Building ML workflows in BigQuery the easy way, without code
Javier de la Torre
Founder, CARTO
Matt Forrest
VP of Product Marketing
As enterprise data volumes continue to explode, and businesses depend more heavily on predictive analytics and automated decisioning, cloud data warehouses such as Google BigQuery are often the only viable option for organizations looking to implement ever-more complex and scalable workloads using ML and AI capabilities.
Cloud is the way for analytics at scale
BigQuery, with its compute and storage separation, enables unparalleled scalability, flexibility and cost-effectiveness. Our serverless data warehouse works across clouds and scales with your data; with BI, Machine Learning and AI built in. It is becoming the de facto choice for enterprises looking for a single source of data truth and truly scalable ML-driven analytics.
In this post, we'll explore how BigQueryML can be used in conjunction with an innovative visual analytics tool from our partner CARTO, to extend the reach of cloud native analysis to a broader user base.
CARTO Workflows is a flexible platform tool that automates analytical workflows using an easy-to-use, no code interface natively in BigQuery.
Traditional visual automation tools do not fully leverage the cloud and can be expensive
In today's data-driven world, enterprises are searching for efficient ways to conduct more advanced analytics and develop data-driven applications. BigQuery empowers analysts and data scientists to process massive volumes of data using familiar SQL commands. However, many alternative visual analytics tools fall short, as they are not entirely cloud-native. These solutions rely on inflexible and expensive desktop or server-based infrastructures, which often lack comprehensive data governance, encounter performance limitations, and prove costly when scaling on demand.
Introducing CARTO Workflows, visual analytics native to BigQuery
CARTO Workflows allows users to visually design their analysis by dragging and dropping components and data sources. The workflow is then automatically compiled into SQL and is pushed down to BigQuery. Users can design, execute, automate, and share sophisticated analytical workflows with all capabilities of BigQuery SQL and its extensions.
You can create and visualize the entire analytics pipeline, execute individual steps and debug, where necessary. Everything created in Workflows is computed natively in BigQuery. The simplicity of the tool enables wider adoption of analytics across teams and faster onboarding, unlocking advanced ML capabilities for a wider cohort of non-expert users.
Unlocking BigQuery ML with CARTO Workflows
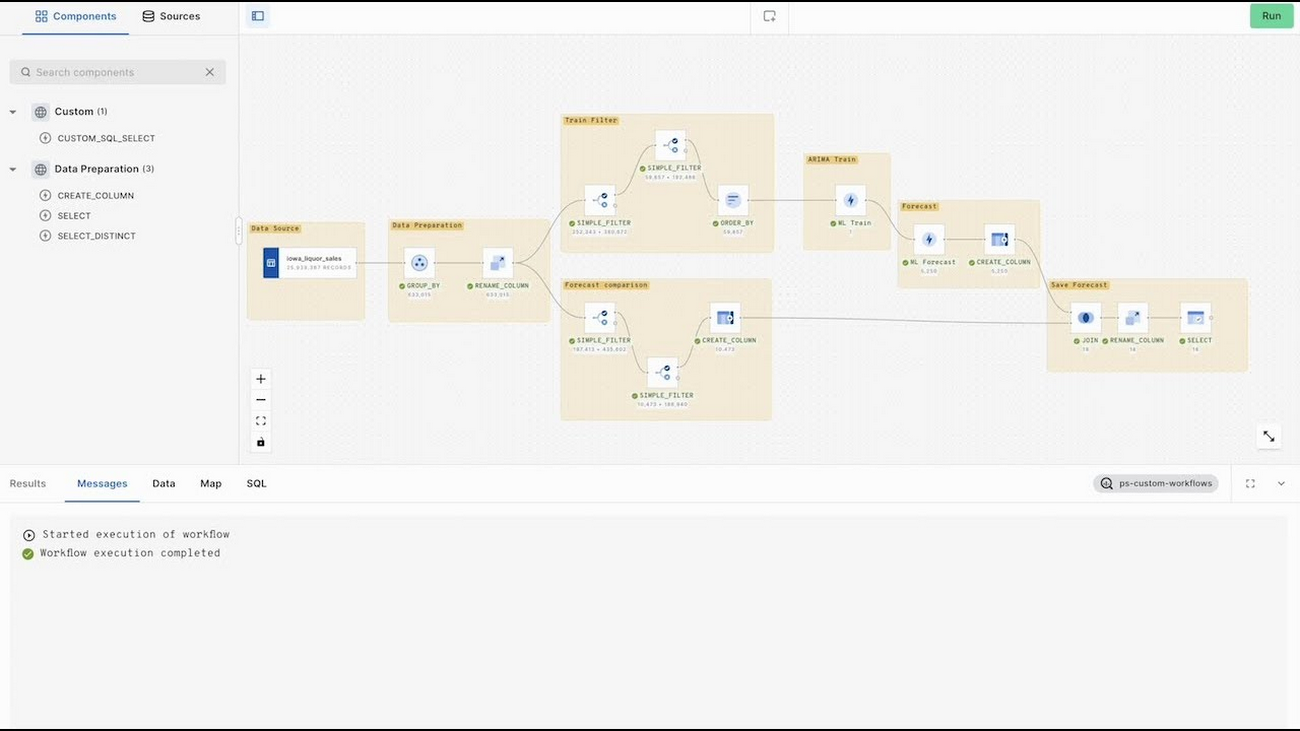
To demonstrate the power of CARTO Workflows and BigQuery, let's take a look at a practical example. In this scenario we will build out a workflow to predict daily store sales for a consumer brand category, using a model based on the ARIMA family available in BigQueryML.
