Even more pi in the sky: Calculating 100 trillion digits of pi on Google Cloud

Emma Haruka Iwao
Developer Advocate
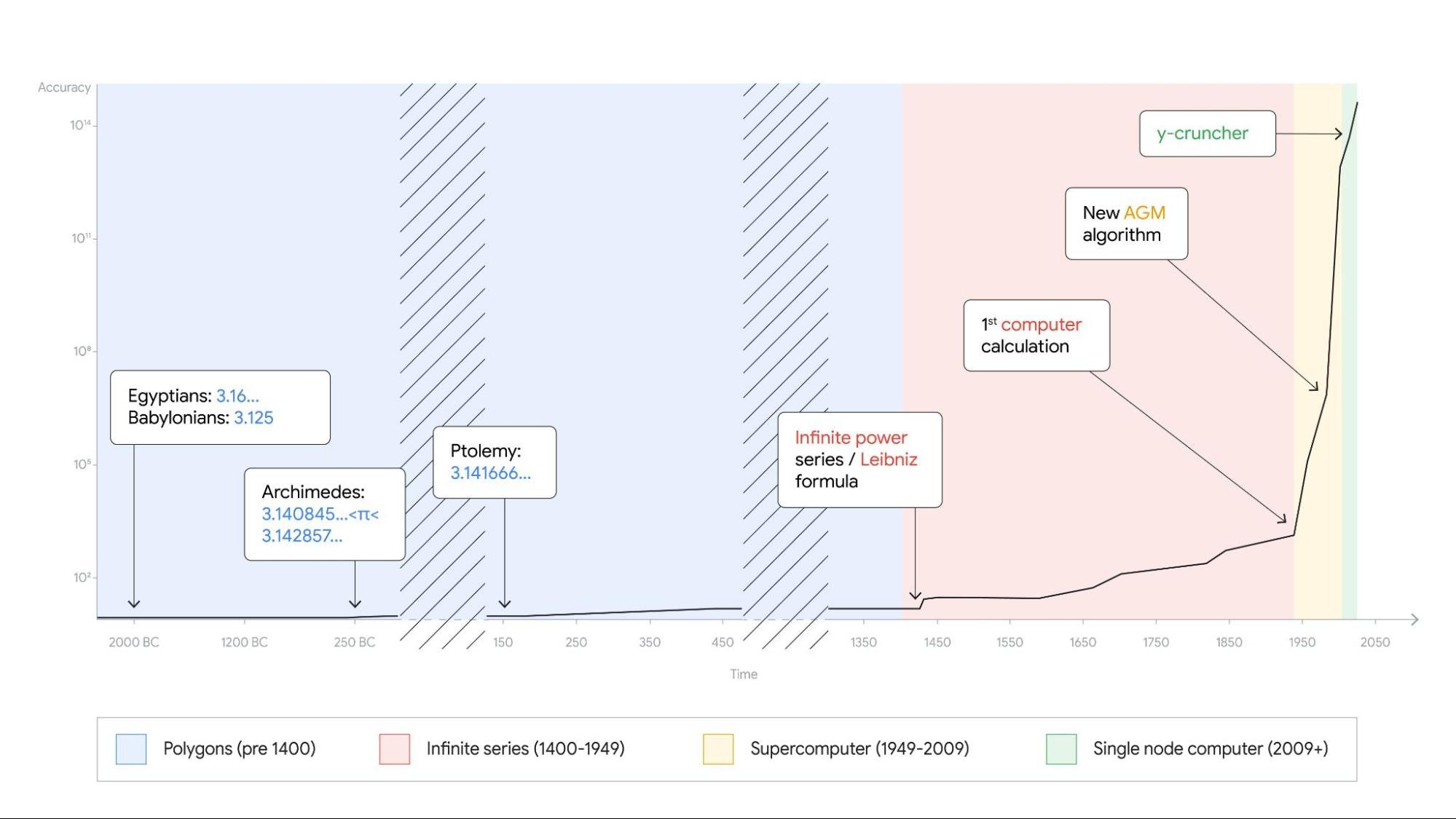
Records are made to be broken. In 2019, we calculated 31.4 trillion digits of π — a world record at the time. Then, in 2021, scientists at the University of Applied Sciences of the Grisons calculated another 31.4 trillion digits of the constant, bringing the total up to 62.8 trillion decimal places. Today we're announcing yet another record: 100 trillion digits of π.
