Using GKE and applying DevOps principles for scientific research at Stanford
Paul Nuyujukian
Departments of Bioengineering, Neurosurgery, and Electrical Engineering, Stanford University
Volker Eyrich
Practice Lead, Google Cloud
Editor’s note: Stanford University Assistant Professor Paul Nuyujukian and his team at the Brain Inferencing Laboratory explore motor systems neuroscience and neuroengineering applications as part of an effort to create brain-machine interfaces for medical conditions such as stroke and epilepsy. This blog explores how the team is using Google Cloud data storage, computing and analytics capabilities to streamline the collection, processing, and sharing of that scientific data, for the betterment of science and to adhere to funding agency regulations.
Scientific discovery, now more than ever, depends on large quantities of high-quality data and sophisticated analyses performed on those data. In turn, the ability to reliably capture and store data from experiments and process them in a scalable and secure fashion is becoming increasingly important for researchers. Furthermore, collaboration and peer-review are critical components of the processes aimed at making discoveries accessible and useful across a broad range of audiences.
The cornerstones of scientific research are rigor, reproducibility, and transparency — critical elements that ensure scientific findings can be trusted and built upon [1]. Recently, US Federal funding agencies have adopted strict guidelines around the availability of research data, and so not only is leveraging data best practices practical and beneficial for science, it is now compulsory [2, 3, 4, 5]. Fortunately, Google Cloud provides a wealth of data storage, computing and analytics capabilities that can be used to streamline the collection, processing, and sharing of scientific data.
Prof. Paul Nuyujukian and his research team at Stanford’s Brain Inferencing Laboratory explore motor systems neuroscience and neuroengineering applications. Their work involves studying how the brain controls movement, recovers from injury, and work to establish brain-machine interfaces as a platform technology for a variety of brain-related medical conditions, particularly stroke and epilepsy. The relevant data is obtained from experiments on preclinical models and human clinical studies. The raw experimental data collected in these experiments is extremely valuable and virtually impossible to reproduce exactly (not to mention the potential costs involved).
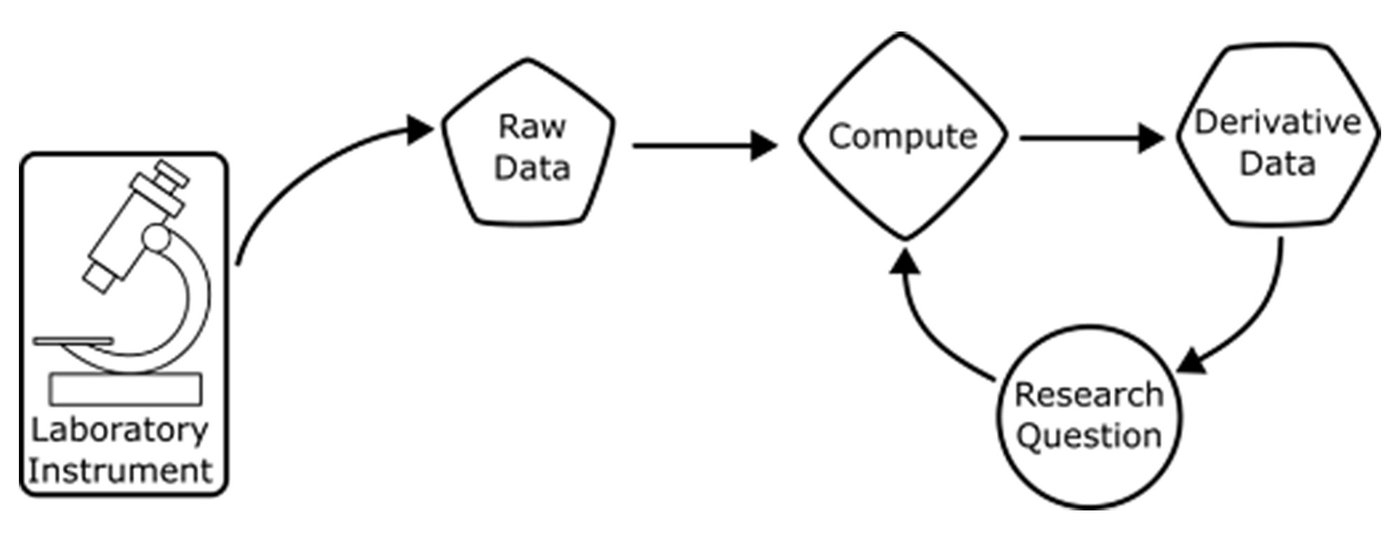
Fig. 1: Schematic representation of a scientific computation workflow
To address the challenges outlined above, Prof. Nuyujukian has developed a sophisticated data collection and analysis platform that is in large part inspired by the practices that make up the DevOps approach common in software development [6, Fig. 2]. Keys to the success of this system are standardization, automation, repeatability and scalability. The platform allows for both standardized analyses and “one-off” or ad-hoc analyses in a heterogeneous computing environment. The critical components of the system are containers, Git, CI/CD (leveraging GitLab Runners), and high-performance compute clusters, both on-premises and in cloud environments such as Google Cloud, in particular Google Kubernetes Engine (GKE) running in Autopilot mode.

