Elite performance in demand-based downscaling: The power of workload autoscaling
Ameenah Burhan
Solutions Architect
Scaling down your workloads by 4x certainly sounds appealing, doesn't it? The State of Kubernetes Cost Optimization report discovered that elite performers can scale down four times more than their low-performing counterparts. This advantage stems from elite performers tapping into existing autoscaling capabilities more than any other group.
The elite performer group understands that demand-based downscaling relies heavily on workload autoscaling, which requires proper configuration of resources, monitoring, and decision making. According to the report, elite performers leverage Cluster Autoscaler (CA) 1.4x, Horizontal Pod Autoscaler (HPA) 2.3x, and Vertical Pod Autoscaler (VPA) 18x more than low performers.
But enabling one of these is not enough. CA alone cannot make a cluster scale down during off-peak hours. To autoscale a cluster, you need to configure workload autoscaling properly, complete with HPA and VPA. This blog outlines the significance of workload autoscaling and outlines steps that you as a developer or platform admin can follow to harness its benefits.
Step 1: Setting CPU and memory resource requests and limits
Establishing resource requests and limits is critical to ensuring reliability and optimizing workloads for scaling. This was also emphasized in the blog post, Setting resource requests: the key to Kubernetes cost optimization.

To allocate resources appropriately, reconsider how you determine resource requests and limits. Requests should reflect the typical needs of your workload, not just the bare minimum your application can function with. Conversely, view the limit as the necessary resources to sustain your workload during scaling events.
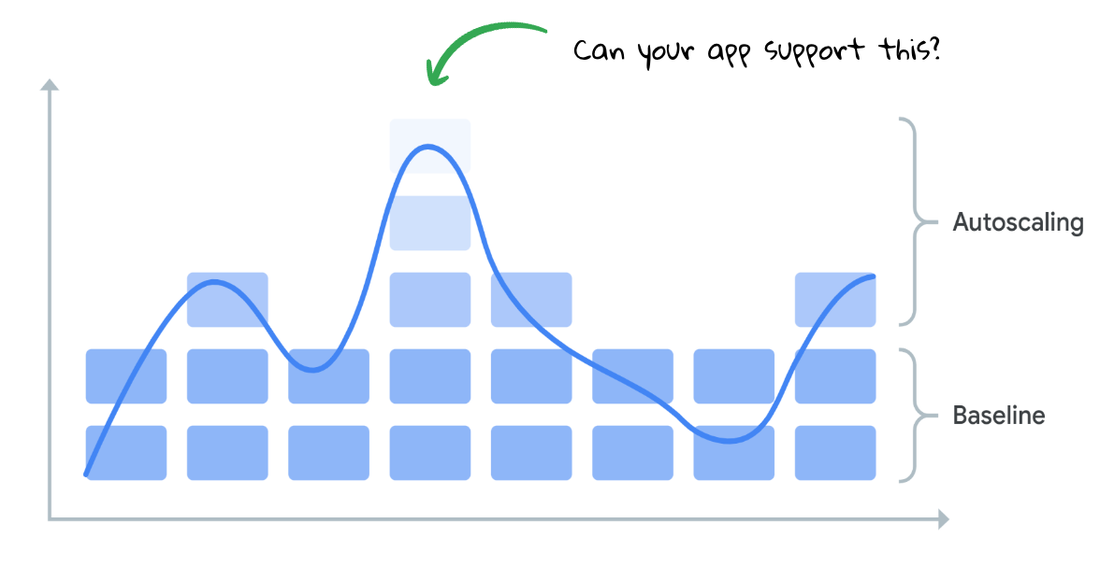
To identify workloads that lack resource requests, consult the GKE Workloads at Risk dashboard. It is essential to set resource requests as they are required for the HPA and CA to provide elasticity in your cluster.
Step 2: Set up Monitoring to view usage
Having determined your resource requests and limits, the next step involves setting up monitoring dashboards to observe metrics for your workloads. The Google Kubernetes Engine (GKE) UI offers observability charts for both cluster and individual workloads. Additionally, Cloud Monitoring lets you view usage metrics and in-built VPA recommendations without deploying VPA objects, a point we'll cover in Step 3. Whether you’re using predefined dashboards or customizing your own, Cloud Monitoring allows for comprehensive dashboard and alert creation.