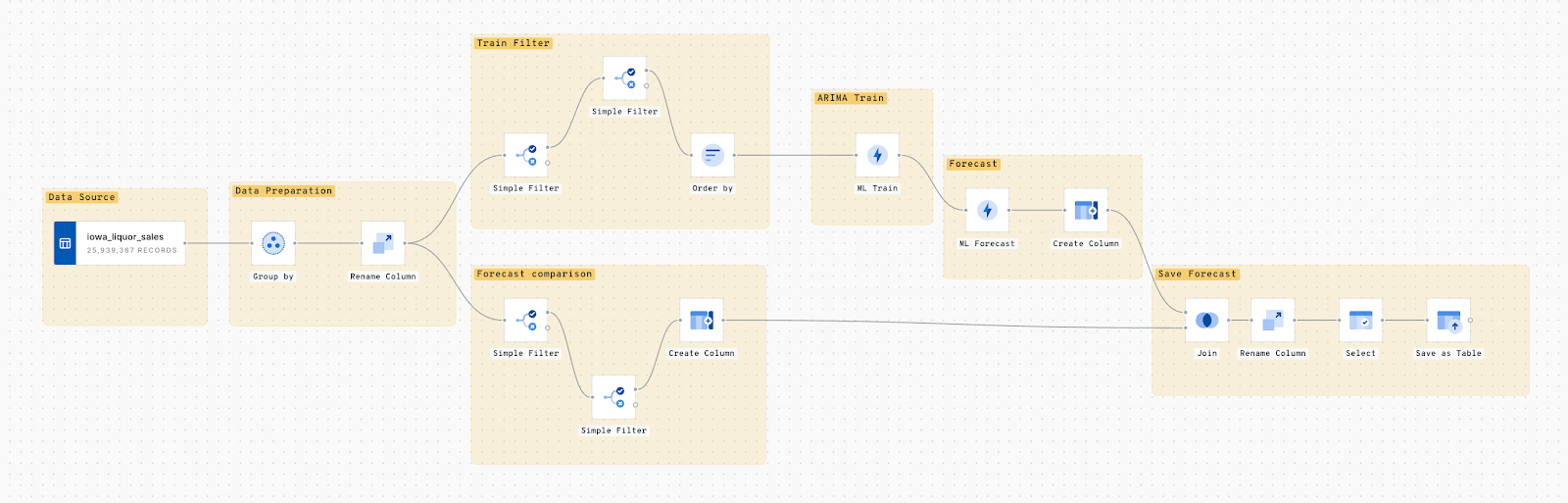
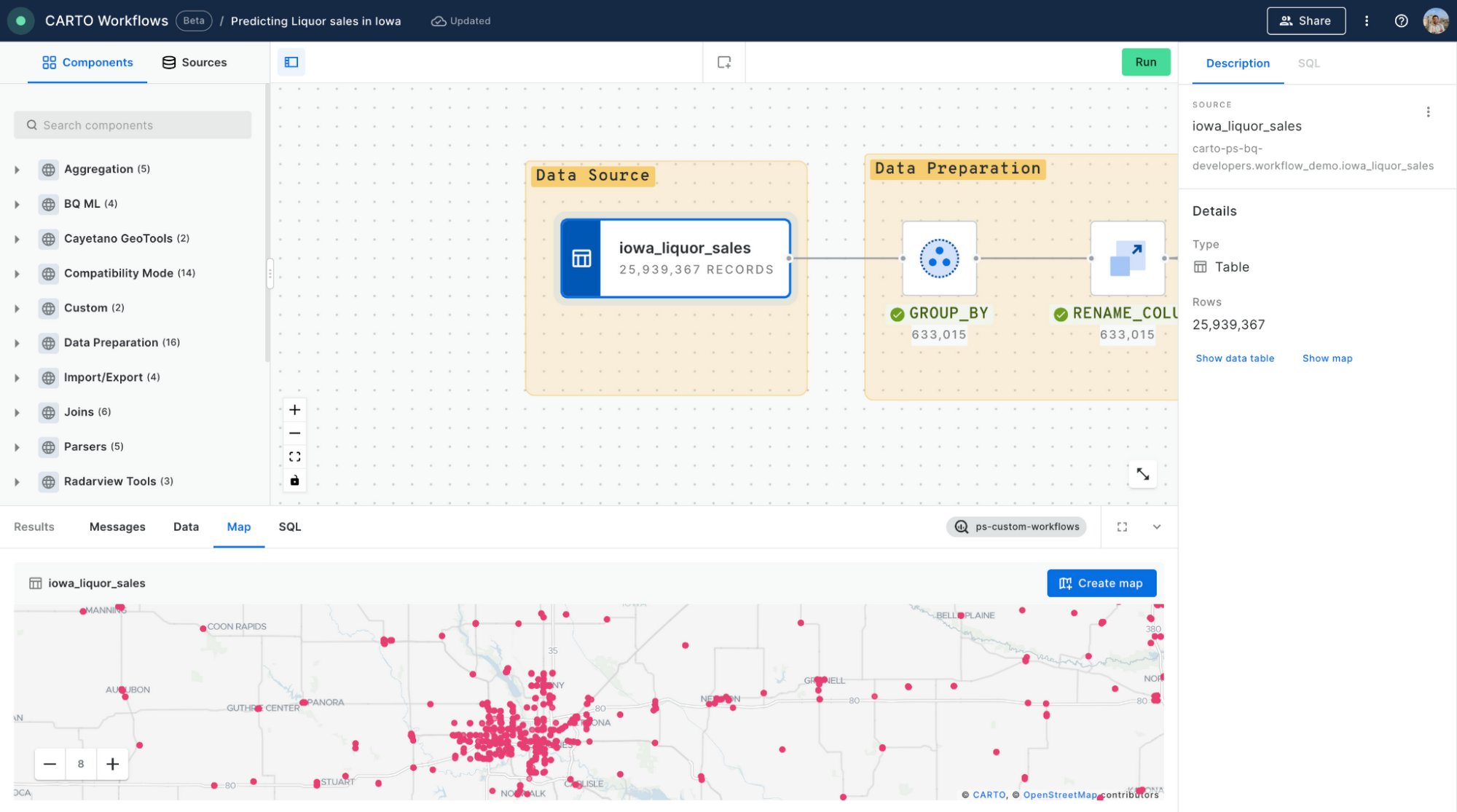
Step 1 - Input Data
For this example, we will be using a publicly available dataset of Liquor sales in the state of Iowa. This dataset can be accessed on the Google Cloud Marketplace here. To replicate this analysis, you can sign up for a free 14-day CARTO trial. With our native connection