Fig. 2: Leveraging DevOps for Scientific Computing
Google Cloud provides a secure, scalable, and highly interoperable framework for the various analyses that need to be run on the data collected from scientific experiments (spanning basic science and clinical studies). GitLab Pipelines specify the transformations and analyses that need to be applied to the various datasets. GitLab Runner instances running on GKE (or other on-premises cluster/high-performance computing environments) are used to execute these pipelines in a scalable and cost-effective manner. Autopilot environments in particular provide substantial advantages to researchers since they are fully managed and require only minimal customization or ongoing “manual” maintenance. Furthermore, they instantly scale with the demand for analyses that need to be run, even with spot VM pricing, allowing for cost-effective computation. Then, they scale down to near-zero when idle, and scale up as demand increases again – all without intervention by the researcher.
GitLab pipelines have a clear and well-organized structure defined in YAML files. Data transformations are often multi-stage and GitLab’s framework explicitly supports such an approach. Defaults can be set for an entire pipeline, such as the various data transformation stages, and can be overwritten for particular stages where necessary. Since the exact steps of a data transformation pipeline can be context- or case-dependent, conditional logic is supported along with dynamic definition of pipelines, e.g., definitions depending on the outcome of previous analysis steps. Critically, different stages of a GitLab pipeline can be executed by different runners, facilitating the execution of pipelines across heterogeneous environments, for example transferring data from experimental acquisition systems and processing them in cloud or on-premises computing spaces [Fig. 3].
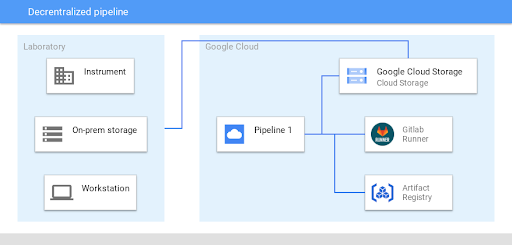
Fig. 3: Architecture of the Google Cloud based scientific computation workflow via GitLab Runners hosted on Google Kubernetes Engine
Cloud computing resources can provide exceptional scalability, while pipelines allow for parallel execution of stages to take advantage of this scalability, allowing researchers to execute transformations at scale and substantially speed up data processing and analysis. Parametrization of pipelines allows researchers to automate the validation of processing protocols across many acquired datasets or analytical variations, yielding robust, reproducible, and sustainable data analysis workflows.
Collaboration and data sharing is another critical, and now mandatory, aspect of scientific discovery. Multiple generations of researchers, from the same lab or different labs, may interact with particular datasets and analysis workflows over a long period of time. Standardized pipelines like the ones described above can play a central role in providing transparency on how data is collected and how it is processed, since they are essentially self-documenting. That, in turn, allows for scalable and repeatable discovery. Data provenance, for example, is explicitly supported by this framework. Through the extensive use of containers, workflows are also well encapsulated and no longer depend on specifically tuned local computing environments. This consequently leads to increased rigor, reproducibility and transparency, enabling a large audience to interact productively with datasets and data transformation workflows.
In conclusion, by using the computing, data storage, and transformation technologies available from Google Cloud along with workflow capabilities of CI/CD engines like GitLab, researchers can build highly capable and cost-effective scientific data-analysis environments that aid efforts to increase rigor, reproducibility, and transparency, while also achieving compliance with relevant government regulations.
References:
