Understanding IP address management in GKE
Mahesh Narayanan
Senior Product Manager
Sudeep Modi
Software Engineer
When it comes to giving out IP addresses, Kubernetes has a supply and demand problem. On the supply side, organizations are running low on IP addresses, because of large on-premises networks and multi-cloud deployments that use RFC1918 addresses (address allocation for private internets). On the demand side, Kubernetes resources such as pods, nodes and services each require an IP address. This supply and demand challenge has led to concerns of IP address exhaustion while deploying Kubernetes. Additionally, managing these IP addresses involves a lot of overhead, especially in cases where the team managing cloud architecture is different from the team managing the on-prem network. In this case, the cloud team often has to negotiate with the on-prem team to secure unused IP blocks.
There’s no question that managing IP addresses in a Kubernetes environment can be challenging. While there’s no silver bullet for solving IP exhaustion, Google Kubernetes Engine (GKE) offers ways to solve or work around this problem.
For example, Google Cloud partner NetApp relies heavily on GKE and its IP address management capabilities for users of its Cloud Volumes Service file service.
“NetApp’s Cloud Volumes Service is a flexible, scalable, cloud-native file service for our customers,” said Rajesh Rajaraman, Senior Technical Director at NetApp. “GKE gives us the flexibility to take advantage of non-RFC IP addresses and we can provide scalable services seamlessly without asking our customers for additional IPs,” Google Cloud and GKE enable us to create a secure SaaS offering and scale alongside our customers.”
Since IP addressing in itself is a rather complex topic and the subject of many books and web articles, this blog assumes you are familiar with the basics of IP addressing. So without further ado, let’s take a look at how IP addressing works in GKE, some common IP addressing problems and GKE features to help you solve them. The approach you take will depend on your organization, your use cases, applications, skill sets, and whether or not there’s an IP Address Management (IPAM) solution in place.
IP address management in GKE
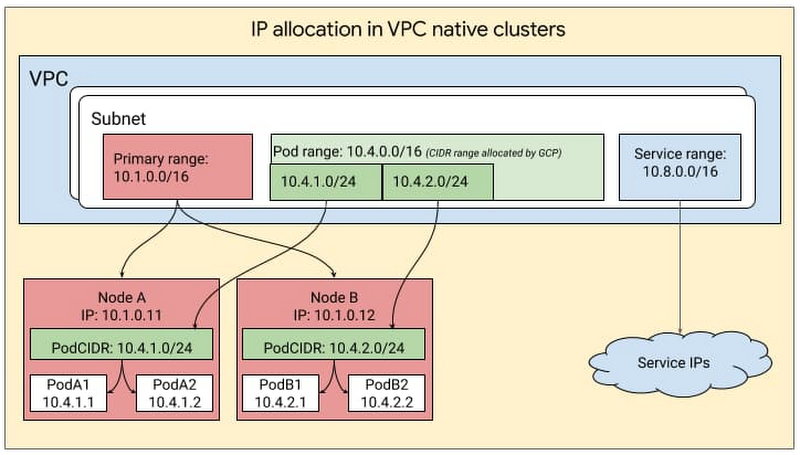
GKE leverages the underlying GCP architecture for IP address management, creating clusters within a VPC subnet and creating secondary ranges for Pods (i.e., pod range) and services (service range) within that subnet. The user can provide the ranges to GKE while creating the cluster or let GKE create them automatically. IP addresses for the nodes come from the IP CIDR assigned to the subnet associated with the cluster. The pod range allocated to a cluster is split up into multiple sub-ranges—one for each node. When a new node is added to the cluster, GCP automatically picks a sub-range from the pod-range and assigns it to the node. When new pods are launched on this node, Kubernetes selects a pod IP from the sub-range allocated to the node. This can be visualized as follows:
Provisioning flexibility
In GKE, you can obtain this IP CIDR either in one of two ways: by defining a subnet and then mapping it to the GKE cluster, or by auto-mode where you let GKE pick a block automatically from the specific region.
