4 ways to reduce cold start latency on Google Kubernetes Engine
Tao He
Software Engineer
Winston Chiang
Product Manager
If you run workloads on Kubernetes, chances are you’ve experienced a “cold start”: a delay in launching an application that happens when workloads are scheduled to nodes that haven’t hosted the workload before and the pods need to spin up from scratch. The extended startup time can lead to longer response times and a worse experience for your users — especially when the application is autoscaling to handle a surge in traffic.
What’s going on during a cold start? Deploying a containerized application on Kubernetes typically involves several steps, including pulling container images, starting containers, and initializing the application code. These processes all add to the time before a pod can start serving traffic, resulting in increased latency for the first requests served by a new pod. The initial startup time can be significantly longer because the new node has no pre-existing container image. For subsequent requests, the pod is already up and warm, so it can quickly serve requests without extra startup time.
Cold starts are frequent when pods are continuously being shut down and restarted, as that forces requests to be routed to new, cold pods. A common solution is to keep warm pools of pods ready to reduce the cold start latency.
However, with larger workloads like AI/ML, and especially on expensive and scarce GPUs, the warm pool practice can be very costly. So cold starts are especially prevalent for AI/ML workloads, where it’s common to shut down pods after completed requests.
Google Kubernetes Engine (GKE) is Google Cloud’s managed Kubernetes service, and can make it easier to deploy and maintain complex containerized workloads. In this post, we’ll discuss four different techniques to reduce cold start latency on GKE, so you can deliver responsive services.
Techniques to overcome the cold start challenge
Use ephemeral storage with local SSDs or larger boot disks
Nodes mount the Kubelet and container runtime (docker or containerd) root directories on a local SSD. As a result, the container layer is backed by the local SSD, with the IOPS and throughput documented on About local SSDs. This is usually more cost-effective than increasing the PD size.
The following table compares the options and demonstrates that for the same cost, LocalSSD has ~3x more throughput than PD, allowing the image pull to run faster and reduce the workload’s startup latency.
You can create a node pool that uses ephemeral storage with local SSDs in an existing cluster running on GKE version 1.25.3-gke.1800 or later.
For more, see Provision ephemeral storage with local SSDs.
2. Enable container image streaming
Image streaming can allow workloads to start without waiting for the entire image to be downloaded, leading to significant improvements in workload startup time. For example, with GKE image streaming, the end-to-end startup time (from workload creation to server up for traffic) for an NVIDIA Triton Server (5.4GB container image) can be reduced from 191s to 30s.
You must use Artifact Registry for your containers and meet the requirements. Image Streaming can be enabled on the cluster by
To learn more, see Use Image streaming to pull container images.
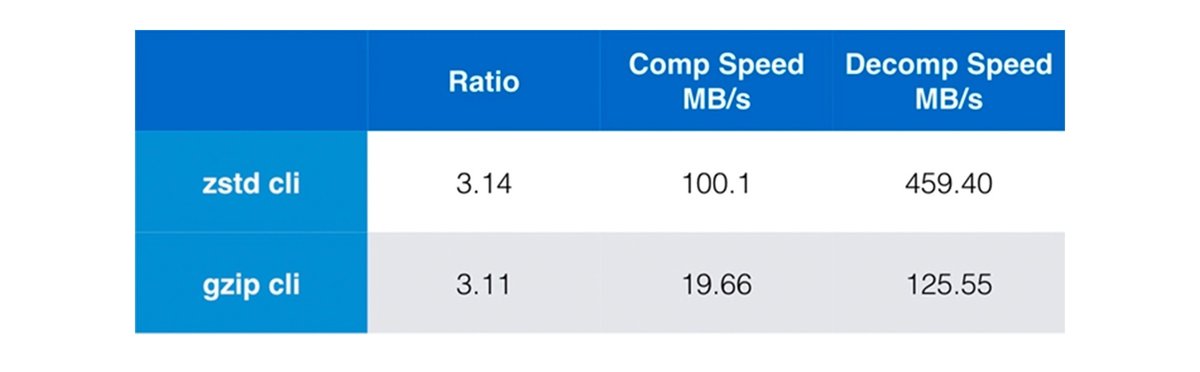
3. Use Zstandard compressed container images
Zstandard compression is a feature supported in ContainerD. Zstandard benchmark shows zstd is >3x faster decompression than gzip (the current default).
Here’s how to use the zstd builder in docker buildx:
Here’s how to build and push an image:
Please note that Zstandard is not required with image streaming. If your application requires the majority of the container image content to be loaded before starting, you may choose to use Zstandard without image streaming. Otherwise, try image streaming.
4. Use a preloader DaemonSet to preload the base container on nodes
Last but not least, ContainerD reuses the image layers across different containers if they share the same base container. And the preloader DaemonSet can start running even before the GPU driver is installed (driver installation takes ~30 seconds). That means it can preload required containers before the GPU workload can be scheduled to the GPU node and start pulling images ahead of time.
Below is an example of the preloader DaemonSet.
Outsmarting the cold start
The cold start challenge is a common problem in container orchestration systems. With careful planning and optimization, you can mitigate its impact on your applications running on GKE. By using ephemeral storage with larger boot disks, enabling container streaming or Zstandard compression, and preloading the base container with a daemonset, you can reduce cold start delays and ensure a more responsive and efficient system. To learn more about GKE, check out the user guide.