Step 3: Using recommendations and usage metrics to rightsize workloads
To downscale efficiently, you need to rightsize your clusters properly. By utilizing the monitoring dashboards that were set up earlier, you can accurately determine the optimal resource request values and ensure maximum efficiency for your workloads. For a more in-depth exploration of workload rightsizing, please refer to our previous article, Maximizing reliability, minimizing costs: Right-sizing Kubernetes workloads.
Step 4: Deciding between HPA and VPA for Pod autoscaling
Before choosing a workload scaling strategy, it's essential to understand their purposes. HPA is best when optimizing the number of replicas for the pods' performance, while VPA works great in optimizing resource utilization. HPA ensures enough resources are available to handle the demand even during peak times, while VPA ensures you're not overprovisioning valuable resources to run your application.
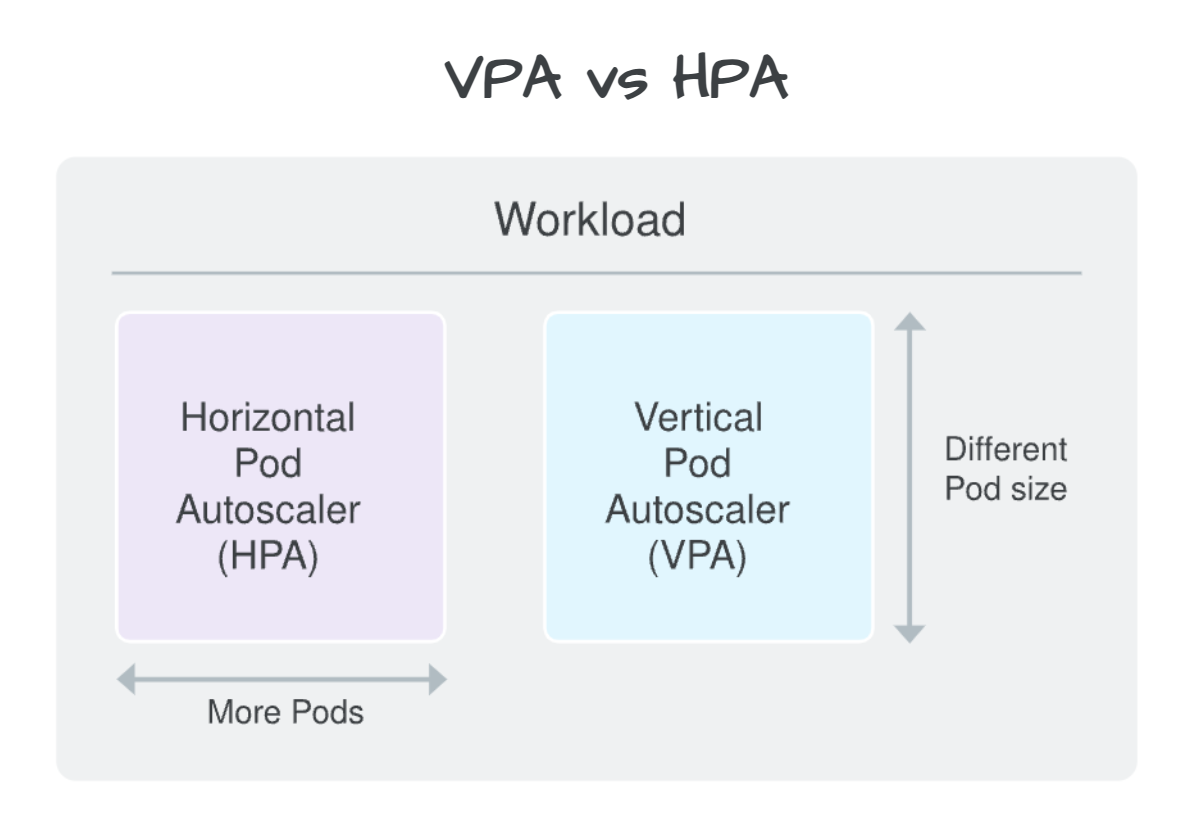
Though it's feasible to combine both HPA and VPA, the general guideline is to avoid it. Such a mix can induce erratic scaling behaviors, potentially leading to application downtime and performance and reliability complications.
