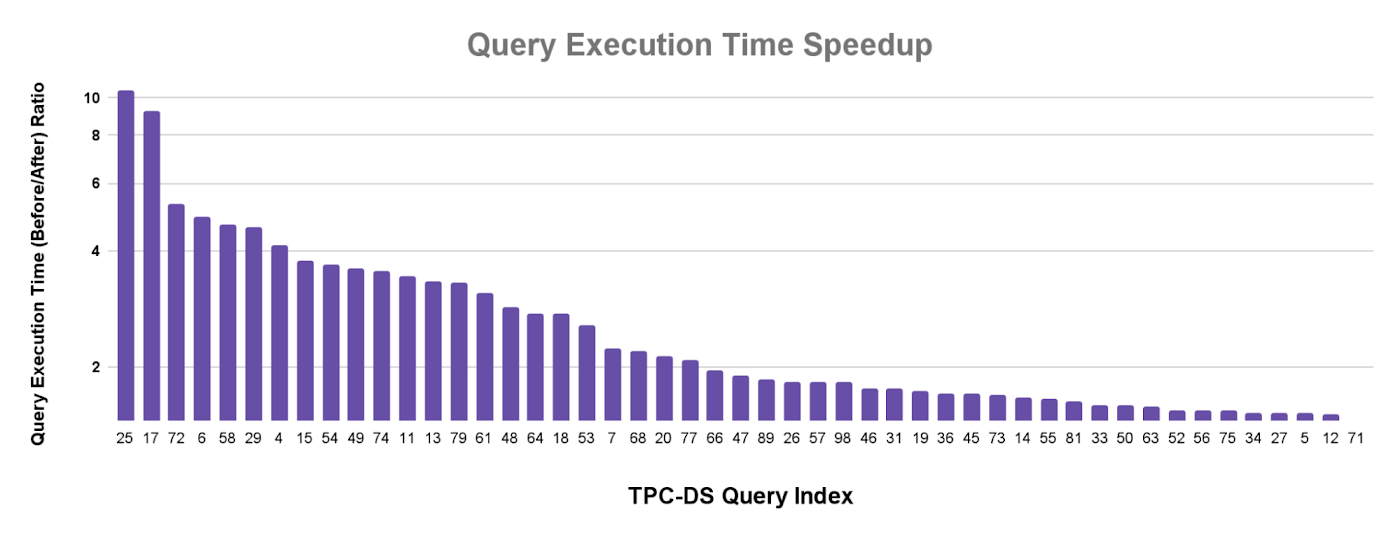
The statistics collected by metadata caching enable both BigQuery and Apache Spark to build optimized high-performance query plans. To measure the performance gains, we performed a power run of the TPC-DS Hive Partitioned 10T benchmark where each query is executed sequentially. Both the Cloud Storage bucket and the BigQuery dataset were in the us-central1 region and a 2000 slot reservation was used. The below chart shows how the BigQuery slot usage and the query execution time have improved for queries through the statistics collected by the BigLake metadata cache. Overall, the wall clock execution time decreased by a factor of four with metadata caching.
Supercharge Spark performance
The open-source Spark BigQuery connector allows reading BigQuery and BigLake tables into Apache Spark DataFrames. The connector uses BigQuery storage APIs under the hood and is integrated to Spark using Spark’s DataSource interfaces.
We recently rolled out several improvements in the Spark BigQuery connector, including:
Support for dynamic partition pruning.
Improved join reordering and exchange reuse.
Substantial improvements to scan performance.
Improved Spark query planning: table statistics are now returned through Storage API.
Asynchronous and cached statistics support.
Materialized views on BigLake tables
Materialized views are precomputed views that periodically cache the results of a query for improved performance. BigQuery materialized views can be queried directly or can be used by the BigQuery optimizer to accelerate direct queries on the base tables.
We are excited to announce the preview of materialized views over BigLake tables. These materialized views function like materialized views over BigQuery native tables, including automatic refresh and maintenance. Materialized views over BigLake tables can speed up queries since they can precompute aggregations, filters and joins on BigLake tables. Materialized views are stored in BigQuery native format and have all the performance characteristics of BigQuery native storage.
Next steps
If you’re using external BigQuery tables, please upgrade to BigLake tables and take advantage of these features by following the documentation for metadata caching and materialized views. To benefit from the Spark performance improvements, please use newer versions of Spark (>= 3.3) and the Spark-BigQuery connector. To learn more, check out this introduction to BigLake tables, and visit the BigLake product page.
Acknowledgments:
Kenneth Jung, Micah Kornfield, Garrett Casto, Zhou Fang, Xin Huang, Shiplu Hawlader, Fady Sedrak, Thibaud Hottelier, Lakshmi Bobba, Nilesh Yadav, Gaurav Saxena, Matt Gruchacz, Yuri Volobuev, Pavan Edara, Justin Levandoski and rest of the BigQuery engineering team. Abhishek Modi, David Rabinowitz, Vishal Karve, Surya Soma and rest of the Dataproc engineering team.

