Introducing the Dataflow ML Starter project: A practical template to develop and deploy Dataflow ML jobs
Xiangqian (XQ) Hu
Engineering Manager
As part of BigQuery’s integrated suite of capabilities; Dataflow ML enables scalable local and remote inference with batch and streaming pipelines, as well as facilitating data preparation for model training and processing the results of model predictions. Our new Dataflow ML Starter project provides all of the essential scaffolding and boilerplate required to quickly and easily create and launch a Beam pipeline. In detail, the Dataflow ML Starter project contains a basic Beam RunInference pipeline that deploys some image classification models to classify the given images. As shown in Figure 1, The pipeline either reads the Cloud Storage (GCS) file that contains image GCS paths or subscribes a Pub/Sub source to receive image GCS paths, pre-processes the input images, runs a PyTorch or TensorFlow image classification model, post-processes the results, and finally writes all predictions back to the GCS output file.
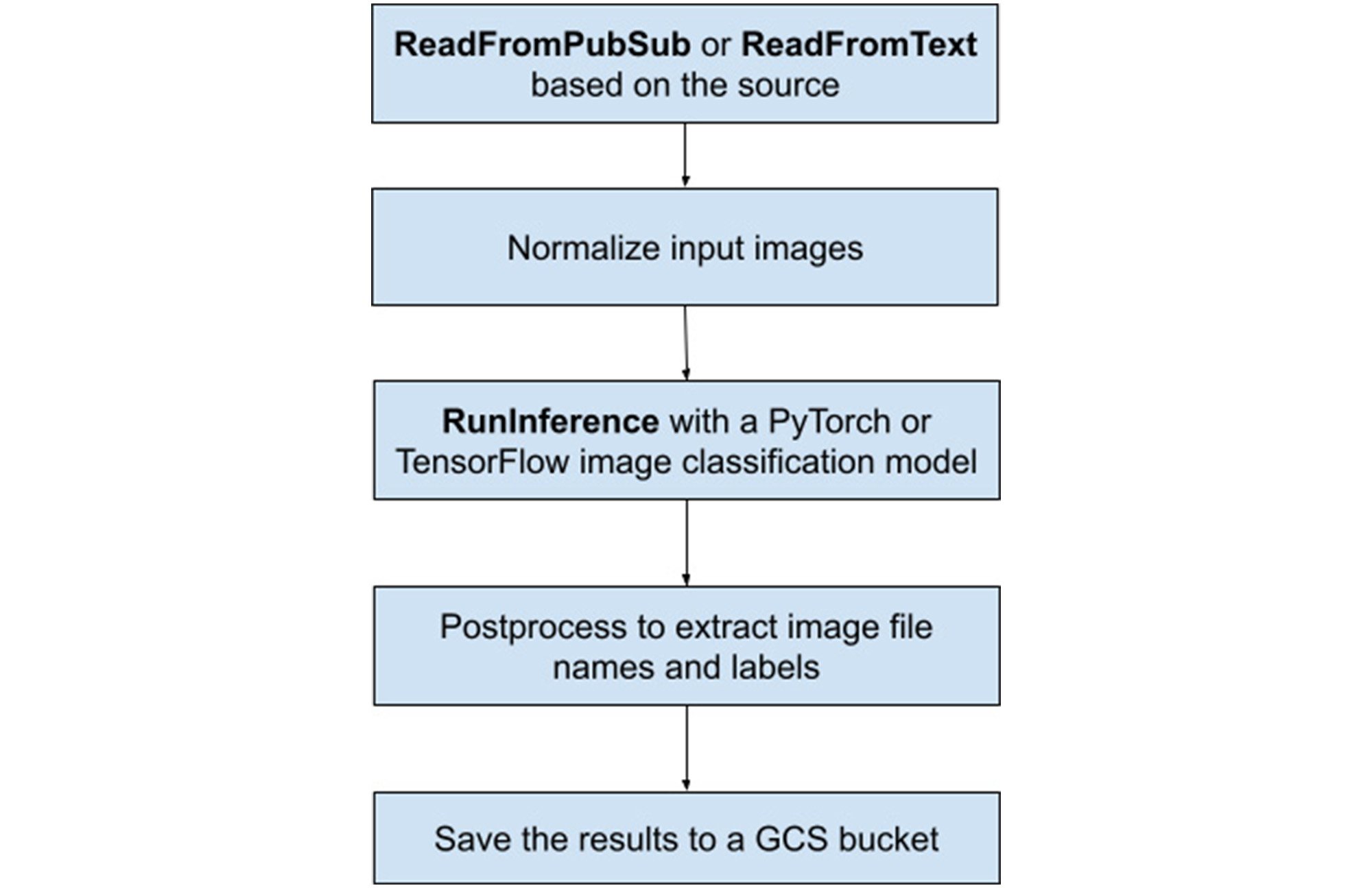
The project illustrates the entire Dataflow ML development process by walking the user through each step, including:
- Developing the Beam pipeline with a local Python environment and creating unit tests to validate the pipeline
- Running the Beam RunInference job using DataflowRunner with CPUs
- Improving the inference speed and using GPUs, building and testing a custom container using GCE VMs and providing some Dockerfile samples
- Demonstrating how to use Pub/Sub as the streaming source to classify images
- Demonstrating how to package all the code and apply a Dataflow Flex Template
In summary, the project produces a standard template that serves as a boilerplate, which can be easily modified to suit your specific needs.
To get started, visit the GitHub repository and follow the instructions. We believe that this starter project will be a valuable resource for anyone working with Dataflow ML. We are delighted to share our knowledge with the community and anticipate how it will help developers and data engineers achieve their goals. Please do not forget to star it if you find it helpful!