This is the second time we’ve used Google Cloud to calculate a record number1 of digits for the mathematical constant, tripling the number of digits in just three years.
This achievement is a testament to how much faster Google Cloud infrastructure gets, year in, year out. The underlying technology that made this possible is Compute Engine, Google Cloud’s secure and customizable compute service, and its several recent additions and improvements: the Compute Engine N2 machine family, 100 Gbps egress bandwidth, Google Virtual NIC, and balanced Persistent Disks. It's a long list, but we'll explain each feature one by one.
Before we dive into the tech, here’s an overview of the job we ran to calculate our 100 trillion digits of π.
- Program: y-cruncher v0.7.8, by Alexander J. Yee
- Algorithm: Chudnovsky algorithm
- Compute node: n2-highmem-128 with 128 vCPUs and 864 GB RAM
- Start time: Thu Oct 14 04:45:44 2021 UTC
- End time: Mon Mar 21 04:16:52 2022 UTC
- Total elapsed time: 157 days, 23 hours, 31 minutes and 7.651 seconds
- Total storage size: 663 TB available, 515 TB used
- Total I/O: 43.5 PB read, 38.5 PB written, 82 PB total
Architecture overview
Calculating π is compute-, storage-, and network-intensive. Here’s how we configured our Compute Engine environment for the challenge.
For storage, we estimated the size of the temporary storage required for the calculation to be around 554 TB. The maximum persistent disk capacity that you can attach to a single virtual machine is 257 TB, which is often enough for traditional single node applications, but not in this case. We designed a cluster of one computational node and 32 storage nodes, for a total of 64 iSCSI block storage targets.
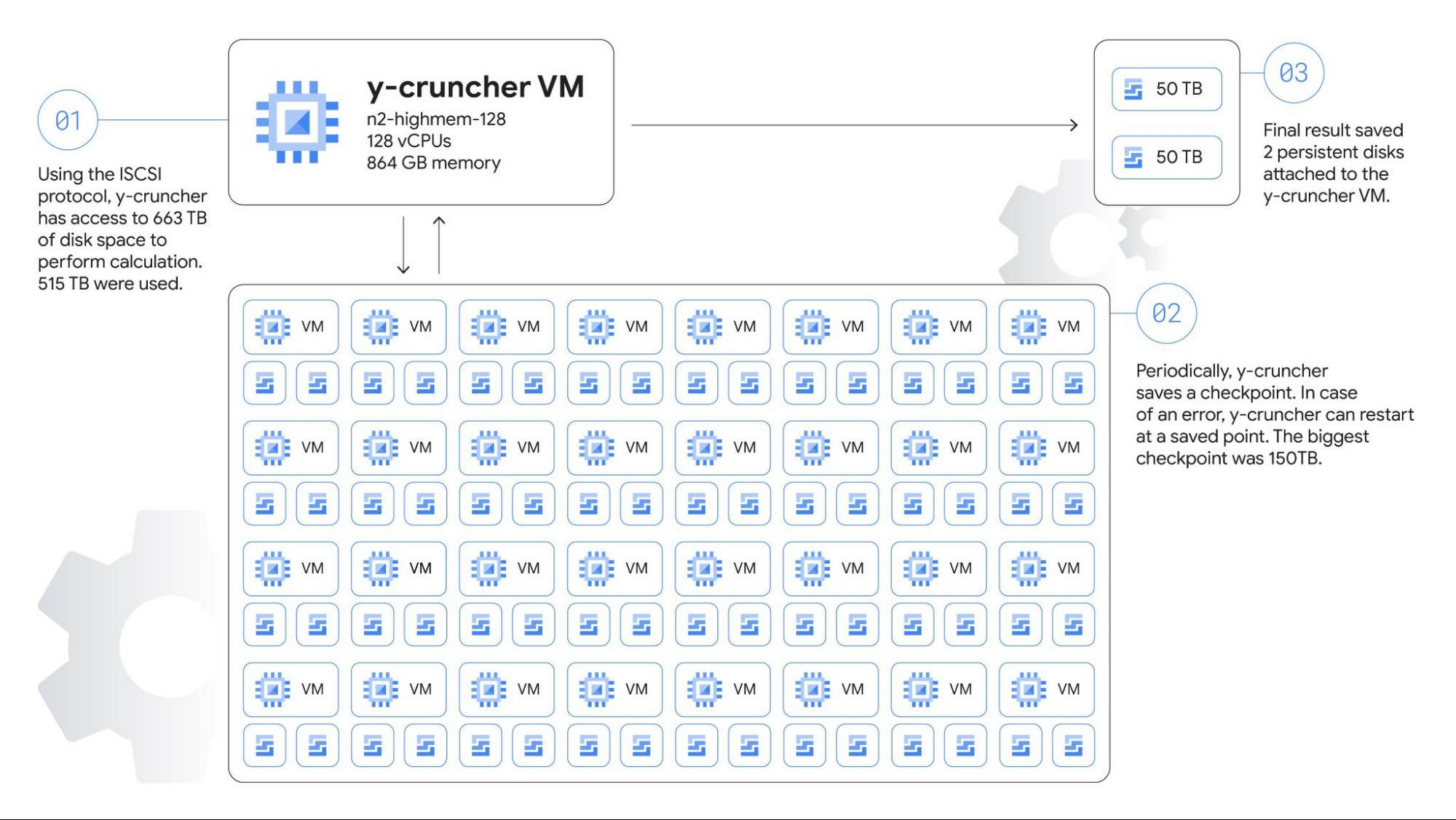
The main compute node is a n2-highmem-128 machine running Debian Linux 11, with 128 vCPUs and 864 GB of memory, and 100 Gbps egress bandwidth support. The higher bandwidth support is a critical requirement for the system as we adopted a network-based shared storage architecture.
Each storage server is a n2-highcpu-16 machine configured with two 10,359 GB zonal balanced persistent disks. The N2 machine series provides balanced price/performance, and when configured with 16 vCPUs it provides a network bandwidth of 32 Gbps, with an option to use the latest Intel Ice Lake CPU platform, which makes it a good choice for high-performance storage servers.
Automating the solution
We used Terraform to set up and manage the cluster. We also wrote a couple of shell scripts to automate critical tasks such as deleting old snapshots, and restarting from snapshots (we didn't need to use this though). The Terraform scripts created OS guest policies to help ensure that the required software packages were automatically installed. Part of the guest OS setup process was handled by startup scripts. In this way, we were able to recreate the entire cluster with just a few commands.
We knew the calculation would run for several months and even a small performance difference could change the runtime by days or possibly weeks. There are also a number of combinations of parameters in the operating system, infrastructure, and application itself. Terraform helped us test dozens of different infrastructure options in a short time. We also developed a small program that runs y-cruncher with different parameters and automated a significant portion of the measurement. Overall, the final design for this calculation was about twice as fast as our first design. In other words, the calculation could’ve taken 300 days instead of 157 days!
The scripts we used are available on GitHub if you want to look at the actual code that we used to calculate the 100 trillion digits.
Choosing the right machine type for the job
Compute Engine offers machine types that support compute- and I/O-intensive workloads. The amount of available memory and network bandwidth were the two most important factors, so we selected n2-highmem-128 (Intel Xeon, 128 vCPUs and 864 GB RAM). It satisfied our requirements: high-performance CPU, large memory, and 100 Gbps egress bandwidth. This VM shape is part of the most popular general purpose VM family in Google Cloud.
100 Gbps networking
The n2-highmem-128 machine type’s support for up to 100 Gbps of egress throughput was also critical. Back in 2019 when we did our 31.4-trillion digit calculation, egress throughput was only 16 Gbps, meaning that bandwidth has increased by 600% in just three years. This increase was a big factor that made this 100-trillion experiment possible, allowing us to move 82.0 PB of data for the calculation, up from 19.1 PB in 2019.
We also changed the network driver from virtio to the new Google Virtual NIC (gVNIC). gVNIC is a new device driver and tightly integrates with Google's Andromeda virtual network stack to help achieve higher throughput and lower latency. It is also a requirement for 100 Gbps egress bandwidth.
Storage design
Our choice of storage was crucial to the success of this cluster – in terms of capacity, performance, reliability, cost and more. Because the dataset doesn't fit into main memory, the speed of the storage system was the bottleneck of the calculation. We needed a robust, durable storage system that could handle petabytes of data without any loss or corruption, while fully utilizing the 100 Gbps bandwidth.
Persistent Disk (PD) is a durable high-performance storage option for Compute Engine virtual machines. For this job we decided to use balanced PD, a new type of persistent disk that offers up to 1,200 MB/s read and write throughput and 15-80k IOPS, for about 60% of the cost of SSD PDs. This storage profile is a sweet spot for y-cruncher, which needs high throughput and medium IOPS.
Using Terraform, we tested different combinations of storage node counts, iSCSI targets per node, machine types, and disk size. From those tests, we determined that 32 nodes and 64 disks would likely achieve the best performance for this particular workload.
We scheduled backups automatically every two days using a shell script that checks the time since the last snapshots, runs the fstrim command to discard all unused blocks, and runs the gcloud compute disks snapshot command to create PD snapshots. The gcloud command returns and y-cruncher resumes calculations after a few seconds while the Compute Engine infrastructure copies the data blocks asynchronously in the background, minimizing downtime for the backups.
To store the final results, we attached two 50 TB disks directly to the compute node. Those disks weren’t used until the very last moment, so we didn't allocate the full capacity until y-cruncher reached the final steps of the calculation, saving four months worth of storage costs for 100 TB.
Results
All this fine tuning and benchmarking got us to the one-hundred trillionth digit of π — 0. We verified the final numbers with another algorithm (Bailey–Borwein–Plouffe formula) when the calculation was completed. This verification was the scariest moment of the entire process because there is no sure way of knowing whether or not the calculation was successful until it finished, five months after it began. Happily, the Bailey-Borwein-Plouffe formula found that our results were valid. Woo-hoo! Here are the last 100 digits of the result:You can also access the entire sequence of numbers on our demo site.
So what?
You may not need to calculate trillions of decimals of π, but this massive calculation demonstrates how Google Cloud’s flexible infrastructure lets teams around the world push the boundaries of scientific experimentation. It's also an example of the reliability of our products – the program ran for more than five months without node failures, and handled every bit in the 82 PB of disk I/O correctly. The improvements to our infrastructure and products over the last three years made this calculation possible.
Running this calculation was great fun, and we hope that this blog post has given you some ideas about how to use Google Cloud's scalable compute, networking, and storage infrastructure for your own high performance computing workloads. To get started, we've created a codelab where you can create and calculate pi on a Compute Engine virtual machine with step-by-step instructions. And for more on the history of calculating pi, check out this post on The Keyword. Here’s to breaking the next record!
We will be hosting a live webinar on June 15 to share more about the experimentation process and results. Sign-up here to join.
To learn more about Google Cloud Infrastructure, please Join us July 13 at 9am PST for the first ever Infrastructure Spotlight. Engineers from Snap and Broadcom will join Google leaders to discuss how Google Cloud Infrastructure helps them be more efficient and scale. Register here.
1. We are actively working with Guinness World Records to secure their official validation of this feat as a "World Record", but we couldn’t wait to share it with the world. This record has been reviewed and validated by Alexander J. Yee, the author of y-cruncher.