If you’re just starting out, run exclusively on Google Cloud and would just like Google Cloud to do IP address management on your behalf, we recommend auto-mode. On the other hand, if you have a multi-environment deployment, have multiple VPCs and would like control over IP management in GKE, we recommend using custom-mode, where you can manually define the CIDRs that GKE clusters use.
Flexible Pod CIDR functionality
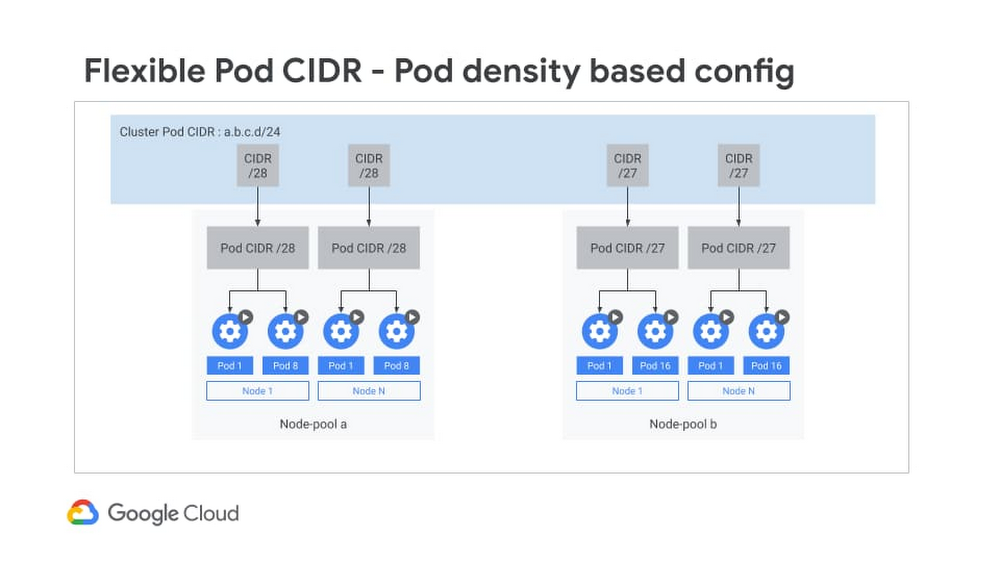
Next, let’s look at IP address allocation for Pods. By default, Kubernetes assigns a /24 subnet mask on a per node basis for Pod IP assignment. However, more than 95% of GKE clusters are created with no more than 30 Pods per node. Given this low Pod density per node, allocating a /24 CIDR block on every Pod is a waste of IP addresses. For a large cluster with many nodes, this waste gets compounded across all the nodes in the cluster. This can greatly exacerbate IP utilization.
With Flexible Pod CIDR functionality, you can define Pod density per Node and thereby use fewer IP blocks per node. This setting is available on a per Node-pool basis, so that if tomorrow the Pod density changes, then you can simply create a new Node pool and define a higher Pod density. This can either help you fit more Nodes for a given Pod CIDR range, or allocate a smaller CIDR range for the same number of Nodes, thus optimizing the IP address space utilization in the overall network for GKE clusters.
The Flexible Pod CIDR feature helps to make GKE cluster size more fungible and is frequently used in three situations:
For hybrid Kubernetes deployments, you can avoid assigning a large CIDR block to a cluster, since that increases the likelihood of overlap with your on-prem IP address management. The default sizing can also cause IP exhaustion.
To mitigate IP exhaustion - If you have a small cluster, you can use this feature to map your cluster size to the scale of your Pods and therefore preserve IPs.
For flexibility in controlling cluster sizes: You can tune your cluster size of your deployments by using a combination of container address range and flexible CIDR blocks. Flexible CIDR blocks give you two parameters to control cluster size: you can continue to use your container address range space, thus preserving your IPs, while at the same time increasing your cluster size. Alternatively you can reduce the container address range (use a smaller range) and still keep the cluster size the same.
Replenishing IP inventory
Another way to solve IP exhaustion issues is to replenish the IP inventory. For customers who running out of RFC 1918 addresses, you can now use two new types of IP blocks:
Reserved addresses that are not RFC 1918
Privately used Public IPs (PUPIs), currently in beta
Let’s take a closer look.
