3x Dataflow Throughput with Auto Sharding for BigQuery
Siyuan Chen
Software Engineer, Google Cloud
Shanmugam (Shan) Kulandaivel
Product Manager, Streaming Analytics, Google Cloud
Many of you rely on Dataflow to build and operate mission critical streaming analytics pipelines. A key goal for us, the Dataflow team, is to make the technology work for users rather than the other way around. Autotuning, as a fundamental value proposition Dataflow offers, is a key part of making that goal a reality - it helps you focus on your use cases by eliminating the cost and burden of having to constantly tune and re-tune your applications as circumstances change. Dataflow already includes many autotuning capabilities and we are excited to announce a new capability today that further simplifies streaming data pipelines.
Google BigQuery is one of the most common storage systems that Dataflow Streaming pipelines export results to. The Beam SDKs include built-in transforms, known as BigQuery I/O connector, that can read data from and write data to BigQuery tables. While the write transform has been optimized to take advantage of various BigQuery capabilities (e.g dynamic destinations), currently Dataflow relies on users to manually configure numFileShards or numStreamingKeys to parallelize BigQuery writes. This is painful for customers because it is extremely challenging to get the configuration right and requires a lot of manual efforts to maintain it.
Current Challenges
Manually selecting an optimal number of shards is a very hard problem and results in following issues:
Too low a sharding value leads to insufficient execution parallelism and therefore limited throughput.
Too high a sharding value leads to increased overhead (both on the Dataflow side and BigQuery side) which risks diminishing returns. In some cases, pipeline throughput drops further if it exceeds BigQuery quotas and limits due to high sharding.
The fundamental issue here is that one size does not fit all: Sharding for one shape of the data may not be the right choice when circumstances change (e.g. when the volume changes or when there are “hot spots” with much more volume than the others).
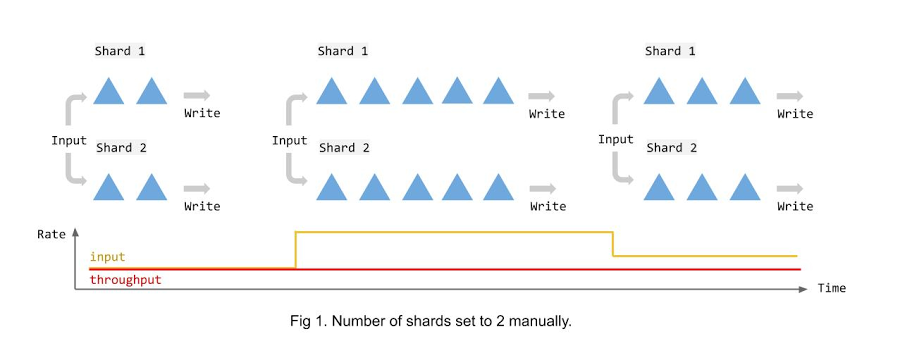
The following illustration shows what happens with manual fixed sharding when streaming data to a BigQuery table. As you can see, irrespective of the volume of data, the number of shards remains constant and becomes insufficient when the input rate bumps. As a result of this configuration, the throughput remains constant over time irrespective of the changing volume of data. Adding more worker nodes than the shards could hardly be helpful in this case.