to BigQuery, we can access this dataset through the CARTO Data Explorer, and simply drag the dataset to the Workflows canvas.
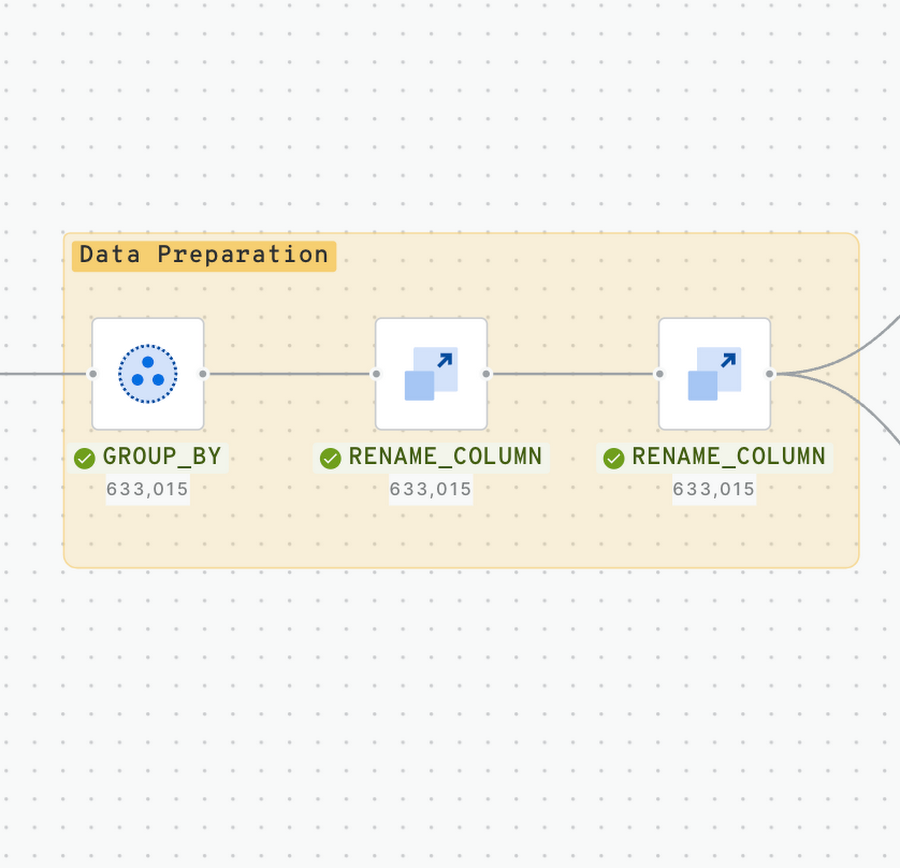
Step 2 - Data Preparation
Since we have all transactions of daily liquor sales, we have to group transactions by store, and by day. The result will give us a single daily sales value for each point of sale.