Non-RFC 1918 reserved addresses
For customers who have an IP shortage, GCP added support for additional reserved CIDR ranges that are outside the RFC 1918 range. From a functionality perspective, these are treated similar to RFC1918 addresses and are exchanged by default over peering. You can deploy these in both private and public clusters. Since these are reserved, they are not advertised over the internet, and when you use such an address, the traffic stays within your cluster and VPC network. The largest block available is a /4 which is a very large block.
Privately used Public IPs (PUPI)
Similar to non-RFC 1918 reserved addresses, with PUPIs, you can use any Public IP, except Google owned Public IPs on GKE. These IPs are not advertised to the internet.
To take an example, imagine you need more IP addresses and you use the following IP range privately A.B.C.0/24. If this range is owned by a Service MiscellaneousPublicAPIservice.com, devices in your routing domain will no longer be able to reach MiscellaneousPublicAPIservice.com and will instead be routed to your Private services that are using those IP addresses.
This is why there are some general guidelines when using PUPIs. PUPIs are given higher priority over real IPs on the internet because they belong within the customer’s VPC and therefore, their traffic doesn’t go outside of the VPC. Thus, when using PUPIs, it’s best to ensure you are selecting IP ranges that you are sure will not be accessed by any internal services.
Also, PUPIs have a special property in that they can be selectively exported and imported over VPC Peering. With this function, a user can have deployment with multiple clusters in different VPCs and reuse the same PUPIs for Pod IPs.
If the clusters need to communicate with each other, then you can create a servicetype loadbalancer with Internal LB annotation. Then only these Services VIPs can be advertised to the peer, allowing you to reuse PUPIs across clusters and at the same time ensuring connectivity between the clusters.
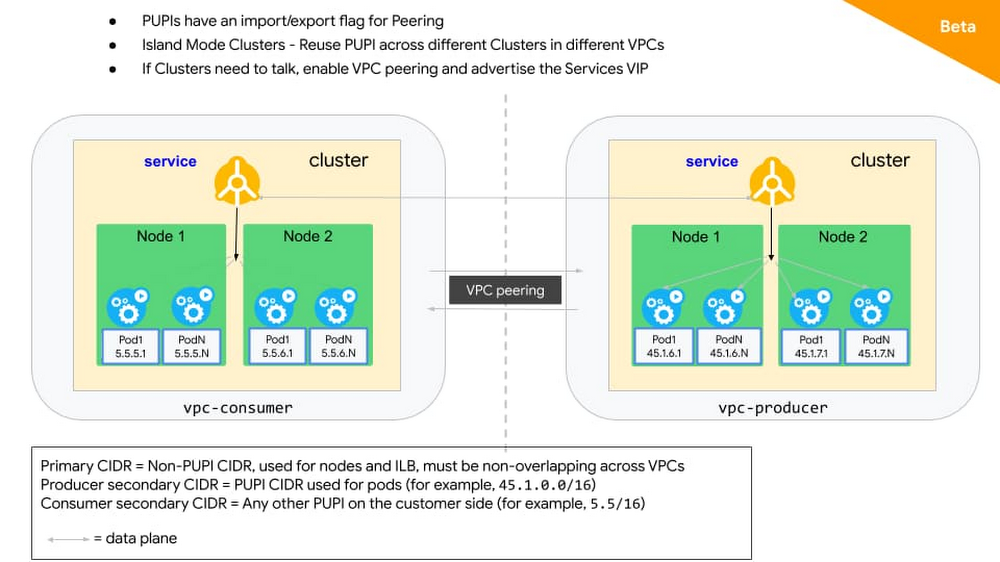
The above works for your environment whether you are running purely on GCP or if you run in a hybrid environment. If you are running a hybrid environment, there are other solutions where you can create islands of clusters in different environments by using overlapping IPs and then use a NAT or proxy solution to connect the different environments.
The IP addresses you need
IP address exhaustion is a hard problem with no easy fixes. But by allowing you to flexibly assign CIDR blocks and replenish your IP inventory, GKE ensures that you have the resources you need to run. For more, check out the documentation on how to create a VPC-native cluster with alias IP ranges, and this solution on GKE address management.