Introducing Auto Sharding for BigQuery
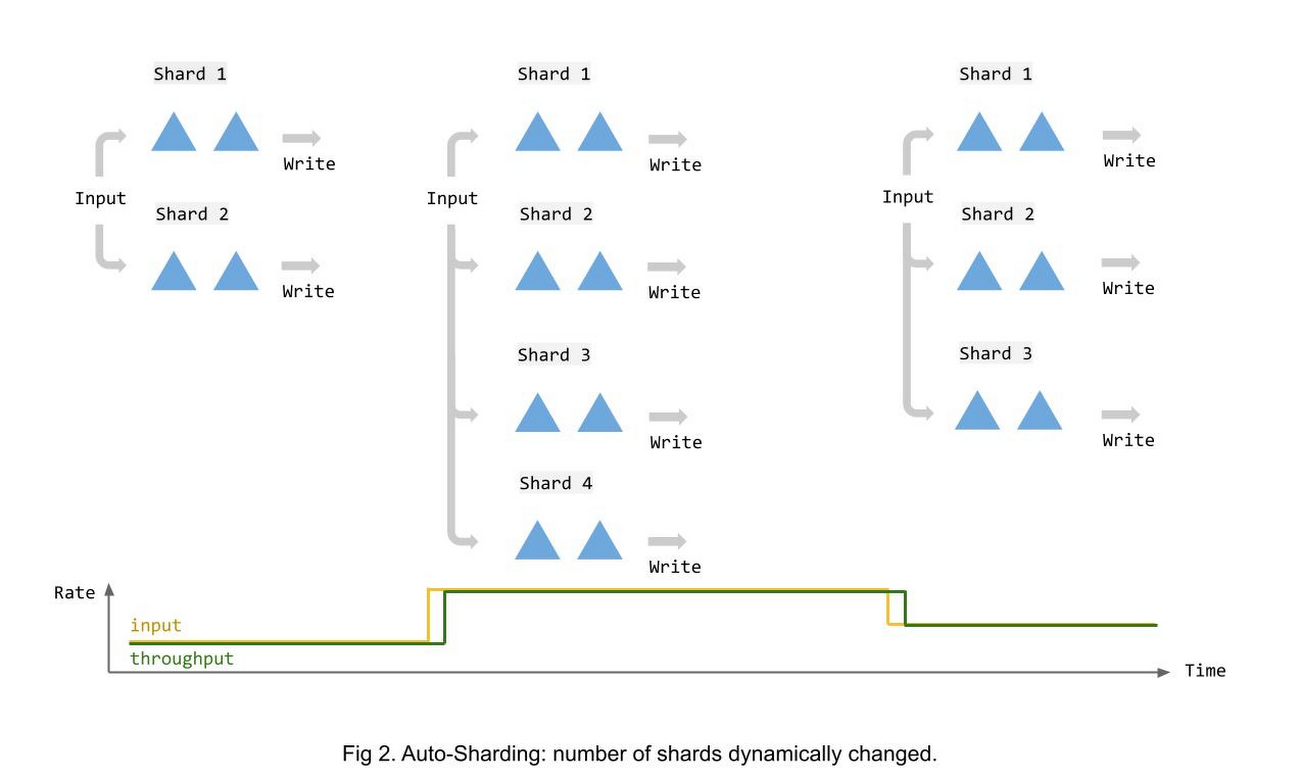
In order to eliminate the painful hand-tuning of parallelism for the BigQuery sink, we are introducing a new capability, Auto Sharding, to Dataflow Streaming Engine. With Auto Sharding, Dataflow dynamically adjusts the number of shards for BigQuery writes and balances the load to keep up with the input rate.
The following illustration shows how sharding changes over time in response to changing input data volume.
Benefits
To determine the extent of the benefit, we ran load tests to compare the performance of BigQuery I/O connector with and without Auto Sharding. To get a comprehensive understanding of the performance benefits, we compared the throughput for worker counts ranging from 5 to 150.
As you can see in the following charts, Auto Sharding outperformed manual (and fixed) sharding with BigQuery streaming inserts. It boosted the throughput by 2x to 3x in most cases without any other changes. In general, increase in throughput per worker has the potential to reduce the number of workers needed, and thereby cost.