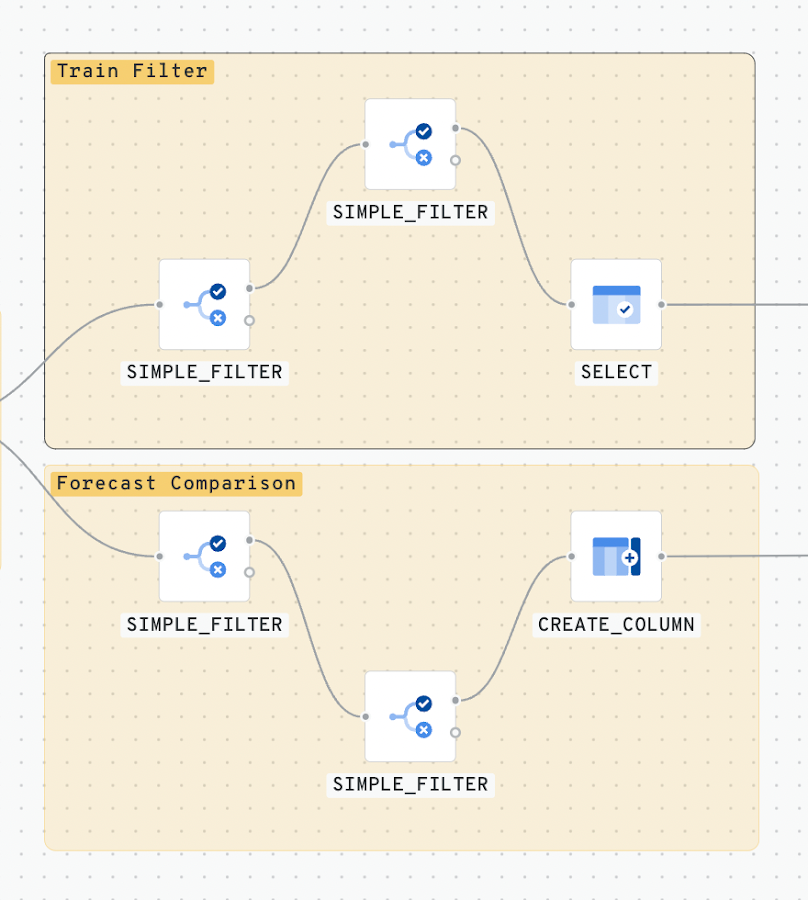
Step 3 - Model Training Filters
The deadline for our model is 2020-06-01. Previous daily data will be used to train our model. To do this we must perform a Simple_Filter. In addition, we are going to predict with a year of historic data, we therefore apply an additional Simple_Filter with the date 2019-06-01.
Then we select the desired columns from the dataset and sort to display only the latest data.
Step 4 - ARIMA Model Training
We have trained the data with an ARIMA model using variables for 1802 stores in a single query, in less than 10 minutes. We use the CREATE_MODEL statement from BigQuery. US holidays have been selected. The frequency is daily and takes into consideration different possible seasonalities. We leave the task of coefficient estimation and parameter selection to BigQueryML. The BigQuery options defined in the workflow are as follows:
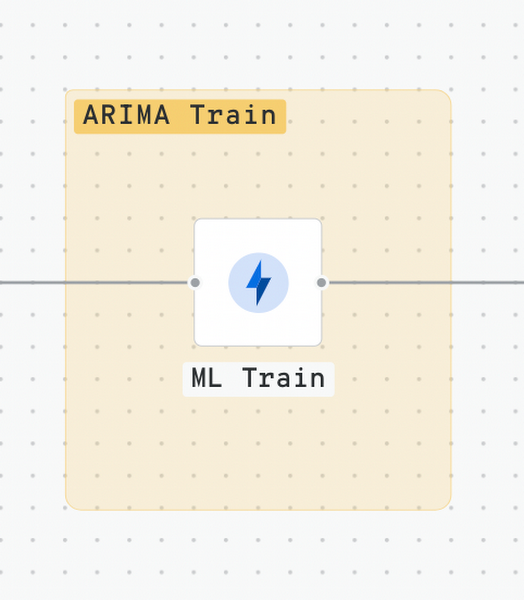
Step 5 - Forecasting
We also use ML.FORECAST to make our daily sales predictions. We can simply pick the inputs for forecast values and also set the confidence interval. This process uses the newly trained model to make future predictions according to the set horizon. We also add a column named index(CONCAT DATE WITH STORE NUMBER). This column will be used to join the forecasted data with its actual values to compare results.
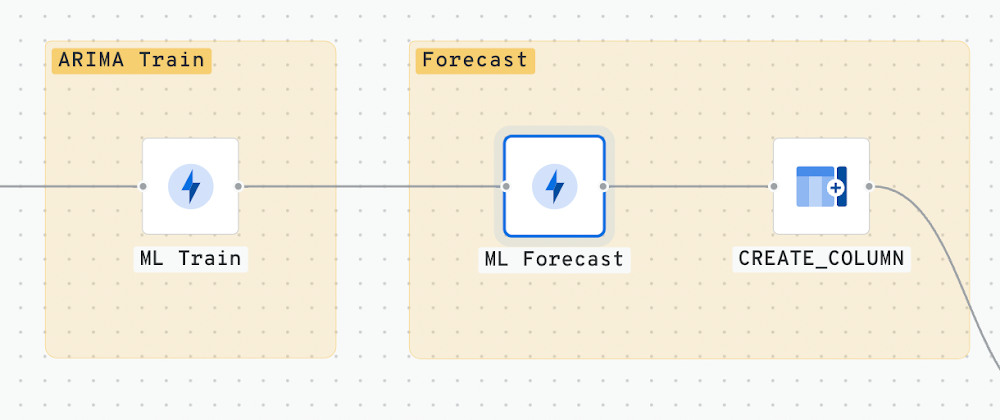
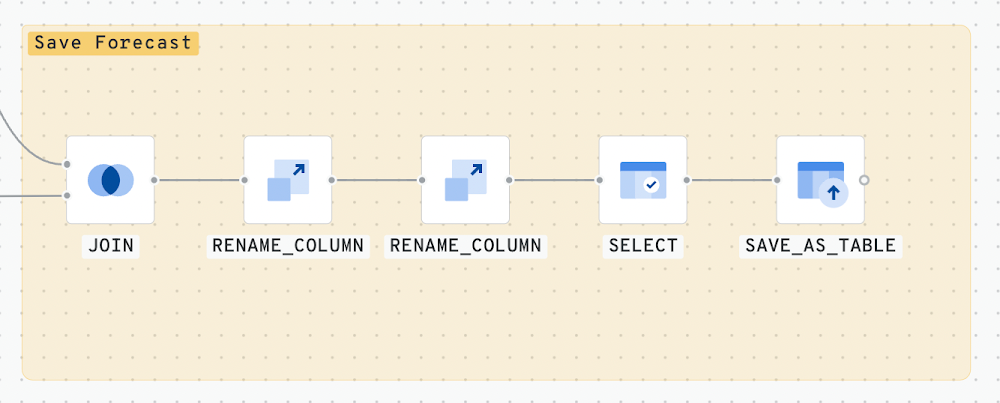
Step 6 - Save the Forecast
In this final step, we save the results of our forecast into a BigQuery table. We can further analyze these results, or visualize the output using CARTO Builder.
To see the complete steps of this workflow in action, check out our video.
BigQuery is leading the analytics space for good reason. It provides a single source of data truth, enabling better data governance, avoiding duplication, and scales automatically based on workload demands. In conjunction with CARTO Workflows and its easy-to-use visual interface, sophisticated data pipelines can be automated to truly democratize the full potential of cloud-native ML capabilities across business units, and for a limitless scope of use cases.
Click here to try out: CARTO Workflows

