5 best practices for Managed Lustre on Google Kubernetes Engine
Nishtha Jain
Engineering Manager
Dan Eawaz
Senior Product Manager
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowGoogle Kubernetes Engine (GKE) is a powerful platform for orchestrating scalable AI and high-performance computing (HPC) workloads. But as clusters grow and jobs become more data-intensive, storage I/O can become a bottleneck. Your powerful GPUs and TPUs can end up idle, while waiting for data, driving up costs and slowing down innovation.
Google Cloud Managed Lustre is designed to solve this problem. Many on-premises HPC environments already use parallel file systems, and Managed Lustre makes it easier to bring those workloads to the cloud. With its managed Container Storage Interface (CSI) driver, Managed Lustre and GKE operations are fully integrated.
Optimizing your move to a high-performance parallel file system can help you get the most out of your investment from day one.
Before deploying, it's helpful to know when to use Managed Lustre versus other options like Google Cloud Storage. For most AI and ML workloads, Managed Lustre is the recommended solution. It excels in training and checkpointing scenarios that require very low latency (less than a millisecond) and high throughput for small files, which keeps your expensive accelerators fully utilized. For data archiving or workloads with large files (over 50 MB) that can tolerate higher latency, Cloud Storage FUSE with Anywhere Cache can be another choice.
Based on our work with early customers and the learnings from our teams, here are five best practices to ensure you get the most out of Managed Lustre on GKE.
1. Design for data locality
For performance-sensitive applications, you want your compute resources and storage to be as close as possible, ideally within the same zone in a given region. When provisioning volumes dynamically, the volumeBindingMode parameter in your StorageClass is your most important tool. We strongly recommend setting it to WaitForFirstConsumer. GKE provides a built-in StorageClass for Managed Lustre that uses WaitForFirstConsumer binding mode by default.
Generated yaml:
Why it’s a best practice: Using WaitForFirstConsumer instructs GKE to delay the provisioning of the Lustre instance until a pod that needs it is scheduled. The scheduler then uses the pod's topology constraints (i.e., the zone it's scheduled in) to create the Lustre instance in that exact same zone. This guarantees co-location of your storage and compute, minimizing network latency.
2. Right-size your performance with tiers
Not all high-performance workloads are the same. Managed Lustre offers multiple performance tiers (read and write throughput in MB/s per TiB of storage) so you can align cost directly with your performance requirements.
-
1000 & 500 MB/s/TiB: Ideal for throughput-critical workloads like foundation model training or large-scale physics simulations where I/O bandwidth is the primary bottleneck.
-
250 MB/s/TiB: A balanced, cost-effective tier great for many general HPC workloads and AI inference serving, and data-heavy analytics pipelines.
-
125 MB/s/TiB: Best for large-capacity use cases where having a massive, POSIX-compliant file system is more important than achieving peak throughput. This is also useful for migrating on-premises containerized applications without modification, making it easier to migrate on-premises workloads to the cloud storage.
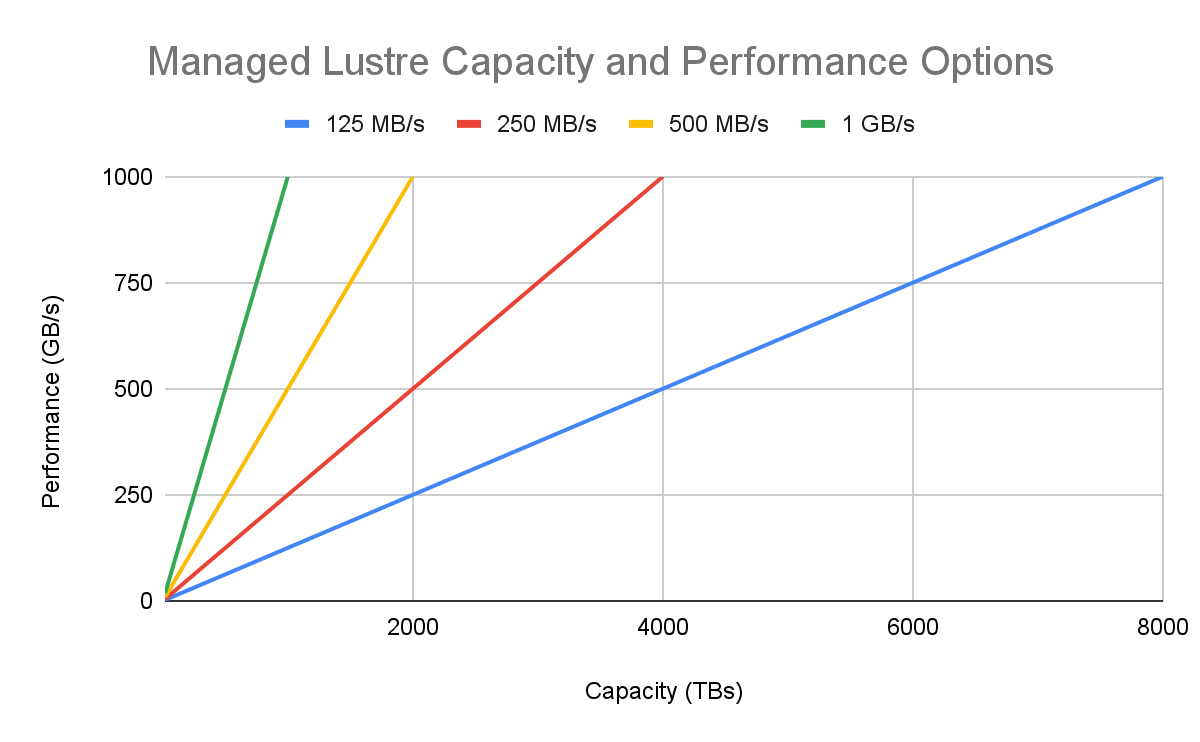
