Unify analytics with Spark procedures in BigQuery, now generally available
Lu He
Sr. Engineer
Sandeep Karmarkar
Product lead, BigQuery
BigQuery is powered by a highly scalable and capable SQL engine that can handle large data volumes with standard SQL, and that offers advanced capabilities such as BigQuery ML, remote functions, vector search, and more. However, there are cases where you may need to leverage open-source Apache Spark expertise or existing Spark-based business logic to expand BigQuery data processing beyond SQL. For example, you may want to use community packages for complex JSON processing or graph data processing, or use legacy code that was written in Spark prior to migration to BigQuery. Historically, this required you to leave BigQuery, enable a separate API, use an alternative user interface (UI), manage disparate permissions, and pay for non-BigQuery SKUs.
To address these challenges, we developed an integrated experience to extend BigQuery’s data processing to Apache Spark, and today, we are announcing the general availability (GA) of Apache Spark stored procedures in BigQuery. BigQuery users looking to extend their queries with Spark-based data processing can now use BigQuery APIs to create and execute Spark stored procedures. It brings Spark together with BigQuery under a single experience, including management, security and billing. Spark procedures are supported using PySpark, Scala and Java code.
Here’s what DeNA, a provider of internet and AI technologies and a BigQuery customer, had to say
“BigQuery Spark stored procedures deliver a frictionless experience with unified API, governance and billing across Spark and BigQuery. We can now seamlessly use our Spark expertise and community packages for advanced data processing in BigQuery.” - Yusuke Kamo, Division Director, Data Management Division, DeNA Co., Ltd
Let’s look into some key aspects of this unified experience.
Develop, test, and deploy PySpark code in BigQuery Studio
BigQuery Studio, a single, unified interface for all data practitioners, includes a Python editor to develop, test and deploy your PySpark code. Procedures can be configured with IN/OUT parameters along with other options. After you create a Spark connection you can iteratively test the code within the UI. For debugging and troubleshooting, the BigQuery console incorporates log messages from underlying Spark jobs and surfaces those within the same context. Spark experts can also tune Spark execution by passing Spark parameters to the procedure.
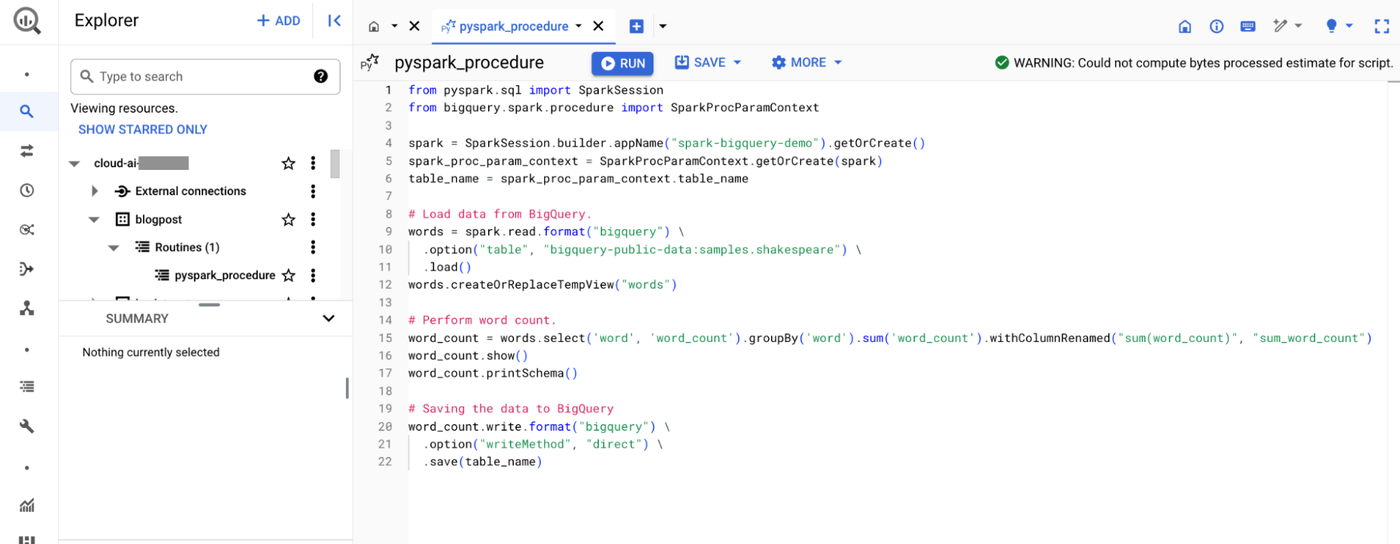
Author PySpark procedure with a Python editor in BigQuery Studio
Once tested, the procedure is stored within a BigQuery dataset and access to the procedure can be managed similarly to your SQL procedures.
Extend for advanced use cases
One of the great benefits of Apache Spark is being able to take advantage of a wide range of community or third-party packages. You can configure Spark stored procedures in BigQuery to install packages that you need for your code execution.
For advanced use cases you can also import your code stored in Google Cloud Storage buckets or a custom container image that is available in Container Registry or Artifact Registry.
Advanced security and authentication options like customer-managed encryption keys (CMEK) and using a pre-existing service account are also supported.
Serverless execution with BigQuery billing
With this release, you enjoy the benefits of Spark within the BigQuery APIs and only see BigQuery charges. Behind the scenes, this is made possible by our industry leading Serverless Spark engine that enables serverless, autoscaling Spark. However, you don’t need to enable Dataproc APIs or be charged for Dataproc when you leverage this new capability. You will be charged for Spark procedures usage using the Enterprise edition (EE) pay-as-you-go (PAYG) pricing SKU. This feature is available in all the BigQuery editions, including the on-demand model. You will get charged for Spark procedures with EE PAYG SKU irrespective of the editions. Please see BigQuery pricing for more details.
Next steps
Learn more about Apache Spark stored procedures in the BigQuery documentation.