Step 5: Enable Cluster Autoscaler
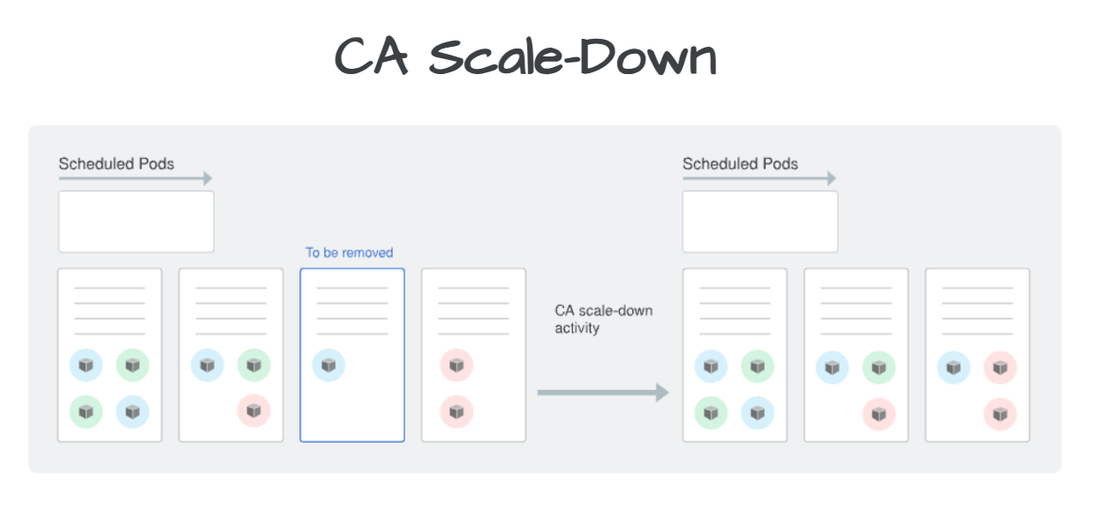
The more workloads you manage to scale down during non-peak periods, the more adeptly CA can eliminate nodes.
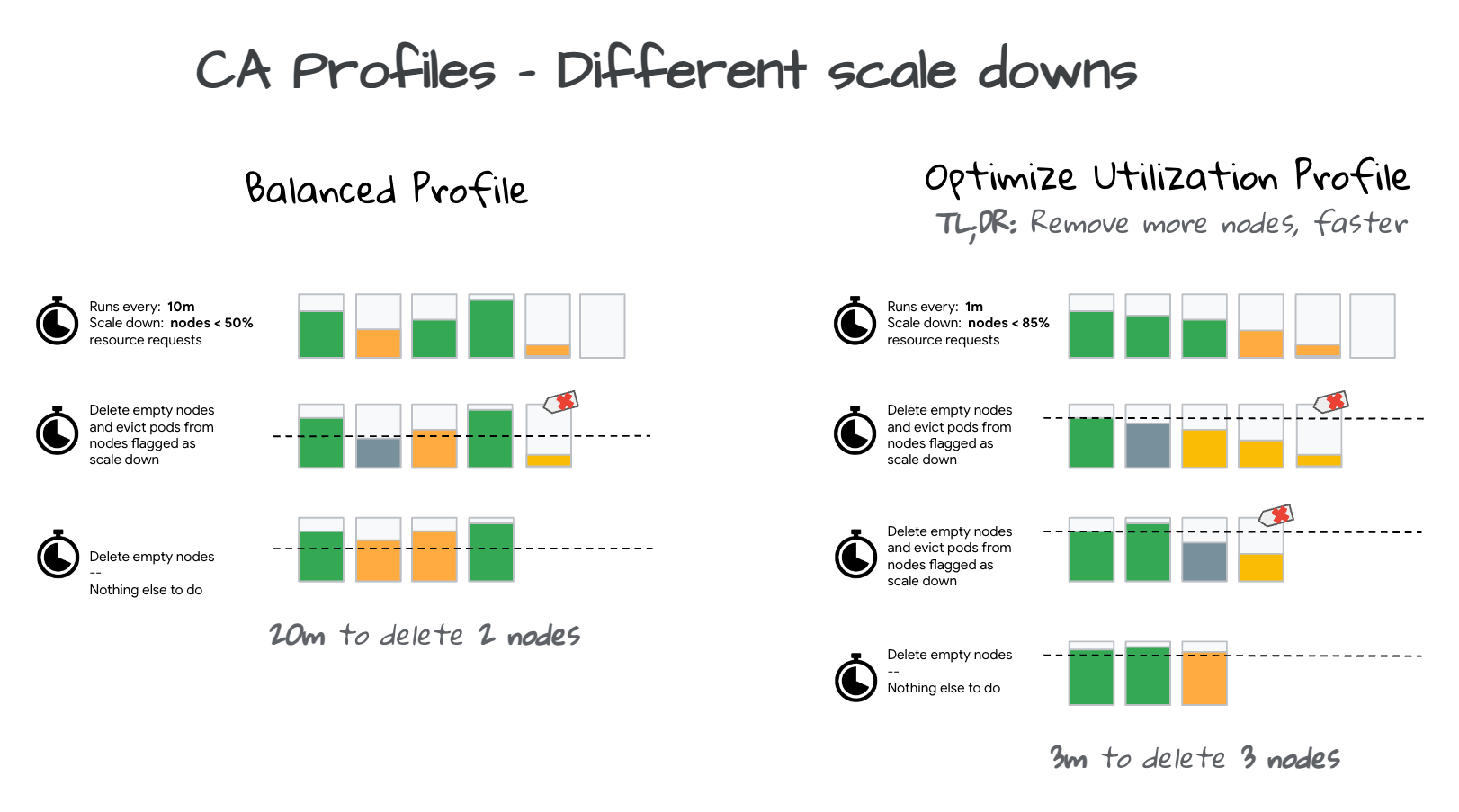
Autoscaling profiles determine when to eliminate a node, balancing between optimizing utilization and ensuring resource availability. While removing underused nodes can enhance cluster efficiency, upcoming workloads may need to pause until resources are reallocated.
You can choose an autoscaling profile that best fits this decision-making process. The available profiles are:
- Balanced: This is the default profile and is a better option when you want your key nodes spread between zones.
- Optimize-utilization: This profile leans towards maximizing utilization at the cost of having fewer spare resources. If you choose this, the cluster autoscaler acts more assertively, removing nodes at a quicker pace and in greater numbers.
For more insights into using CA for cost efficiency, check out Best practices for running cost-optimized Kubernetes applications on GKE.
Step 6: Consider GKE Autopilot
If your aim is to streamline the management of demand-based downscaling, consider transitioning your workloads to GKE Autopilot. Autopilot eases operations by handling the management of the cluster infrastructure, control plane, and nodes. Whether you choose GKE Standard or GKE Autopilot, you'll still be responsible for completing Steps 1 - 4, beginning with setting resource requests. However, with Autopilot managing the node pools on your behalf, you can skip Step 5, thereby simplifying the process.
In conclusion
This article highlights the value of workload autoscaling to facilitate efficient demand-based downscaling. You can undertake various measures, from resource request settings to activating Cluster Autoscaler, to guarantee optimal resource distribution. The steps laid out in this piece serve as a foundation for application developers, budget managers, and platform administrators to maximize workload scaling, diminish expenses, and bolster performance.
Remember, before attempting to scale down your cluster, it’s essential to set appropriate resource requests to avoid compromising your user experience.
Download the State of Kubernetes Cost Optimization report, review the key findings, and stay tuned for our next blog post!
Also, be sure to check out our other blogs based on the State of of Kubernetes Cost Optimization key findings, as well as other resources mentioned in this blog:
- Setting resource requests: the key to Kubernetes cost optimization
- Maximizing reliability, minimizing costs: Right-sizing Kubernetes workloads
- Best practices for running cost-optimized Kubernetes applications on GKE
- The Right-sizing workloads at scale solution guide
- The simple kube-requests-checker tool
- An interactive tutorial to get set up in GKE with a set of sample workloads