Why it’s a best practice: Defaulting to the highest tier isn't always the most cost-effective strategy. By analyzing your workload’s I/O profile, you can significantly optimize your total cost of ownership.
3. Master your networking foundation
A parallel file system is a network-attached resource. Getting the networking right up front will save you days of troubleshooting. Before provisioning, ensure your VPC is correctly configured by following the setup steps in our documentation. This involves three key steps detailed in our documentation:
-
Enable Service Networking.
-
Create an IP range for VPC peering.
-
Create a firewall rule to allow traffic from that range on the Lustre network port (TCP 988 or 6988).
Why it’s a best practice: This is a one-time setup per VPC that establishes the secure peering connection that allows your GKE nodes to communicate with the Managed Lustre service.
4. Use dynamic provisioning for simplicity, static for long-lived shared data
The Managed Lustre CSI driver supports two modes for connecting storage to your GKE workloads.
-
Dynamic provisioning: Use when your storage is tightly coupled to the lifecycle of a specific workload or application. By defining a StorageClass and PersistentVolumeClaim (PVC), GKE will automatically manage the Lustre instance lifecycle for you. This is the simplest, most automated approach.
-
Static provisioning: Use when you have a long-lived Lustre instance that needs to be shared across multiple GKE clusters and jobs. You create the Lustre instance once, then create a PersistentVolume (PV) and PVC in your cluster to mount it. This decouples the storage lifecycle from any single workload.
Why it’s a best practice: Thinking about your data’s lifecycle helps you choose the right pattern. Use dynamic provisioning as your default because of simplicity, and opt for static provisioning when you need to treat your file system as a persistent, shared resource across your organization.
5. Architecting for parallelism with Kubernetes Jobs
Many AI and HPC tasks, like data preprocessing or batch inference, are suited for parallel execution. Instead of running a single, large pod, use the Kubernetes Job resource to divide the work across many smaller pods.
Consider this pattern:
-
Create a single PersistentVolumeClaim for your Managed Lustre instance, making it available to your cluster.
-
Define a Kubernetes job with parallelism set to a high number (e.g., 100).
-
Each pod created by the Job mounts the same Lustre PVC.
-
Design your application so that each pod works on a different subset of the data (e.g., processing a different range of files or data chunks).
Why it’s a best practice: In this pattern, you create a single PVC for your Lustre instance and have each pod created by the Job mount that same PVC. By designing your application so that each pod works on a different subset of the data, you turn your GKE cluster into a powerful, distributed data processing engine. The GKE Job controller acts as the parallel task orchestrator, while Managed Lustre serves as the high-speed data backbone, allowing you to achieve massive aggregate throughput.
Get started today
By combining the orchestration power of GKE with the performance of Managed Lustre, you can build a truly scalable and efficient platform for AI and HPC. Following these best practices will help you create a solution that is not only powerful, but also efficient, cost-effective, and easy to manage.
Ready to get started? Explore the Managed Lustre documentation, and provision your first instance today.