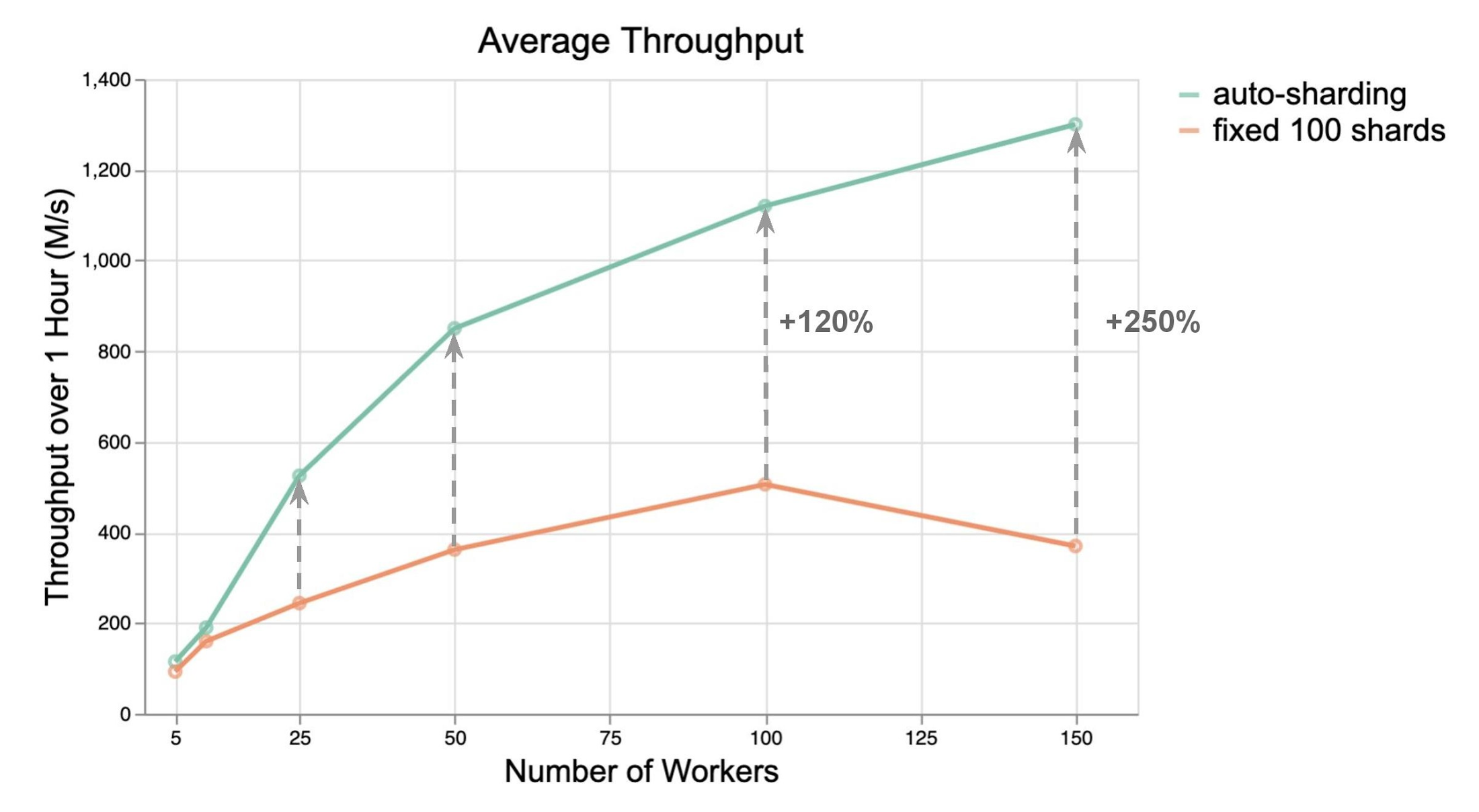
The difference in throughput increases as the number of workers is increased. This is particularly important since it becomes very challenging to hand pick sharding configuration as the scale of your pipeline grows in order to handle increased input volume.
Streaming Auto Sharding also works with BigQuery batch loading of data and yields similar improvements - 160% to 260% increase in throughput.
How to enable Auto Sharding for BigQuery Sinks
You can enable Auto Sharding in Streaming Engine by setting a new option when configuring the BigQuery I/O connector in your code. The option is available in both streaming inserts and file loads modes starting Beam 2.29.0 for Java and Beam 2.30.0 for Python. Alternatively, you can opt in Auto Sharding for streaming inserts using Beam 2.28.0 Java SDK with an additional Dataflow experiment --experiments=enable_streaming_auto_sharding.
The following are code samples to enable Auto Sharding.
Java:
Python:
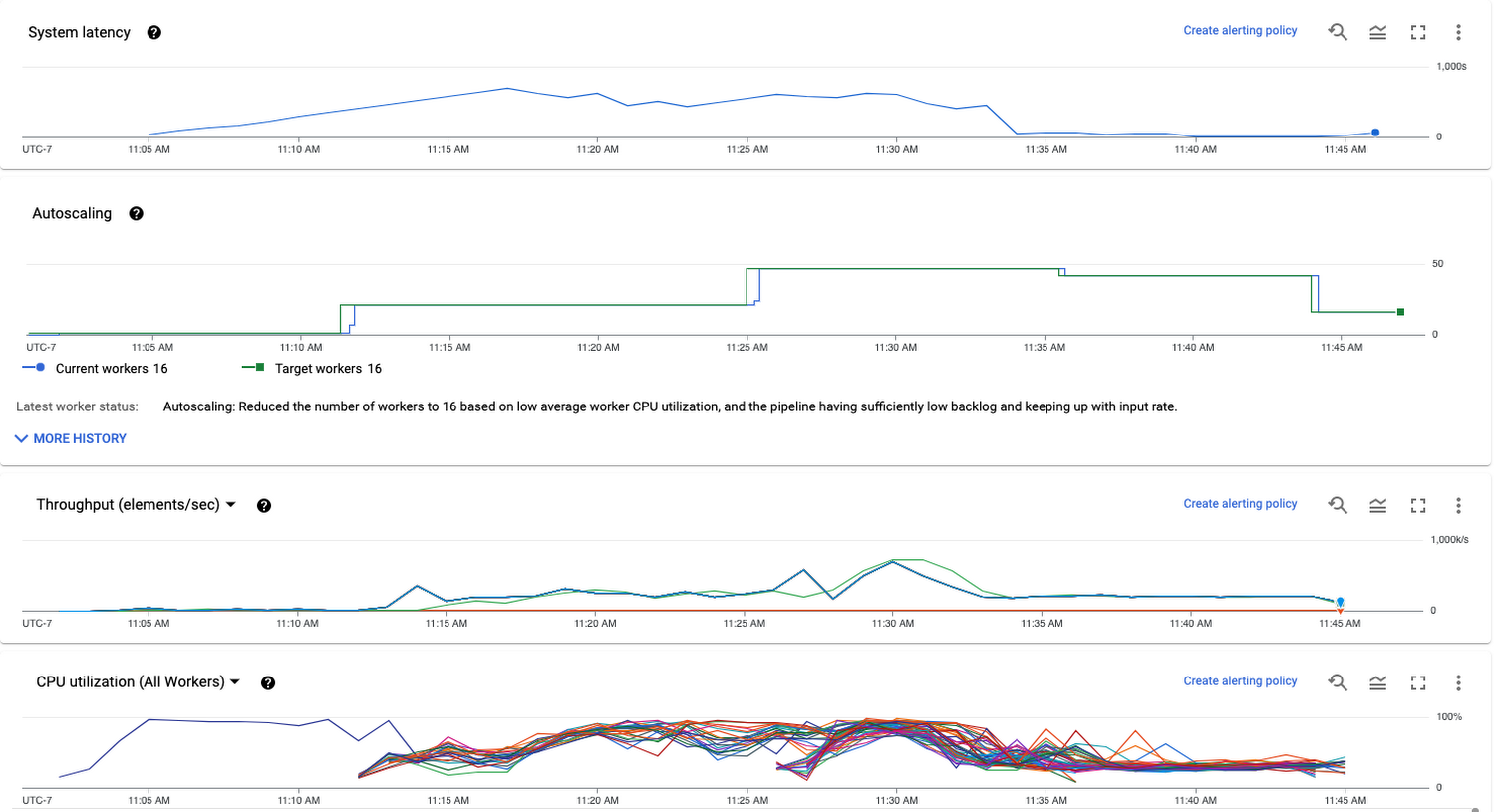
With the new option, the sharding for the BigQuery writes will be automatically determined at runtime to make the best use of workers available. If autoscaling is turned on, sharding will be adjusted to keep all workers busy when the number of workers changes. While the number of shards is not explicitly exposed, the changes in sharding is reflected in job metrics such as data freshness and throughput.
For example, increased system latency triggers more workers which in turn increases the number of shards. As a result throughput increases and the backlog is cleared faster. You can use the Dataflow Console to monitor the number of workers and the throughput of the BigQuery write stage:
To get started, please refer to the documentation for the BigQuery IO Connector and the introduction page to learn more about different ways of data ingestion to BigQuery and how to choose one that fits your needs.

